-
elasticsearch v7.6.0
-
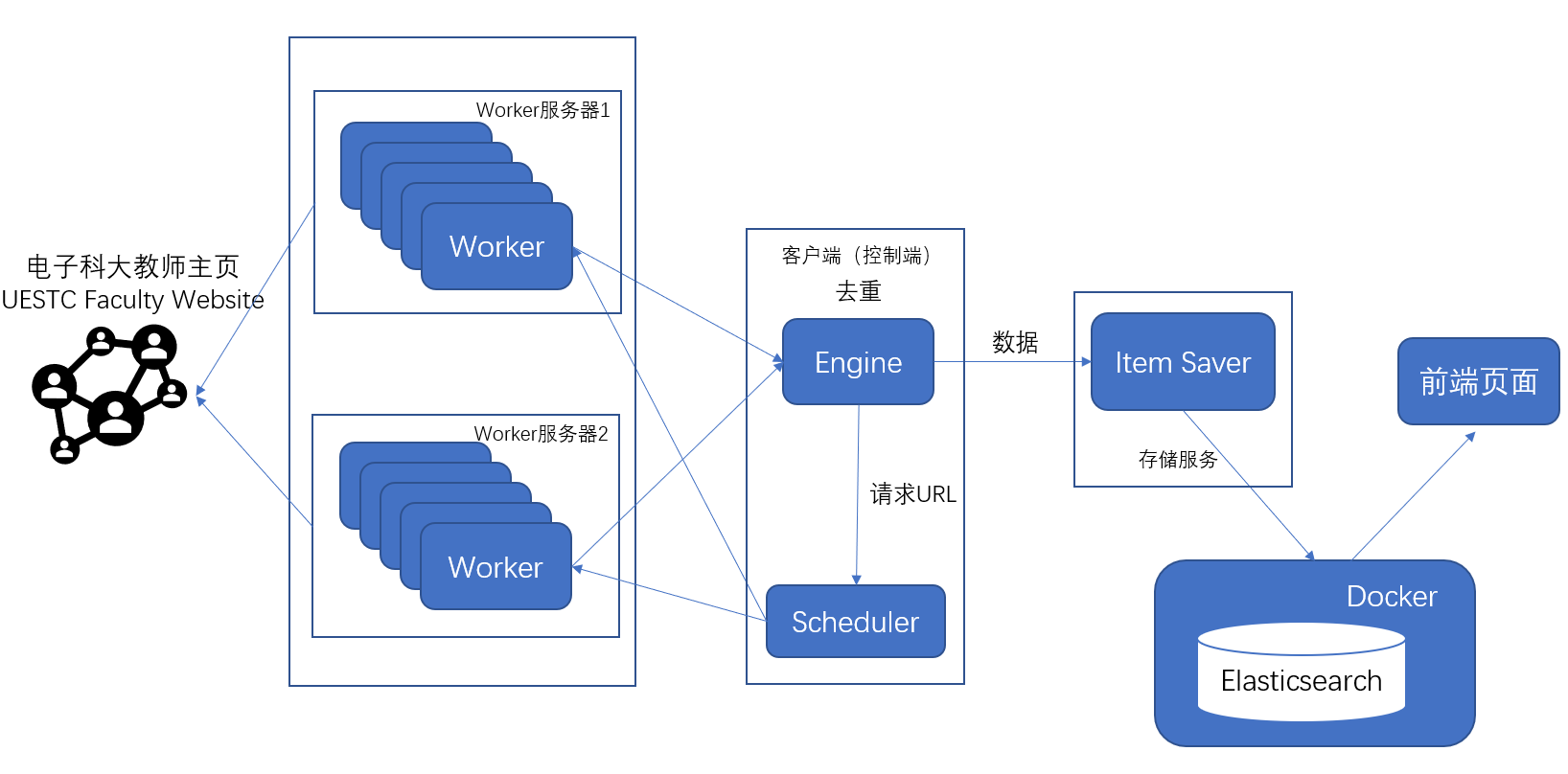
运行Worker的服务器上可以有多个Worker goroutine,也就是多个Worker协程同时运行
-
Worker的主要工作就是:
- 通过URL请求页面
- 解析页面内容--数据结构化
- 将数据和解析得到的URL送Engine
- 将Worker发送过来的数据送Item Saver储存
- 分析请求URL,防止重复
- 通过队列,将下一个请求发送给Worker
- 接收数据,通过Elasticsearch的REST接口存储数据
运行前,设置go modules代理,下载所有modules(go version 1.13+)
$ go env -w GO111MODULE=on
$ go env -w GOPROXY=https://goproxy.cn,direct
$ go mod download| 角色 | 命令 | 监听端口 |
|---|---|---|
| Worker 1 | go run .\distributed\worker\server\worker.go --port=9000 |
9000 |
| Worker 2 | go run .\distributed\worker\server\worker.go --port=9001 |
9001 |
| Worker ... | ... | ... |
| Item Saver | go run .\distributed\persist\server\itemsaver.go --port=1234 |
1234 |
| Client(Control) | go run .\distributed\main.go --saver-host=":1234" --worker-hosts=":9000,:9001" |
/ |
| 数据展示 | go run .\concurrent\front\starter.go |
8000 |
课程地址imooc 该项目由课程实战项目修改而成