Cleanup and fix bugs #22
Conversation
The old one had some edge cases around multiple delimiters (`trim_left_matches` trimming over-aggressively), and I found it harder to follow. We now construct and check a simpler and more explicit pair of invariants: - The join of the (Same, Rem) diff elements should produce exactly the "old" text. - The join of the (Same, Add) diff elements should produce exactly the "new" text.
Use the [standard dynamic-programming LCS algorithm][0]. This is shorter than the previous version, and passes a minimized version of the johannhof#19 test. [0]: https://en.wikipedia.org/wiki/Longest_common_subsequence_problem#Code_for_the_dynamic_programming_solution
Simplify and reduce duplication, and in the process fix an empty-line test case (ala johannhof#17)
These now pass.
|
I can't seem to figure out how to placate clippy -- it complains about an unused import of difference in |
| for i in 0..N { | ||
| for j in 0..M { | ||
| if b[j] == a[i] { | ||
| if i == 0 || j == 0 { |
There was a problem hiding this comment.
There's a bunch of explicit edge-case handling here in order to avoid needing an (N+1)*(M+1)-sized array; If you're willing to allocate a buffer row/column of zero values, a bunch of these can go away. Since we're allocating regardless, it might be worth eating the slight memory increase for a substantial code simplification.
This prevents an error about an used import.
|
I think I am experiencing one or more of these bugs. |
|
Here's a little test I added to the code in this PR, and it fails: #[test]
fn test_diff_brief() {
let text1 = "Hello\nworld";
let text2 = "Ola\nmundo";
let changeset = Changeset::new(text1, text2, "\n");
//assert_eq!(changeset.distance, 4);
assert_eq!(
changeset.diffs,
vec![
Difference::Same("".to_string()),
Difference::Rem("Hello".to_string()),
Difference::Add("Ola".to_string()),
Difference::Rem("world".to_string()),
Difference::Add("mundo".to_string()),
]
);
}Do you agree it should pass? I can try to fix it myself if so. |
|
I changed the test and added a bunch more tests, and I fixed a minor bug in the merge function in a pull-request to this pull-request :) This crate was extremely under-tested. I hope it now covers most cases in simple tests (not sure what cases the quickcheck test was supposed to be covering, but anyway, given the many bugs this PR fixes, seems like that was not enough). |
|
can we land these fixes soon - or do a fork? I'm the author of pretty-assertions and I am experiencing these issues downstream too. When this PR first appeared I was just working on these bugfixes myself. I have yet another lcs implementation ready and I am seriously thinking about cutting the dependency to difference.rs and just implementing my lcs version directly in pretty-assertions. |
- this blocks issue #12 - PR johannhof/difference.rs/pull/22 will fix this
- this blocks issue #12 - PR johannhof/difference.rs/pull/22 will fix this
|
Thanks for the votes of support. @johannhof, if you don't have the time to maintain difference.rs, I'd be happy to join as a co-maintainer or take on ownership of the crate, if you're looking for help. I suspect @colin-kiegel or others might be as well. If we continue to get no response, I suspect it'll make sense to fork and start a new crate for diff'ing. I'd be happy to contribute this code or otherwise help out if useful. |
- Add a few test cases - Include a reference for the LCS algorithm
|
I wrote an email to @johannhof, hopefully we can continue with development of this lib in some way or another. But I would like to propose that we modify the algorithm to find diffs. The reason is that, for example, this test fails: #[test]
fn test_diff_very_similar_text_with_same_line_count() {
let text1 = "\
The sky is blue.\n\
Plants are green.\n\
The moon is white.\n\
The night is black.";
let text2 = "\
The sky is green.\n\
Plants are green.\n\
The night is white.\n\
The moon is black.";
let changeset = Changeset::new(text1, text2, "\n");
assert_eq!(
changeset.diffs,
vec![
Difference::Rem("The sky is blue.".to_string()),
Difference::Add("The sky is green.".to_string()),
Difference::Same("Plants are green.".to_string()),
Difference::Rem("The moon is white.".to_string()),
Difference::Add("The night is white.".to_string()),
Difference::Rem("The night is black.".to_string()),
Difference::Add("The moon is black.".to_string()),
]
);
}What we get instead is 2 The fix seems simple enough: just don't do the "merge" of several successive Let me know what you think. |
|
I definitely agree that not merging successive |
|
@renatoathaydes would it be overhead to maintain |
|
@colin-kiegel I had a look. The diff algorithm is just too simple right now. I've written a bunch of tests for this, but it's not working yet... we'll have to modify a little bit the See what I've done so far in this branch if you want to have a look: https://github.com/renatoathaydes/difference.rs/commits/more-tests |
EDIT: But this discussion seems to drift off-topic of the original PR. Maybe we should continue somewhere else? |
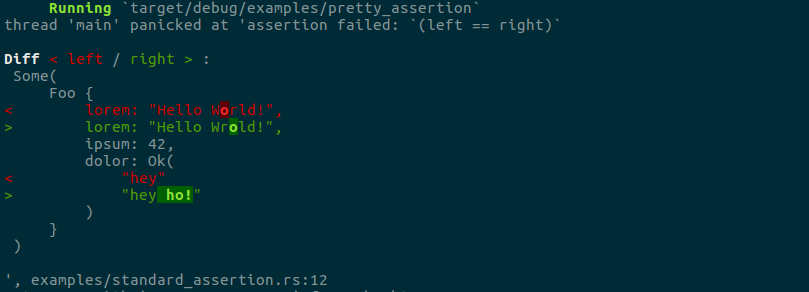
|
@colin-kiegel I will continue trying to "group" the Adds and Removes because that considerably improves the diff. I agree, we should continue somewhere else, and specifically, we should start a new fork given the BTW I also implemented the "nested" diff in my lib I am not a Rust expert and already have too many projects to maintain, so it would be nice if you or @nelhage forked this project and we could make more improvements from there. |
|
Hey folks, I just wanted to say that I've realized I don't have the time and energy to start+maintain a new crate and figure out the API I'd want so on, on my own right now. I'd consider collaborating on such a project if someone else is interested, or anyone is welcome to use my code from this branch if it's helpful. |
|
Hey folks, sorry for the delay on this. As you might have guessed, I've been a bit busy working on other things. I'll give @nelhage and @renatoathaydes full commit rights on this repo. The LCS algorithm is an adaption of the one from Myers' paper, which can be found here: http://xmailserver.org/diff2.pdf I'll try to parse the contents of this PR and give my opinion on it, but I don't want to block progress and I trust you to take it in the right direction. |
|
Thanks for the commit right, @johannhof. I'm going to merge this PR now, since I'm pretty confident it maintains the API while fixing bugs. If we want to contemplate further changes to the API (not merging ops, ensuring ordering properties on ops), let's pursue that work in new PRs and/or issues. |
|
@nelhage cool, I will start targeting this repo with my new pull requests (even though I got commit rights, I will not use it unless no one else wants to maintain this project and I actually get the time to do that). @johannhof thanks for the clarification. I will take some time to read this paper and see if I can make my tests pass and still keep the general algorithm, so that the resulting diff is more natural. |
This branch substantially rewrites
lcsandmergeto be shorter and simpler, and in the process fixes a number of bugs:lcs)Changeset::newignores difference in blank lines #17 (this bug was inmerge)lcs,merge, andcheck_changeset)Sorry for the invasive PR, but this was the best way I could find to fix these bugs.