Los analistas de datos a menudo trabajan con conjuntos de datos muy grandes. Por ejemplo, algunos data warehouses pueden contener varios petabytes de datos y los datalakes pueden ser incluso más grandes. Este lab aborda el aspecto de volumen de los problemas de big data (Volumen, Variedad, Velocidad, Veracidad y Valor).
Amazon Redshift está diseñado para manejar conjuntos de datos extremadamente grandes. A diferencia de los sistemas de administración de bases de datos relacionales tradicionales, Redshift utiliza almacenamiento de datos columnar mejorando el rendimiento de las consultas y ahorrando en costos de almacenamiento. Información adicional sobre la arquitectura de Redshift aquí.
- Acceder a Redshift en la consola de administración de AWS
- Crear un clúster de Redshift
- Cargar datos de S3 en Redshift
- Consultar datos en Redshift
- Un bucket con este archivo
.csv - El archivo
.csvdebe estar dentro de un directório cualquiera en el bucket y no en la raíz del mismo (por ejemplodata):
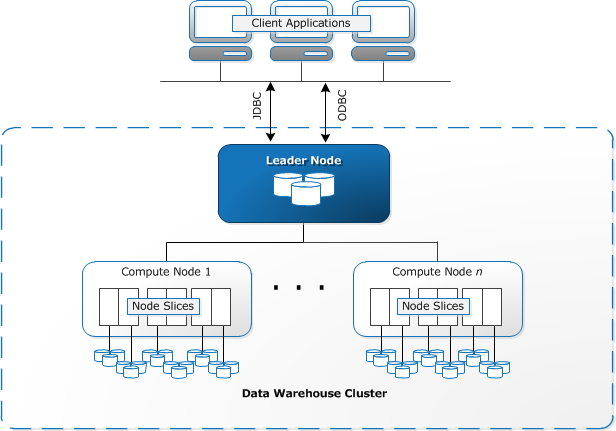
Los clusters son el principal componente de infraestructura de un data warehouse de Redshift. Un clúster se compone de uno o más nodos de cómputo. Si hay más de un nodo, uno de los nodos será el nodo líder y los otros nodos serán nodos de cálculo. Las aplicaciones cliente interactúan con el nodo líder. El siguiente diagrama ilustra la infraestructura general de Amazon Redshift:
-
Acceder al servicio Redshift:
-
Crear un nuevo clúster:

-
Escoger un nombre para el clúster,
dc2.largecomo flavor y 2 nodos como tamaño: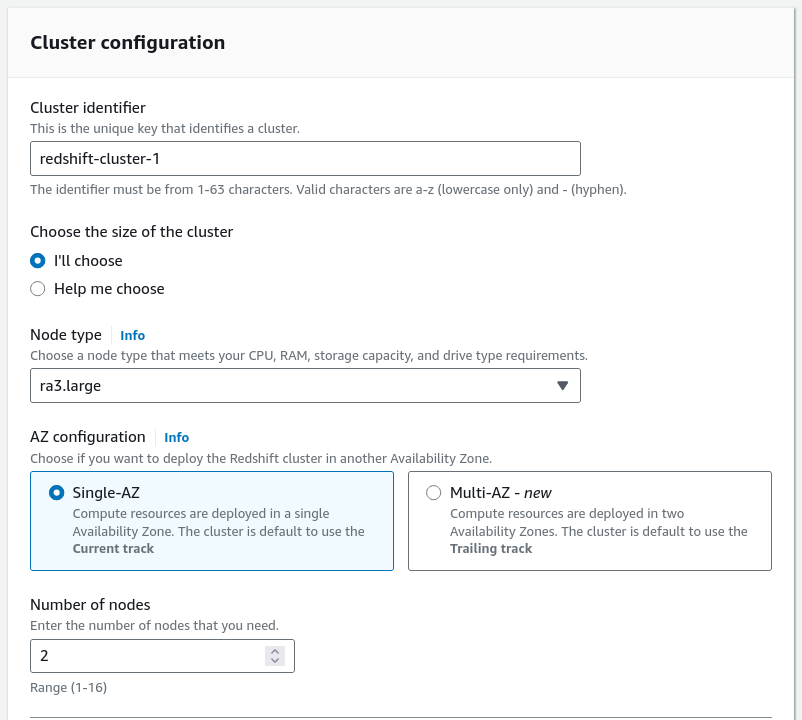
-
Escoger una contraseña para el banco de datos:
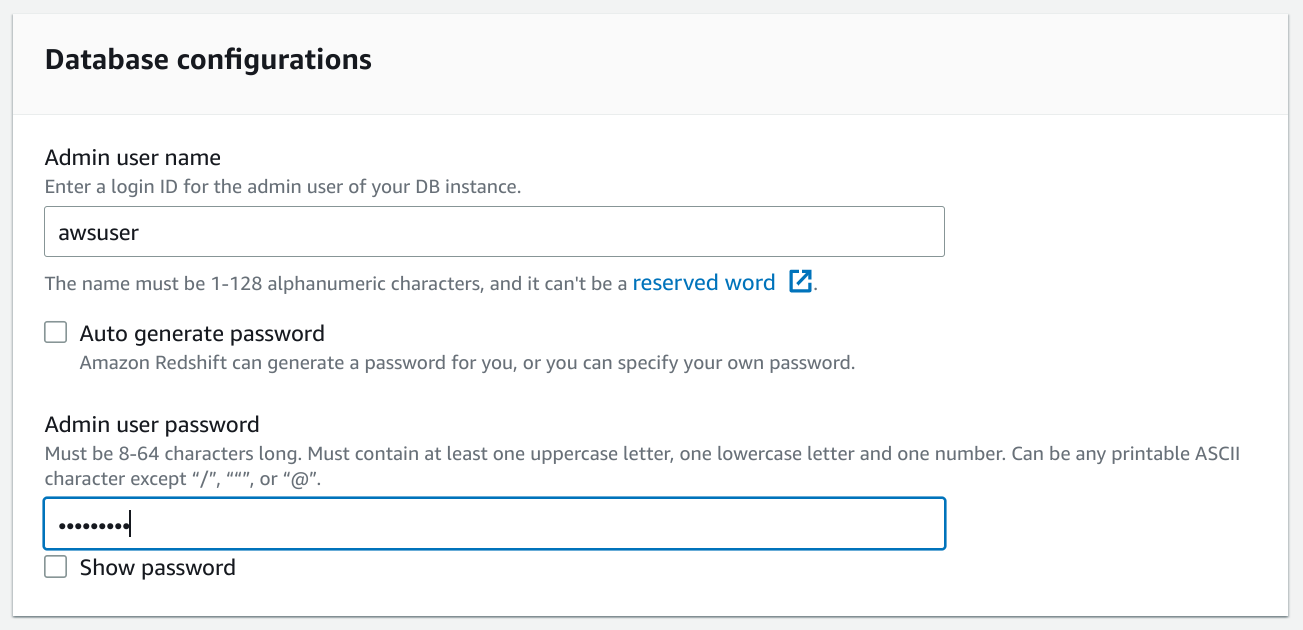
-
Definir
LabRolecomo IAM role. Estos permisos son creados de forma automática por el ambiente AWS Academy: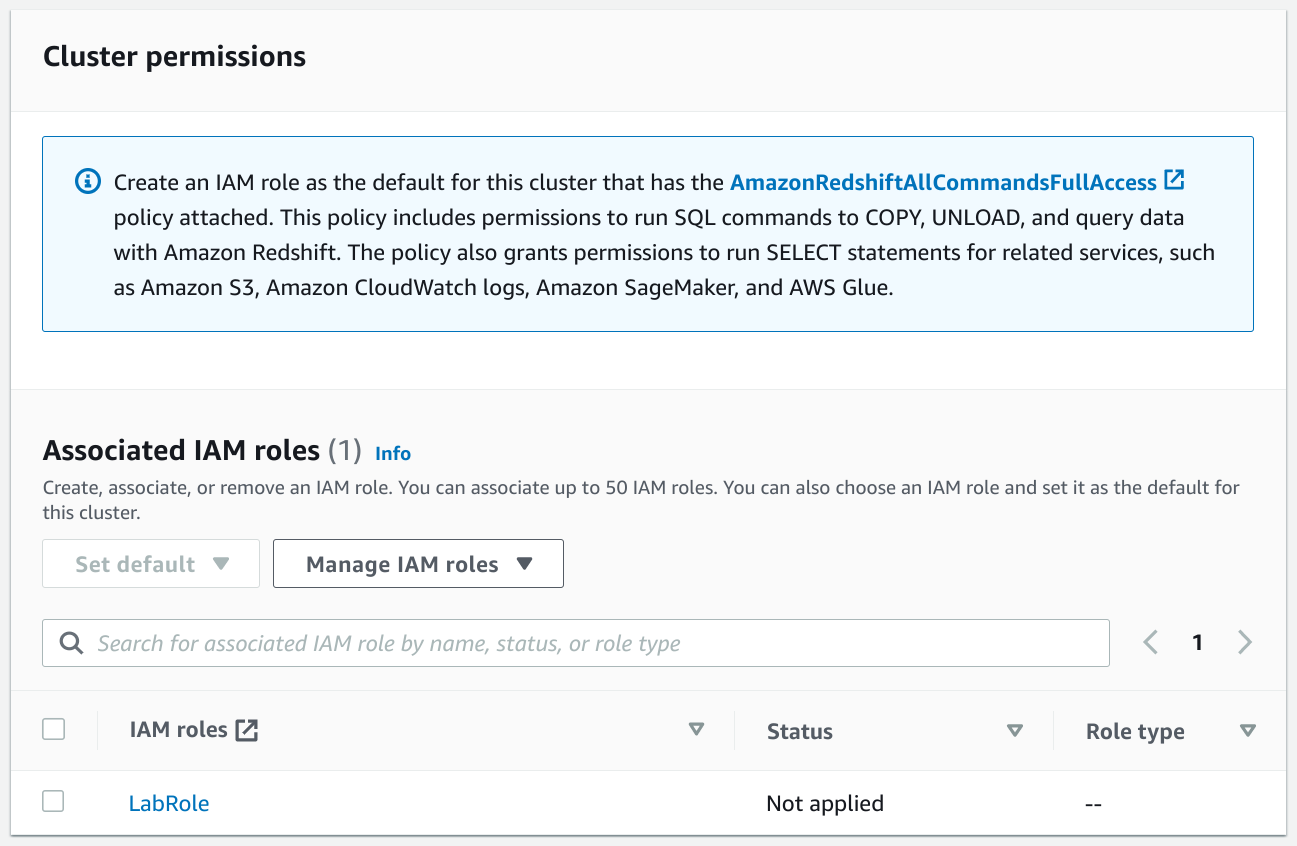
-
Confirmar la creación del clúster y esperar a que se encuentre disponible:

-
Escoger la opción Query data -> Query in query editor:
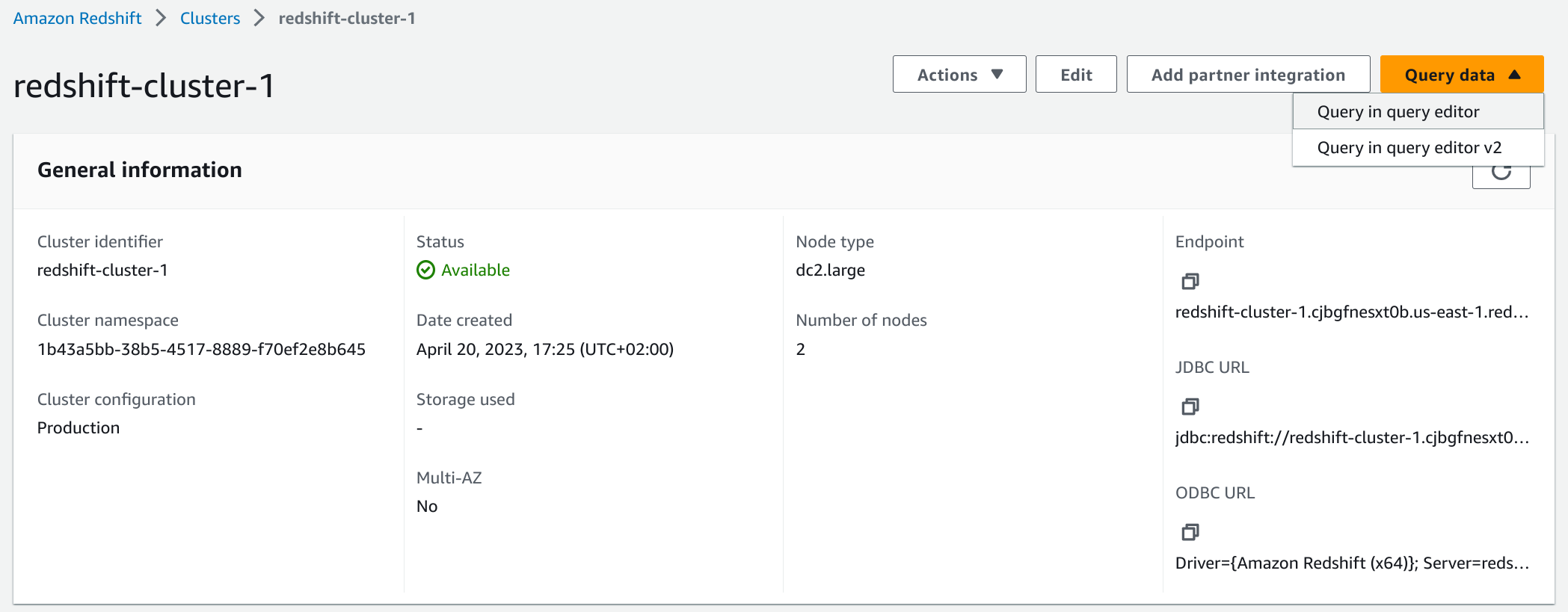
-
Conectar al banco de datos recién creado:

-
Ejecutar la siguiente query para crear una tabla
american_customerscon el esquema adecuado:CREATE TABLE american_customers ( customerID int, first_name varchar(10), last_name varchar(10), join_date varchar(10), street_address varchar(30), city varchar(10), state varchar(2), phone varchar(12) )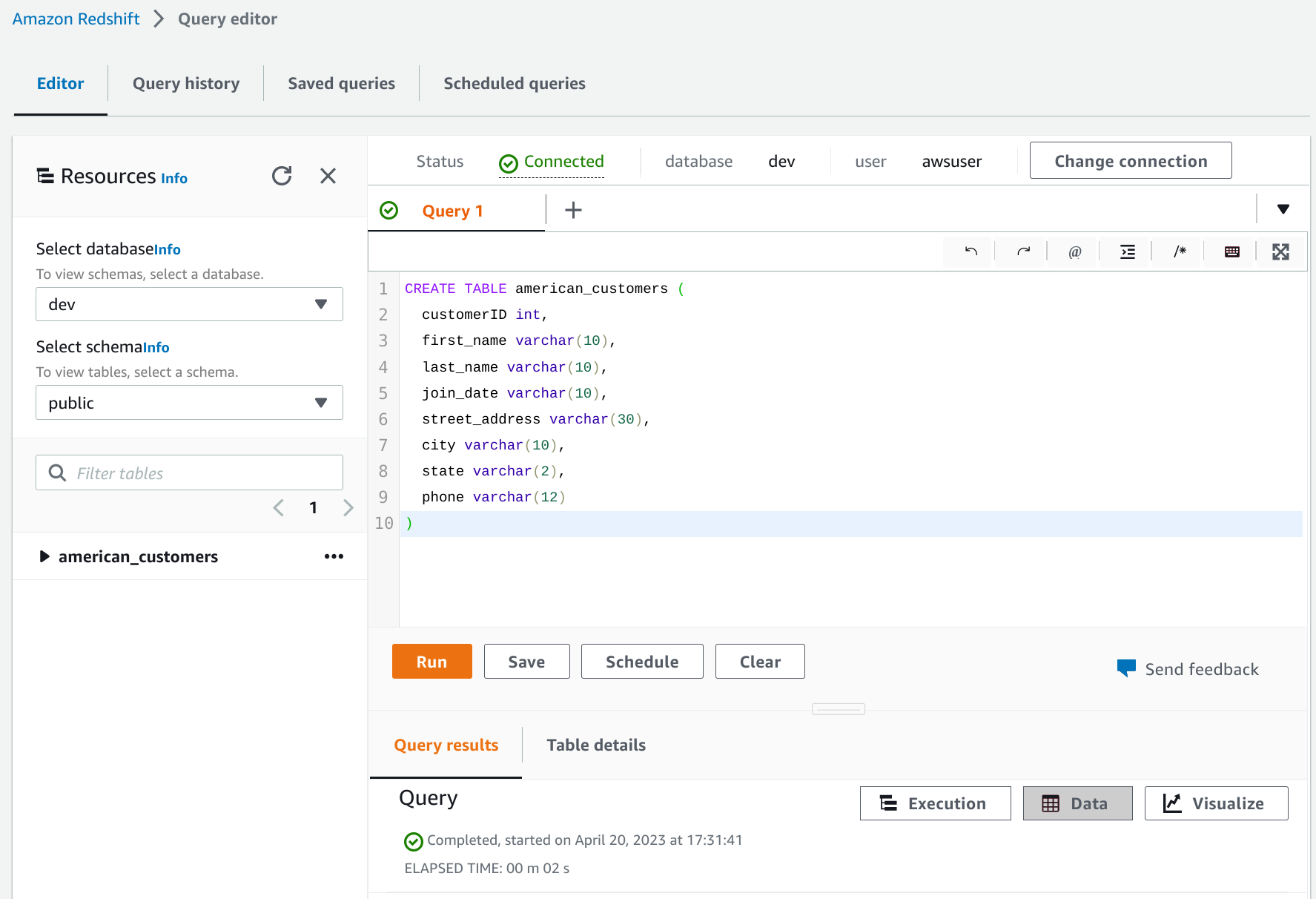
-
Para acceder a los datos de S3 desde Redshift necesitamos el Amazon Resource Name (ARN) de el IAM role
LabRole(estos permisos son creados de forma automática por el ambiente AWS Academy). En una nueva pestaña del navegador, copiar el ARN correspondiente: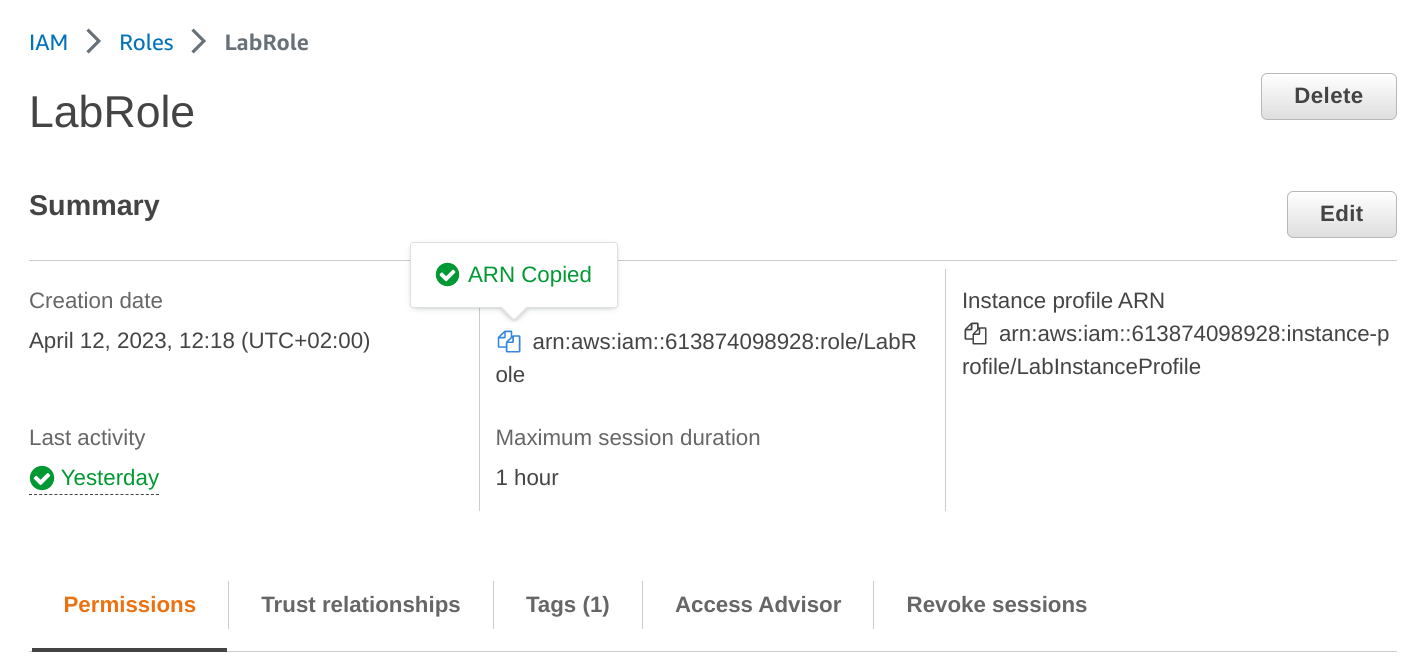
-
Ejecutar la siguiente query para importar los datos de S3 en la tabla
american_customers:COPY american_customers FROM 's3://iffe-mbd/data/lab1.csv' credentials 'aws_iam_role=<iam-role-arn>' IGNOREHEADER 1 CSV
-
Ejecutar un preview de la tabla para confirmar que los datos fueron correctamente importados:
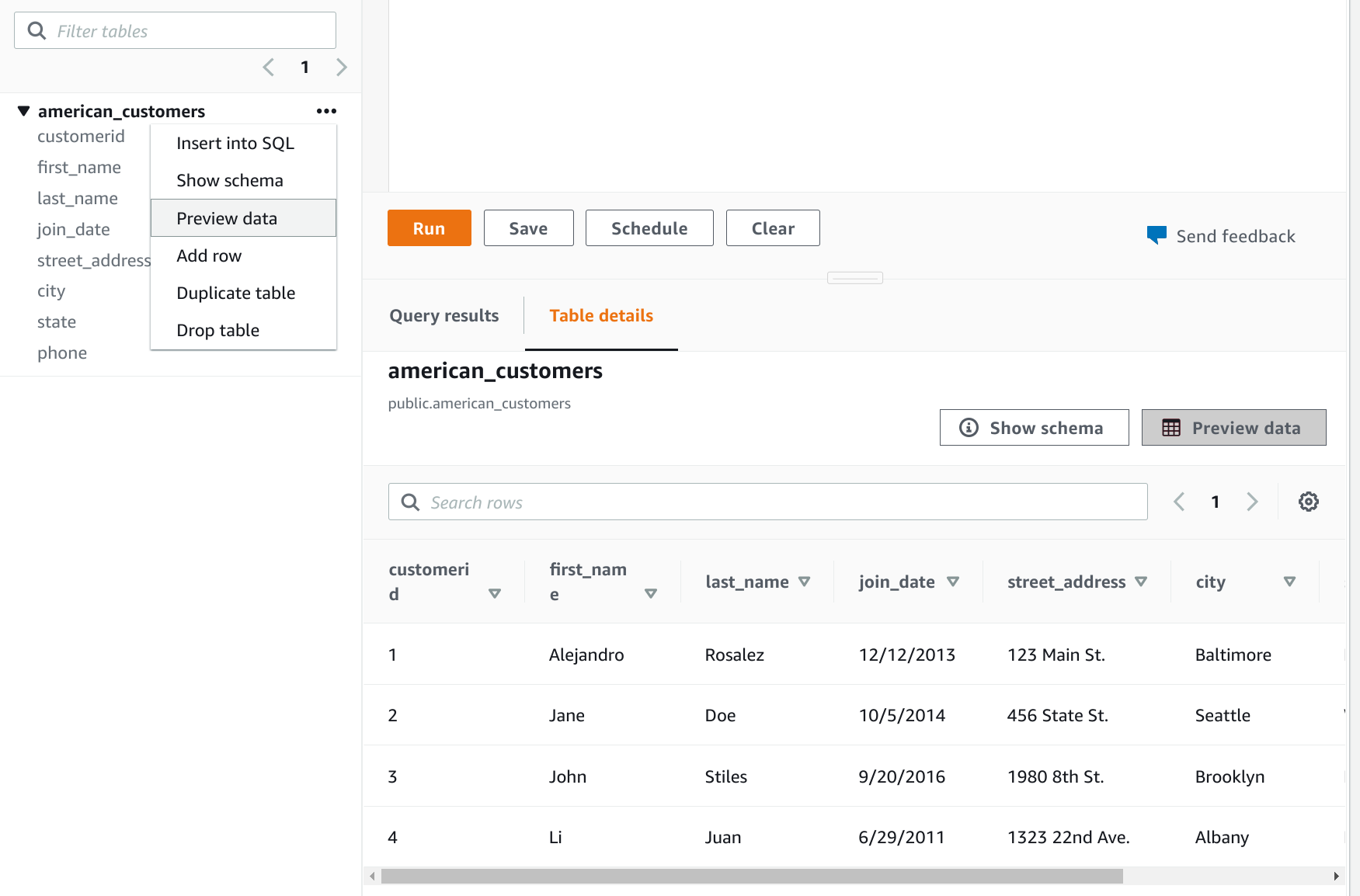
- Crear una nueva tabla
american_customers_normconvirtiendojoin_datede tipo de datovarcharadate - Número de clientes registrados desde 2014
- Borrar el clúster