{kind=link}
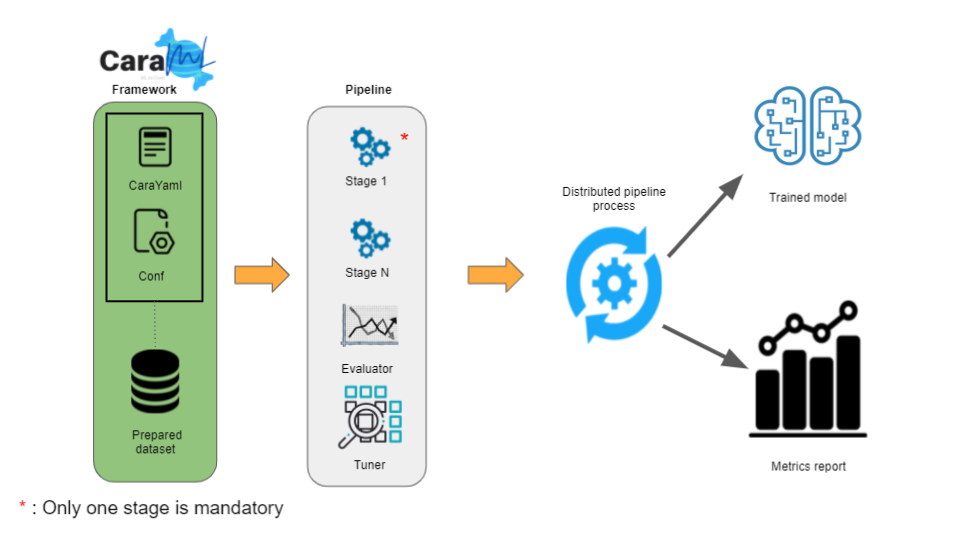
CaraML is a Scala/Apache Spark framework for distributed Machine Learning programs, using the Apache Spark MLlib in the simplest possible way. No need to write hundreds or thousands code lines, just discribing pipline of models and/or transformations. The purpose is to do "Machine Learning as Code"
To use CaraML framework, you must satisfy the following requirements:
- Scala version >= 2.12.13
- Spark version >= 3.1
- Java 11
- Spark : Download here
- Scala : Download here
- CaraML library : CaraML
To use CaraML, you can add the framework dependency in your Spark application
- Sbt
libraryDependencies += "io.github.jsarni" %% "caraml" % "1.0.0"- Gradle
compile group: 'io.github.jsarni"', name: 'caraml', version: '1.0.0'- Maven
<dependency>
<groupId>io.github.jsarni"</groupId>
<artifactId>caraml</artifactId>
<version>1.0.0</version>
</dependency>CaraML needs the following information
- Prepared dataset that will be used to transform and train models
- Path where to save the final trained model and its metrics
- Path of the CaraYaml file, where the user will declare and set the pipeline with stages of SparkML models and/or SparkML transformations
The Yaml file will be used to describe a pipeline of stages, each stage could be a SparkML model or a Spark ML method of data preprocessing. All CaraYaml files must start with "CaraPipeline:" keyword and could contain the following keywords
- "CaraPipeline:" : keyword that must be set in the beginning of each CaraYaml file
- "- stage:" Is a keyword used to declare and describe a stage. It could be an Estimator or a Transformer :
- SparkML Estimator : Which is the name of the SparkML model that you want to use in the stage.
- SparkML Transformer : Is the name of SparkML feature transformation that you want to apply to your dataset (preprocessing)
Each stage will be followed by "params:" keyword, which contain one or many parameters/hyperparameters of the stage and their values.
params:
- "Param1 name" : "Param value"
- "Param2 name" : "Param value"
- ....
- "Paramn name" : "Param value"- "- evaluator:" Which is used to evaluate model output and returns scalar metrics
- "- tuner:" Which is used for tuning ML algorithms that allow users to optimize hyperparameters in algorithms and Pipelines
Each tuner will be followed by "params:" keyword, which contain one or many parameters/hyperparameters of the tuner and their values.
params:
- "Param1 name" : "Param value"
- "Param2 name" : "Param value"
- ....
- "Paramn name" : "Param value"CaraPipeline:
- stage: LogisticRegression
params:
- MaxIter: 5
- RegParam: 0.3
- ElasticNetParam: 0.8
- stage: Tokenizer
params:
- InputCol: Input
- OutputCol: ResCol
- evaluator: MulticlassClassificationEvaluator
- tuner: TrainValidationSplit
params:
- TrainRatio: 0.8
For more details and documentation you can refer to the Spark MLlib documentation
This section lists all available SparkML components that you can use with CaraML framework
-
Classification
- LogisticRegression Spark MLlib example and Documontation
- DecisionTreeClassifier Spark MLlib example and Documontation
- GBTClassifier (Gradient-boosted tree classifier) Spark MLlib example and Documontation
- NaiveBayes Spark MLlib example and Documontation
- RandomForestClassifier Spark MLlib example and Documontation
-
Regression
- LinearRegression Spark MLlib example and Documontation
- DecisionTreeRegressor Spark MLlib example and Documontation
- RandomForestRegressor Spark MLlib example and Documontation
- GBTRegressor (Gradient-boosted tree Regressor) Spark MLlib example and Documontation
-
Clustering
- K-means Spark MLlib example and Documontation
- LDA (Latent Dirichlet allocation) Spark MLlib example and Documontation
- Binarizer Spark MLlib example and Documontation
- BucketedRandomProjectionLSH Spark MLlib example and Documontation
- Bucketizer Spark MLlib example and Documontation
- ChiSqSelector Spark MLlib example and Documontation
- CountVectorizer Spark MLlib example and Documontation
- HashingTF Spark MLlib example and Documontation
- IDF Spark MLlib example and Documontation
- RegexTokenizer Spark MLlib example and Documontation
- Tokenizer Spark MLlib example and Documontation
- Word2Vec Spark MLlib example and Documontation
- CrossValidator Spark MLlib example and Documontation
- TrainValidationSplit Spark MLlib example and Documontation
- RegressionEvaluator Documontation
- MulticlassClassificationEvaluator Documontation
For practical example you can refer to this Link, which is a github project that contain a project using the CaraML framework.