To train a Single Generator G which generates diverse images of each domain y corresponding to a given image x.
- Diverse Images: Produces different images every time given a source image and a domain. (Disadvantage of StarGAN)
- Domain: A set of images forming a visually distinctive category. Ex: Gender of a Person
- Style: Unique Appearance of each image. Ex: Hairstyle, Makeup etc.
- Latent Space: A space over which the compressed data is represented in order to remove extraneous information and find fundamental similarities between two datapoints. Understanding Latent Space.
Read More
The Network attemps to generate domain-specific style vectors in the learned style space of each domain and train G to reflect these vectors in the output image
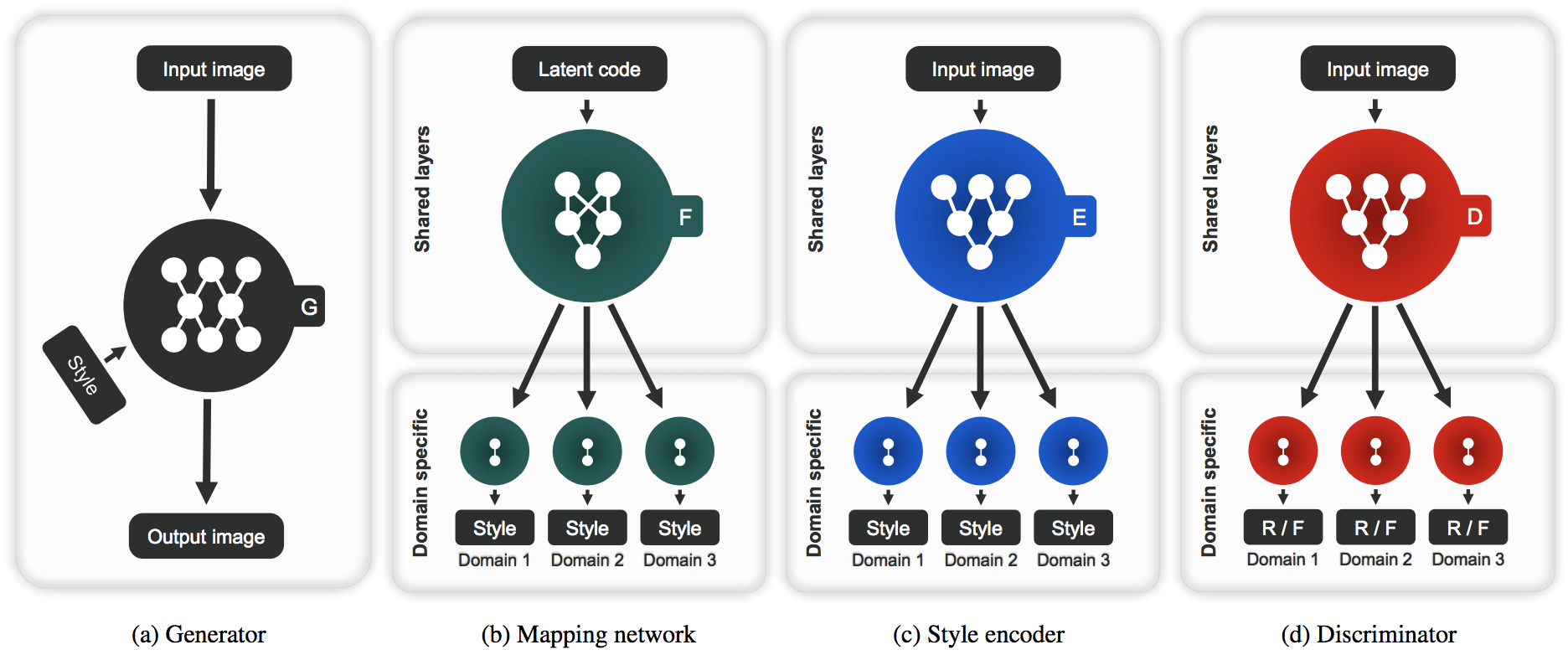
- Generator G: Takes an Input image x and a style code s to generate an output image. The style code removes the need of providing the domain of the image to G allowing it to generate images of all domains. s is designed to represent the style of a specific domain y, which removes the necessity of providing y to G and allowing tit to synthesize images of all domains.
- Mapping Network F: Takes the Domain (y) and Latent Code z (Gaussian Noise) to generate the style code s (which are domain specific). Diverse style codes can be generated by randomly sampling the latent vector z and the domain y rndomly
- Style Encoder E: Takes in an Image x and a domain y to generate the style code s of x.The Style Encoder can produce diffrent style codes using different reference imaages.
- Discriminator D: Consists of multiple output branches with each branch Dy classifying whether or not the image is a real image belonging to Domain y.
- Original Image - x
- Original Domain - y
- Target Domain - ỹ
- Style Code of the Target Domain predicted by the Mapping Network - š
- Style Code of the Original Image predicted by the Style Encoder - ŝ
- Loss - 𝓛
- Adversarial Objective 𝓛adv:
- Sample a latent code z and a domain ỹ randomly. Generate a style code š = Fỹ(z)
- Generate an Output image G(x,s) using the generated style code.
- Learn using Adverserial Loss. While training the Generator, there is no control over the log[Dy(x)]. So the Generator tries to Minimise the expected value of the log(1-Dỹ(G(x,š))) term. We want the discriminator to classify the generated image as real with as high a probability as possible. Since log is a monotonically increasing function, minimising the loss would try and maximise this probability. When training the Discriminator, however, we want to Maximise the loss to maximise Dy(x) since x truly belongs to the domain y
- Style Reconstruction 𝓛sty:
- To Minimise the style Reconstruction loss i.e., to train the Style Encoder to correctly predict the style of the image and to push the Generator towards greater use of the provided style code. The output of the Style Encoder should ideally be ŝ
- Style Diversification 𝓛ds:
- We try to Maximise the difference between images generated using two different style codes š1 and š2 produces using two different latent codes z1 and z2
- Source Characteristics 𝓛cyc:
- We try to Minimise the difference between the original image and the generated output given an image which is generated using x and ŝ and the style code predicted by the Style Encoder i.e., ensure that the generator preserves characteristics of the original image.
- The λ's are hyperparameters
- Frechet Inception Distance - The Fréchet inception distance (FID) is a metric used to assess the quality of images created by the generator of a generative adversarial network (GAN).The FID compares the distribution of generated images with the distribution of real images that were used to train the generator. (Lower FID is better) FID
- Learned Perceptual Image Patch Similarity - A Mesure Of Diversity in generated Images (Higher is Better)
- LAYERS
- NORMALIZATIONS
- Instance Normalization. In Instance Normalization, mean and variance are calculated for each individual channel for each individual sample across both spatial dimensions.
- Adaptive Instance Normalization. "Aligns" the instance-normalized-sample with the given style code.
- ACTIVATIONS
