API call latencies regressed due to upgrade to golang 1.12 #75833
Comments
|
/sig scalability |
|
With @krzysied we are trying to prepare small scale repro that we can use for further debugging. |
|
@krzysied did tests at head with reverting to go1.11 and metrics seemed better |
|
I double checked #74778 and didn't find anything suspicious. The alpha function wasn't invoked in that window, and the PR is a no-op to non-alpha clusters |
|
Regarding what @wojtek-t wrote: I was mostly investigating the regression on kubemark-5000. Some of its latencies increased x3. I run two tests: one with 7514c49 checkout, and the other one with some commit checkout but without 36e934d (Update to use golang 1.12). The 99th latency percentile of node listing was 3400.152ms in first case and f 952.576ms in second one. |
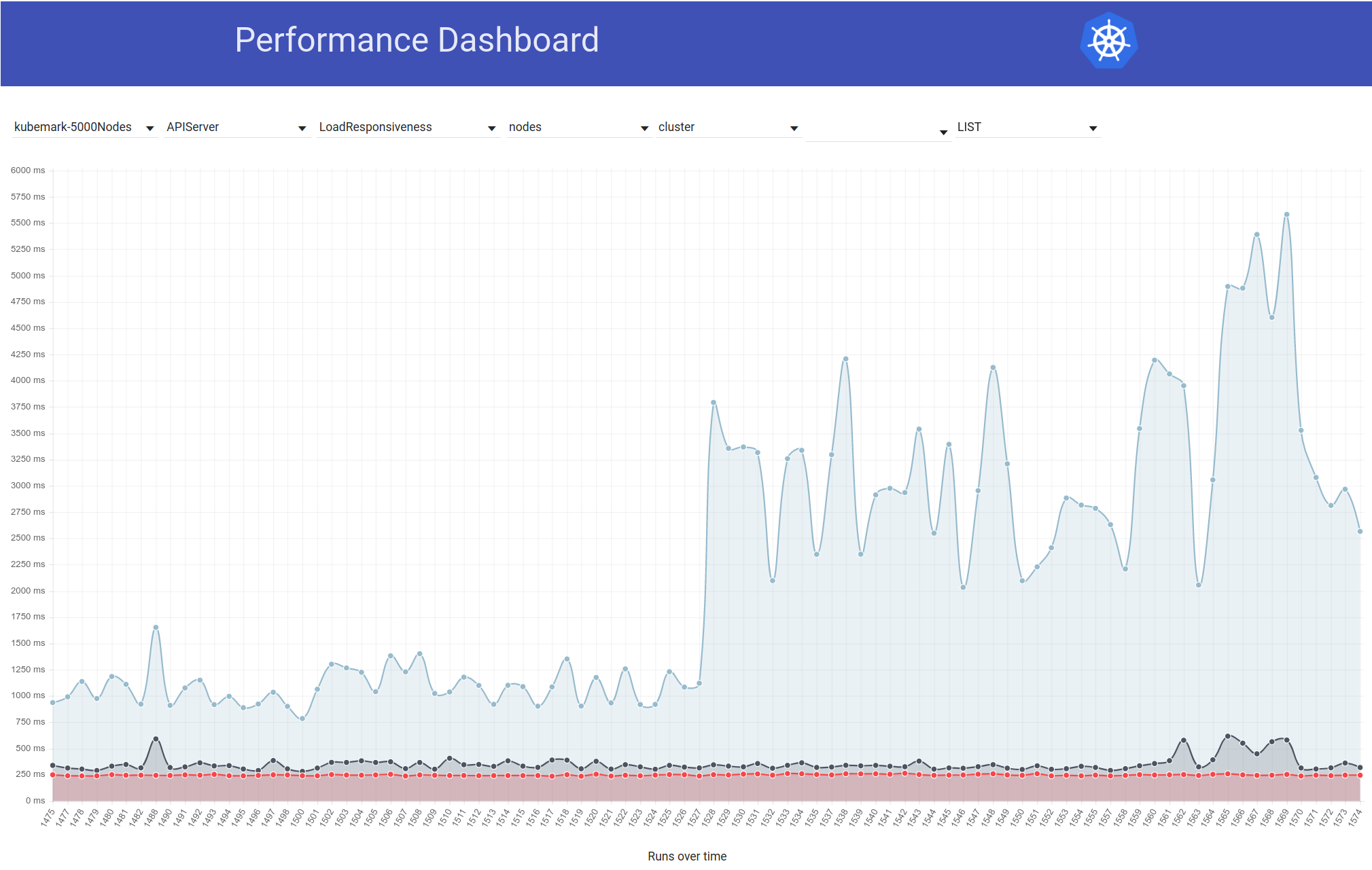
|
Look into other metrics (I can't remember which exactly, delete pods? post pods? or sth like that) - which increased by almost 10x. |
|
This is the graph that I had on my mind, but yeah, it's more like 4x not 10x. But still quite huge drop: |

|
Reproducing the issue:
The test run metrics will be exported to directory provided by the --report-dir flag. Inside this directory there will be APIResponsiveness_load_.txt file containing 50, 90, and 90 percentiles of all apiserver call latencies. The latencies affected the most are:
I would suggest their 99th percentiles as the issue metric. As for comparison:
-Go1.12 run:
|
|
@kubernetes/sig-scalability-bugs |
|
We're trying to dig deeper into it to both root cause it to a smaller part of the system, but it is quite tricky. Some observations:
|
|
We've spent significant time with golang folks and already have some findings.
We aren't fully convinced that this is for sure the same thing that is causing regression in our scalability tests, but analyzing traces, profiles, golang tracesetc. suggests that problems are indeed around memory allocations or GC. So with high probabilty this is the same thing. We are discussing with the way to prove it's the first thing and working with the to see what we can do with it. |
|
It appeared that the commit 07e738ec32025da458cdf968e4f991972471e6e9 isn't the most faulty one for us - running scalability tests against that commit doesn't show significant drop in metrics. In the lack of better ideas, we decided to bisect changes in golang by running full scalability suite on 5k-node cluster against them. This will take couple more days though... |
|
@wojtek-t yes i can, please let me know what needs to be done (so i can figure out if i have access before you head out) |
|
Ah just update to latest golang when it gets out. yes, i can do that. i was wondering if you wanted me to kick off some CI runs or something. Have a good vacation @wojtek-t |
|
@dims - thanks a lot! |
|
I can also help out to get this upgrade in when it’s released. Thanks for all your work on this @wojtek-t! |
|
Looks like 1.12.5 went out this afternoon. PR open (#77528), but expect tests to fail:
|
|
Just to clarify the above (from @cblecker : "oh, so I saw the auto update ran here: https://github.com/docker-library/golang/commits/master but it looks like the update for the tags hasn't merged yet: docker-library/official-images#5867" |
|
Yea, it takes some time for the images to get published. |
Looks like new images are live. |
|
Reopening this so we can verify that everything is back to normal in CI |
|
/assign |
|
Opened pick: #77831 |
|
@wojtek-t has SIG Scalability done any one-off custom scale/perf testing with the new golang patch release and the k8s 1.14 branch content? Do you see this cherry pick as a 1.14.2 release blocker? Or would a week or two of focused testing with updated golang in the 1.14 k8s branch and a 1.14.3 release by end of May be a sufficiently safe yet expedient response? |
We were doing a bunch of tests to discover the real regression in golang 1.12 - the regression happened within 1.14 release timeframe and the bisection was done on that branch.
Tough question - I would love to see it in 1.14.2, otoh given how long it took to debug and fix it, I can see release team pushing it to 1.14.3. But if we could have that in 1.14.2, it would be extremely helpful. |
|
#77831 just merged and we let 1.14 soak for one or two days before we cut Let's keep this issue open until we have some data on the latencies after that merge. SIG Scalability, can you please provide some data / graphs about the latency in a (couple of) days for the |
|
@wojtek-t is there any evidence we'll be able to observe in https://testgrid.k8s.io/sig-release-1.14-blocking for validation? Or is it possible for SIG Scalability to trigger any custom runs now that the cherry-pick has merged to the 1.14 branch? |
|
We aren't running large tests on release branches due to cost of them... But I'm 100% confident with this change. What I was personally doing in the past:
So I'm entirely sure that if you didn't observe any correctness issues, from performance perspective it is good-to-go. |
|
@wojtek-t Thanks for your answer! |
|
With this being fixed in head and 1.14.2 released with the fix, I'm closing this one as fixed. |
Something has changed between 320 and 321 runs and the request latency has increased significantly.
The graphs below shows request latency (non watch) over time for a single test run:
320:

321:

In my opinion they looks significantly different: in 320 most of the spikes are lower than 0.8s while 321 most of the spikes exceeds 1.6s.
I checked few runs below 320 and have latency pattern similar to 320 and few runs after 321 and they have similar pattern to the 321.
We are seeing similar latency growth in kubemark tests.
The most significant change between 321 and 320 was go 1.11.5 -> 1.12 migration.
/cc @wojtek-t @krzysied
The text was updated successfully, but these errors were encountered: