能不能 先 STAR 再白嫖!!!!! 强调一下本代码只供学习参考使用,已经10+人clone过了如果你们用原代码验收结果都一样我不负责哦
本次实验实际是上一学期计算机组织与结构I的一个实践环节,旨在让我们加深对于CPU各个部分的理解,并且让我们深入熟悉微指令、微操作。对于CPU运行程序的流程(取址、取指令等等)也有了更深的理解。
同时,从模块设计,到程序实现,仿真运行以及上板调试,让我们对于Vivado软件的使用、开发板的使用等也都有了更加深刻的认识,能够独立的做一些小项目。
根据实验指导书,我们根据给出的提示设计了一个类似的整体架构,相比原先的架构,这里可以看到去除了BR寄存器。
其实在最开始设计的时候,我使用了BR寄存器,在后续实验的完成中,发现在本例中鲜有用到多个操作数,因此在后续的实验设计中去除了BR寄存器,减少了一个时序。
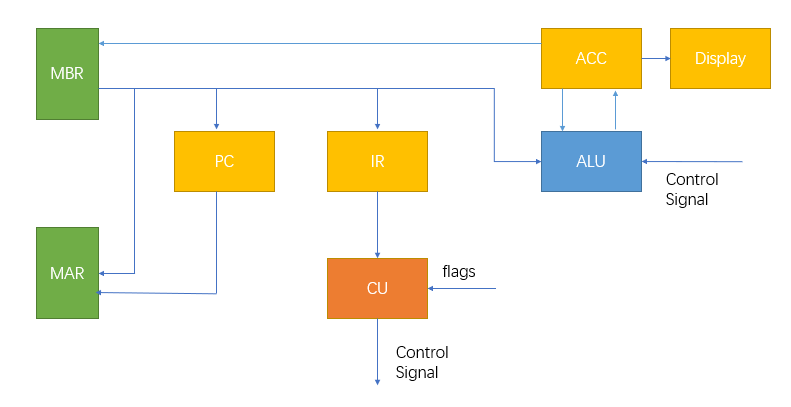
从图中,我们可以看到需要MAR、MBR、PC、IR、CU、ALU、ACC、Display总共8个单独的模块,除此之外:
- 考虑到MBR需要和内存交互,我们需要一个RAM模块。
- 考虑到CU需要根据IR寄存器给定的opcode去提供对应的控制信号,我们需要一个ROM模块
从CPU设计的整体角度考虑,MBR内的每一个地址单元对应的内容为16-bit,一种情况下前8位为opcode,后8位为立即数或者直接寻址的地址,用于寻址16位的数据。
特别的,这里提到的内存单元内16位数据为16位的二进制数据。存储的数据范围为0~65535或者-32768~32767。
在我们的CPU实验中,考虑到实际实验中,所有的数据都只用直接寻址会比较麻烦,因此在这里设计了直接寻址和立即数寻址两种方式,在使用汇编指令形式表示的情况下,我们可以将指令表示为以下:
| 立即数寻址 | opcode | 直接寻址 | opcode |
|---|---|---|---|
| ADD X | 03 | ADD_A [X] | 13 |
| SUB X | 04 | SUB_A [X] | 14 |
| MPY X | 05 | MPY_A [X] | 15 |
| DIV X | 06 | DIV_A [X] | 16 |
| AND X | 0A | AND_A [X] | 1A |
| OR X | 0B | OR_A [X] | 1B |
| NOT X | 0C | NOT_A [X] | 1C |
| SRL X | 0D | SRL_A [X] | 1D |
| SLL X | 0E | SLL_A [X] | 1E |
| SR X | 0F | SR_A [X] | 1F |
| SL X | 10 | SL_A [X] | 20 |
其中,我们注意到有SRL、SLL、SR、SL四个指令,他们是两两对应的,前两个指令是逻辑右移与逻辑左移,在Vivado中的实现很简单,为$X >> a,X << a$即可,而后两个指令SR、SL是算术右移与算术左移,是带符号的。在Vivado里的实现为$X >>> a,X <<< a$。
特别的,对于一些其他的常用指令,有如下设计:
| 指令 | opcode | 作用 |
|---|---|---|
| LOAD X | 01 | 将立即数X(十六进制)装载到ACC中 |
| STORE X | 02 | 将ACC中的数写入到内存中的地址X上 |
| JMP X | 07 | 无条件跳转,直接跳转到X地址上 |
| JMPGEZ X | 08 | 根据Flag的标志位,进行大于0跳转 |
| HALT | 09 | 程序中止 |
| LOAD_A X | 21 | 将处于内存地址X的十六进制数装载到ACC中 |
这里由于JMP指令是无条件跳转,在程序中除非使用了条件判断进行退出,否则一定会陷入死循环,因此,在实现设计的过程中,我们常用的是JMPGEZ而不会使用JMP命令。
在这里我们的MPY指令和DIV指令都有特殊的处理,将会在下一章节的指令部分详细说明。
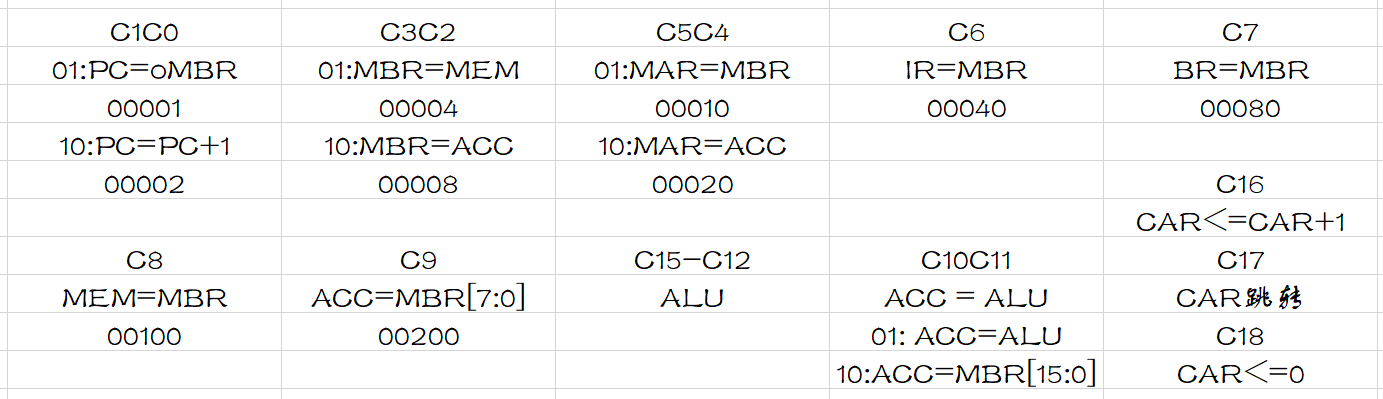
在设计控制信号的时候,未严格控制控制信号的数量,提高使用率,主要考虑功能的实现,所以最后的控制信号使用略微有些多,使用了20位的ctl控制信号作为控制整个程序运行的核心部分。
其中,C15-C12的控制信号用于计算单元的控制,所有的计算指令都将交由这个四位的控制信号进行处理:ADD(0),SUB(1),MPY(2),DIV(3),AND(4),OR(5),NOT(6),SRL(7),SLL(8),SR(9),SL(A)。
注意到在设计中出现了BR=MBR的控制信号,这是在最开始的设计中,使用了BR寄存器,后根据实验需求删除了BR寄存器但依旧保留了C7信号,使得我设计的CPU程序有一定的拓展性,如果需要使用BR寄存器可将BR寄存器恢复并添加C7信号。
当然,由于使用的控制信号较多,在实验中只将ALU内的相应操作信号进行了垂直编码,也可以将其他的一些信号做垂直编码,使得总共使用的控制信号数量不超过16个,16位的控制信号有利于系统的一致性即内部都使用16位的数据。
- 考虑到显示的直观性,需要设计一个显示模块,在常用计算中支持十进制显示,在二进制计算中支持二进制 显示,即使用数码管显示。
- 考虑到程序中需要使用负数,因此定义16位的数据为实际上的有符号的16位数,在数显部分会对超出32767的部分显示为对应的负数。在计算中负数使用补码进行表示。对于数的补码可以表示为:
首先,每个指令都对应着相应的微操作,在此我以LOAD、LOAD_A、STORE、ADD四个指令为例给出他们的微操作(前一个load是立即数,后一个load是从一个内存地址中load):
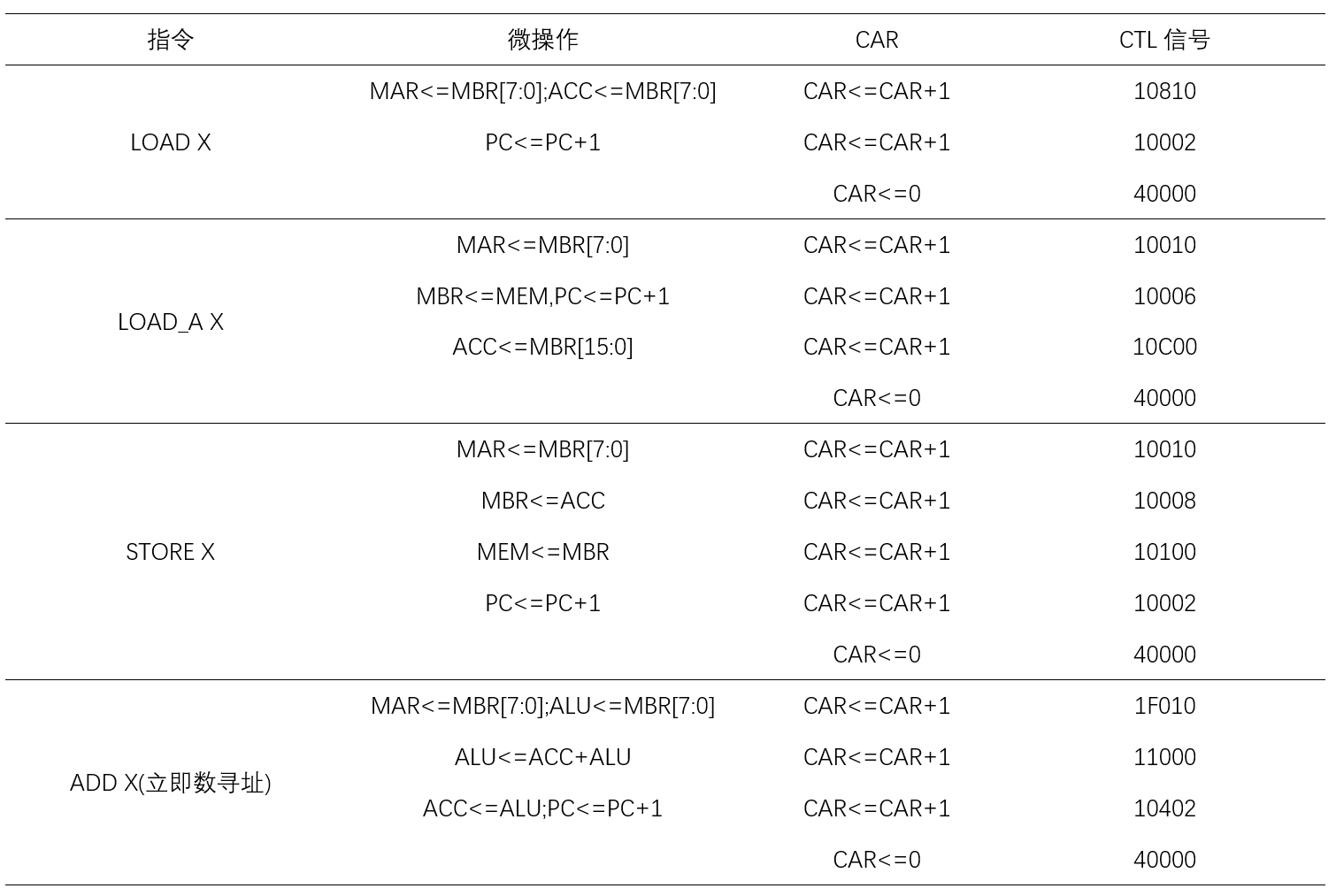
当然,对于每一个指令,都包含了一个相应的取指过程,取指过程如下:

因此,对于一条指令(以ADD指令为例),程序会从CAR=0的位置开始运行,也就是取指的过程,依次运行MAR<=PC, MBR<=MEM, IR<=MBR[15:8]三条指令后得到PC位置的指令对应的Opcode。得到Opcode之后便可以在CU中根据不同的Opcode执行跳转操作,如跳转到ADD X对应的位置开始执行MAR<=MBR[7:0];ALU<=MBR[7:0]等指令。当ADD X指令执行完毕之后,其间PC会进行相应的改变然后CAR重新归为0,回到取指部分。
对于控制信号,我们需要对每一个模块的需求进行分析,然后根据每个模块的需求进行信号的分配,使得不同的模块能够根据ctl信号有序的执行程序。
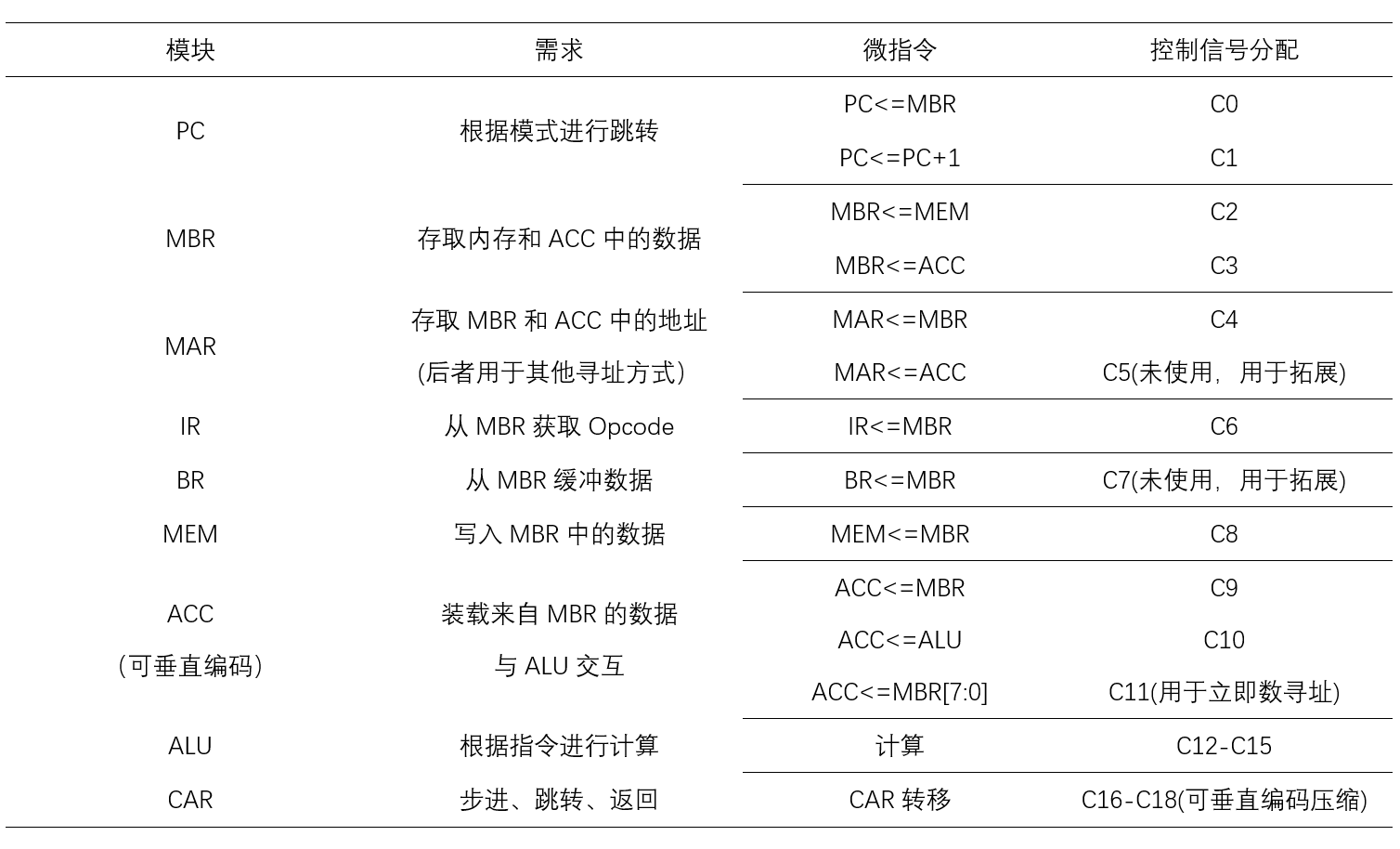
该设计中用到的所有控制信号均由上表给出,所有的单独控制信号均为高电平有效,总共使用到了19个控制信号,当然,其中C5,C7实际未使用留作拓展,C11是为了立即数寻址而单独设计的。C9-C11,C16-C18均可以更换为垂直编码减少两个控制信号的使用,所以该CPU程序中,实际16位的控制信号即可满足全部的设计需求。而为了程序的简洁和可扩展性,我牺牲了一定的程序一致性,使用了20位的控制信号。
在程序的运行过程中,会根据CAR地址的不同,在ROM中查找对应的ctl信号,并且将相应的控制信号位提供给每一个模块。模块会根据控制信号,在clk的上升沿到来时进行相应的操作。
首先,本设计里CPU的模块包含MAR、MBR、PC、IR、CU、ALU、ACC、Display总共8个,其中Display模块可以独立于前七个看做非CPU的部分。下面将对每一个模块做单独分析。
MAR、PC、IR、ACC这几个模块的功能比较单一,只需要根据指令进行相应的赋值即可,所以在此不做详细说明。
MBR作为和内存直接交互的模块,首先需要连接一个内存模块(RAM),可以使用IP Catalog添加一个RAM模块并且进行相应的配置后添加到MBR中。与RAM直接连接的信号包括MAR的地址信号addra,读写使能信号wea,数据的输入输出din、dout,以及时钟信号。
其中wea平时置位0,置位0的情况下,MBR可以进行数据的读取,包括取指等操作都会使用到MBR从MEM中读取数据。只有STORE指令需要往内存中写入数据,此时,需要将wea信号置位高电平1,并根据MAR提供的地址写入数据到内存中。
CU是CPU程序中比较核心的部分,因为CU提供了相应的控制信号,但是CU需要给出的控制信号已经提前写入了ROM中,因此我们需要做的就是确定CAR(读取ROM的地址)的值。CAR的值变化逻辑只有三个:步进、跳转、返回0。因此,CU的设计只需要根据程序的运行逻辑进行CAR的变化即可:
if(ctl[17]==1'b1)
begin
case(oIR)
`opcode: CAR <= 'hXX;// 根据相应的opcode进行对应跳转
......
endcase
end
if(ctl[16]==1'b1) CAR <= CAR + 1;
if(ctl[18]==1'b1) CAR <= 1'b0; ALU是CPU中用于计算的模块,其中用到的两个操作数分别是ALU自身存的来自MBR的数据和ACC中存的数据。ALU使用这两个数据进行相应的计算,并将计算结果传给ACC来保存。部分代码如下:
case (ctl[15:12])
`opADD: oALU <= oACC + oALU;
`opMPY: {MR,oALU} <= oACC * oALU;
`opDIV:
begin
oALU <= oACC / oALU;
DR <= oACC % oALU;
end
`opSR : oALU <= oACC >>> oALU;
`opSL : oALU <= oACC <<< oALU;
......
endcase ALU根据C15-C12垂直编码的信号选择对应的计算操作进行计算,上方代码给了几个特别的操作:
- MPY:本例中实际上我设计的MPY是可以处理16位乘16位数据的,这里使用了MR用于存放超出(溢出)的部分。
- DIV:和MPY一样,DIV除了整数部分,还有余数部分,因此在这里我还同时使用DR存放了除法运算后得到的余数部分数据。
- SR,SL:在前文中已经提到,SR以及SL是算术右移和算术左移,这两者被用于需要带符号的移位。verilog语言中使用三个尖括号可以表示代表带符号的移位运算。
尽管我使用了MR和DR将乘除法的溢出/余数部分数据进行了存储,但是在后续的实验中,由于不需要使用到这两者,因此保留了接出的接口,并未实际接出。因此本程序如果想要做到16乘法保留高位数据的要求只需要接出MR即可,大大地增加了程序的扩展性。
在Display模块里,我将数据看作为16位的有符号数,范围为-32768~32767,所以我的Display模块需要进行以下的工作:
- 分频
- 十六进制与十进制转换(带符号)
- 数码管十进制与Led灯二进制双数显
使用这样的Display模块可以非常直观的看到我们需要的结果,这将会在后续的测试内容中展示。十进制可以得到我们想要的常规运算结果。而Led的二进制显示又可以显示出我们进行二进制计算的美妙结果,可以说显示的十分贴心了。
另外,我们的Display模块被某组直接拿走使用,这里十分谴责只是白嫖代码而不是借鉴的行为。
我们抽取的验收题目: $$ ((NOT \ 964) \ or \ (1+2+...+25))*((35-26+21) \ SHR \ 2) $$ 根据我的设计,超出16位的部分为溢出,因此,我们可以先分别计算出三个部分后再计算出最终结果:
| Part | Ans(Binary) |
|---|---|
| NOT 964 | 11111100 0011 1011 |
| 1+2+...+25 | 0000 0001 0100 0101 |
| (35-26+21) SHR 2 | 0000 0000 0000 0111 |
| (NOT 964)or(1+2+...+25) | 1111 1101 0111 1111 |
| Ans | 1110 1110 0111 1001 (EE79) |
得到最后结果的十六进制结果为EE79,如果内存中每个位置看为一个16位的有符号数,那么对应的十进制结果位:-4487
根据题设要求,我们可以在内存地址中存入964以及26的十六进制值,前者用于load并计算NOT 964的值,后者用于使用减法并计算出1+2+...+25的值。
使用我在设计中用到的指令,写出验收题目对应的汇编程序如下:
NOT_A 41
STORE_16 42
LOAD_A 40
SUB 01
STORE 40
LOAD_A16 43
ADD_A 40
STORE_16 43
LOAD_A 40
SUB 01
JMPGEZ 04
LOAD 23
SUB 1A
ADD 15
SRL 02
STORE_16 44
LOAD_A16 42
OR_A 43
MPY_A 44 编写好汇编程序后,使用我写的Masm_to_COE程序可以很轻松的直接将汇编程序转为COE文件并交给Vivado读取并综合运行。(具体将在拓展创新部分说明)
COE设计如下:
memory_initialization_radix=16;
memory_initialization_vector=1C41 2242 1140 0401 0240 2143 1340 2243 1140 0401 0804 0123 041A 0315 0D02 2244 2142 1B43 1544 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 001A 03C4; 可以看到,在内存地址的41位置存放了03C4也即964的十六进制表示。在内存地址的40位置存放了1A也即26的十六进制表示。
首先,将COE文件载入到RAM中,并且运行行为仿真,观察到结果如图所示,可以看到十进制的结果为-4487与上一节给出的结果一致。二进制结果为$1110 \ 1110 \ 0111 \ 1001$也即十六进制下的$EE79$与前一节计算的结果完全一致。
其中,可以通过下图观察到我们cpu的中间计算结果为$1111 \ 1100 \ 0011 \ 1011 $
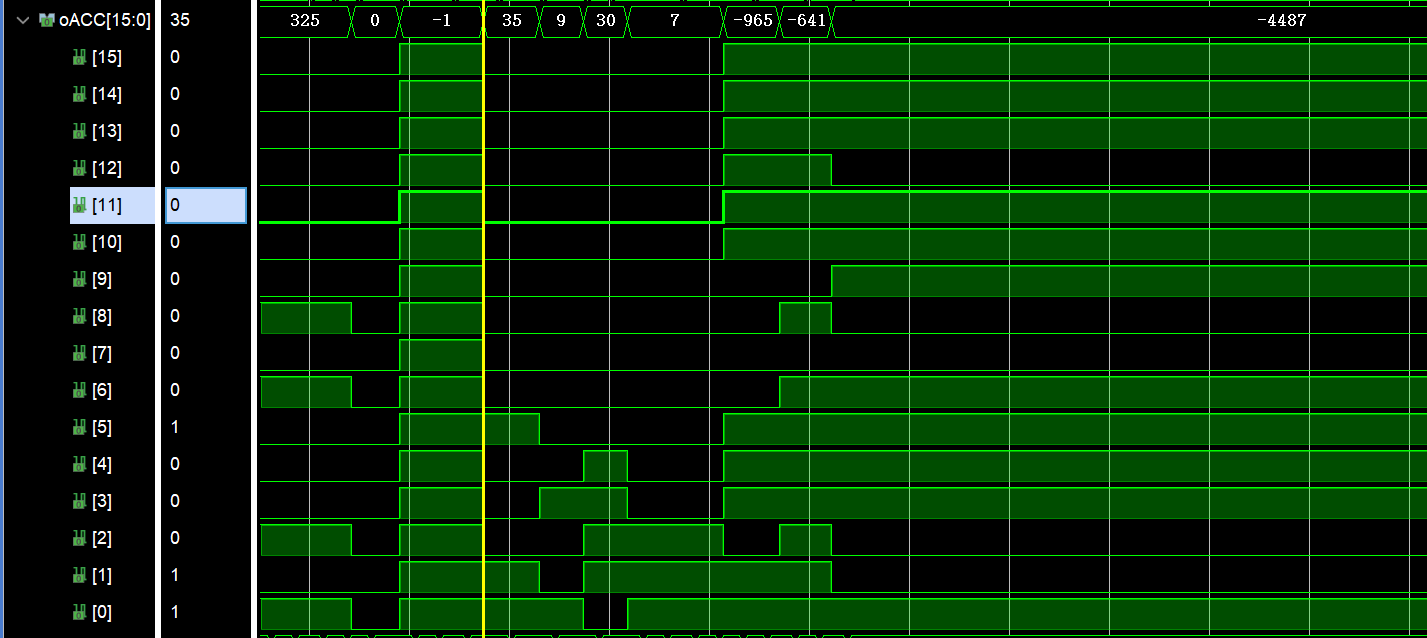
我们按照本例的程序解析以下命令与对应的CTL信号和程序时序:NOT_A 41, STORE 42。这两句命令的含义是将41地址上的数据取非,并将取非的结果存入内存的42地址中。
下面是NOT_A 41部分对应的波形信号:

根据上图的波形我们进行CTL信号的分析,可以看到如下的结果,每一步都严格的遵循我们对CPU设计一步步运行。

下面是STORE 42部分的波形图:
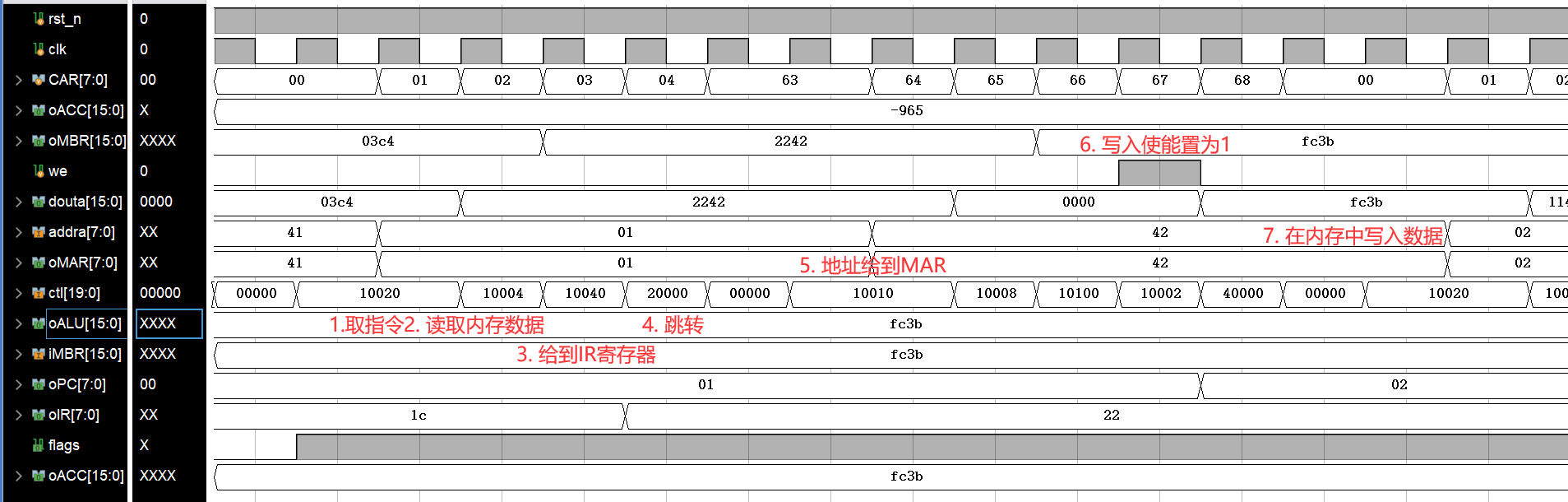
和NOT_A 41指令一样,在此逐个分析STORE 42指令的CTL信号如下:

通过这两个指令的严谨剖析,可以看到我们的程序在行为仿真上,严格遵循了我们的设计,能够非常好地一步步执行我们提供的指令,并给出正确的结果。
但是仅有行为仿真并不足够,我们还需要后仿作为更加严谨的结果。
运行Post-Synthesis Timing Simulation,可以观察到如下的结果图:
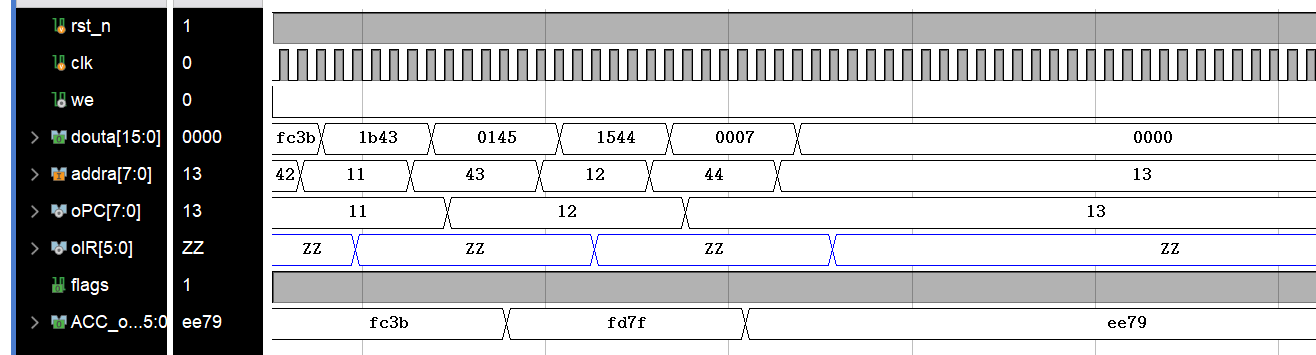
图中可以看到ACC_oBuff的最后结果为EE79也即输出结果的十六进制表示,设计要求达成。
此后,我们观察一下Timing Summary提供的时序报告,可以看到,在绑定了相应的管脚的前提下,在时序报告里,包括WNS、WHS、TNS等在内的所有时序指标均未出现延时冲突,满足设计要求。可以进行上板验证。
此处对于Post Implementation Timing Simulation运行后无法出现结果(表征为仿真不运行),在后续的问题环节予以讨论。

如上图验收的硬件结果,可以看到我们的十进制结果是-4487,(当做十六位有符号数)。二进制结果为$1110 \ 1110 \ 0111 \ 1001$,对应的十六进制结果为EE79与题目的正确结果一致。十分完美的完成了设计任务和验收要求。
1. 后仿的结果不正确
从上图中可以看到,我们的后仿的结果,即使仿真了很久但是依旧没有一个正确的结果,停留在了取第一条指令之后便没有再继续运行。
这里仿真错误表征为只读取了第一条指令后不再运行。
此后,因为无法纠正错误并且Timing Summary的报告显示时序没有错误,因此在无法解决问题后,重新创建了一个工程,将写好的文件原封不动粘贴给新的工程,结果同样的程序得到的后仿结果也有一定的差异,表现为:
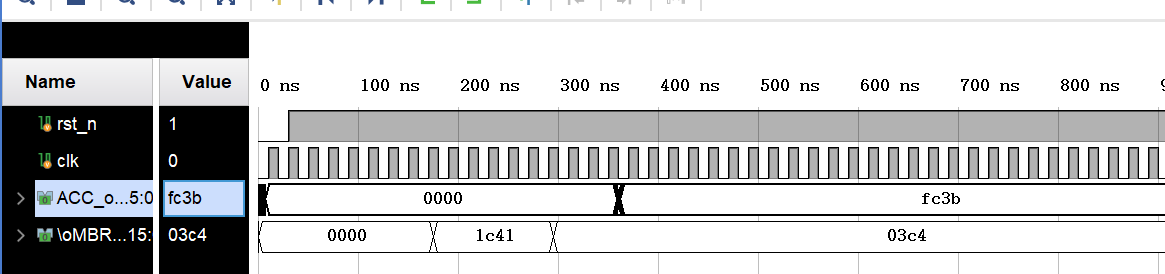
从图中可以看到新工程有这个旧工程一样的问题,运行一会即停止不运行,但是相比旧工程,多了一个输出,已经运行到装载964的步骤,所以这里的困惑实在难以解决,并且身边多有同学遇到了同样的问题,交流讨论后也未能得到合理的解答。
2.RAM的使用有一个很大的延时
在开始实验的时候,发现时序图中有一个很明显的延时,这个延时很大程度上造成了程序的混乱,后来发现是如下的配置没有调整:
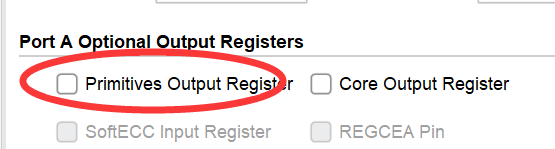
在默认的配置里,这个选项是被勾选的,只有去除掉才能保证只有一个节拍的延时。在解决这个问题的过程中确实耗费了较多的精力。
3. CTL信号不够用
ALU的计算包括了很多的种类,在这种情况下,全部使用CTL信号进行控制便显得十分的不合理,因此,这里使用了4位CTL信号做了垂直的编码来解决相应的问题。
4. 不给使用其他寄存器
由于本次实验的要求中说明不得使用其他的寄存器,因此,在计算的过程中,中间的结果不能存储在寄存器中,必须使用对内存的读写来完成。
之所以写了一个程序用于将汇编程序转化为COE文件,是因为,我们不管进行什么样的设计,其实设计流是一个十分重要的东西,写这样一个转化的程序,可以实现由汇编到十六进制指令到Vivado实现的一个完整设计流。可以让程序有更高的可用性,给任何其他人也可以轻松的根据指令文档进行使用,而不需要他们在文档中找寻指令,也不会出现因为指令编号写错而不断差错,debug很久的问题。
程序的转化效果如下,对应的原汇编程序已在第四部分给出。
在本次实验中,可以看到我选用的指令包含了直接寻址与立即数寻址,如一下两条指令:
LOAD 25 ;表示将十六进制数25装载到ACC中(十进制37)
LOAD_A 25 ;表示将内存中的地址为25的位置上的数装载到ACC中 也可以表示为
LOAD [25] ;含义同上 当然,在本次的CPU实验中,我对于直接寻址和立即数寻址对应了不同的CAR跳转。实际上可以通过增加垂直编码的CTL信号来完成立即数寻址、直接寻址、间接寻址等各种寻址方式。
注意到,在直接寻址和立即数寻址之间,他们有一个明显的不同之处在于:直接寻址的得到的应该是一个十六位的数据,而立即数寻址受限于内存中每个地址单元数据长度的限制,我们得到的是一个八位的数据。所以,在传递数据的时候要注意,对于立即数寻址,传递的应该是$MBR[7:0]$而对于直接寻址,传递的应该是对应地址的$MBR[15:0]$。这也是我在ACC的控制信号中使用多个信号控制传递的具体内容。
从之前的实验结果图片中可以看到,我的CPU设计有着双数显的表现,其好处在于十六进制和十进制的双重显示满足了常见运算和二进制运算的直观显示,能为使用者带来更好的体验。

例如上图显示的计算1+2+3+...+100的程序,我们的二进制和十六进制都没有直观的十进制5050显示来的更加的直观。
- CPU的设计让我知道,在进行设计之前,我们需要一个非常宏观的设计,从架构逐渐细分,一步步设计好我们需要的工程。
- 同时,可以采用按需扩展,设计有兼容性便于扩展的架构,每次可以一点点的补充,不断地完善,在这次的CPU实验中,我总共更新了9个版本。最开始的版本只支持几个简单的基础指令,那时候还是根据实验指导书而写了一个带有BR寄存器的版本。通过这个最简单的版本就可以对准时序,验证设计方案,验证程序的功能性。在后续的版本更迭中,不断的更进行指令扩充和小的逻辑修改,让程序能够实现两种寻址方式,同时也能够对各种运算应付自如。
- 个人认为,设计流是一个十分重要的思想。在这次实验中,也正因为次而设计了从汇编转到COE文件的转换程序,设计流的思想让我能够理清实验设计的步骤,以及步骤之间的相互关系,在更多的情况下有助于加快设计流程。
- 在这次CPU的设计中,其实还有一个问题并没有完全的解决,即Post-implementation Timing simulation,但是在网上以及Xilinx网站上都进行了搜寻并未找到合理的解答。同时相同工程在不同电脑上运行有时候会出来不同的结果,这更加令人费解,因此在后面使用Vivado工具的时候,希望我能够找到具体的问题。当然,由于Timing Summary是正确无误的,说明该设计的时序设计满足要求。所以在实验上板显示的过程中,并没有问题。