Trifecta is a web-based and Command Line Interface (CLI) tool that enables users to quickly and easily inspect, verify and even query Kafka messages. In addition, Trifecta offers data import/export functions for transferring data between Kafka topics and many other Big Data Systems (including Cassandra, ElasticSearch, MongoDB and others).
Table of Contents
- Motivations
- Features
- Development
- Downloads
- What's New
- Trifecta UI
- Trifecta CLI
The motivations behind creating Trifecta are simple; testing, verifying and managing Kafka topics and Zookeeper key-value pairs is an arduous task. The goal of this project is to ease the pain of developing applications that make use of Kafka and ZooKeeper via a console-based tool using simple Unix-like (or SQL-like) commands.
- Avro integration
- Kafka — Avro support
- Elastic Search — Avro support
- Copy Avro-encoded messages from Kafka to Elastic Search as JSON
- Zookeeper — Avro support (coming soon)
- Elastic Search integration (experimental)
- Kafka integration
- Zookeeper integration
In order to build from the source, you'll need to download the above dependencies and issue the following command for each of them:
$ sbt publish-local
Trifecta's build process produces two distinct applications, the command-line interface (trifecta_cli) and the Web-based user interface (trifecta_ui)
$ sbt "project trifecta_cli" assembly
$ sbt "project trifecta_ui" dist
$ sbt clean test
On startup, Trifecta reads $HOME/.trifecta/config.properties (or creates the file if it doesn't exist). This file contains the configuration properties and connection strings for all supported systems.
# common properties
trifecta.common.autoSwitching = true
trifecta.common.columns = 25
trifecta.common.debugOn = false
trifecta.common.encoding = UTF-8
# Kafka/Zookeeper properties
trifecta.zookeeper.host = localhost:2181
# supports the setting of a path prefix for multi-tenant Zookeeper setups
#trifecta.zookeeper.kafka.root.path = /kafka
# indicates whether Storm Partition Manager-style consumers should be read from Zookeeper
trifecta.kafka.consumers.storm = false
# Cassandra properties
trifecta.cassandra.hosts = localhost
# ElasticSearch properties
trifecta.elasticsearch.hosts = localhost:9200
# MongoDB properties
trifecta.mongodb.hosts = localhost
Trifecta currently supports 3 types of consumers:
- Zookeeper Consumer Groups (Kafka 0.8.x)
- Kafka-native Consumer Groups (Kafka 0.9.x)
- Storm Partition Manager Consumers (Apache Storm-specific)
The most common type in use today are the Kafka-native consumers.
Kafka-native consumers require the consumer IDs that you want to monitor to be register via the trifecta.kafka.consumers.native property. Only registered consumer IDs (and their respective offsets will be visible).
trifecta.kafka.consumers.native = dev,test,qa
Zookeeper-based consumers are enabled by default; however, they can be disabled (which will improve performance) by setting the trifecta.kafka.consumers.zookeeper property to false.
trifecta.kafka.consumers.zookeeper = false
Storm Partition Manager consumers are disabled by default; however, they can be enabled (which will impact performance) by setting the trifecta.kafka.consumers.storm property be set to true.
trifecta.kafka.consumers.storm = true
To start the Trifecta REPL:
$ java -jar trifecta_cli_0.20.0.bin.jar
Optionally, you can execute Trifecta instructions (commands) right from the command line:
$ java -jar trifecta_cli_0.20.0.bin.jar kls -l
Trifecta binaries are available for immediate download in the "releases" section.
- Reimplemented Publish and Query views (ported from v0.20.0)
- Now offering simultaneous support for Kafka 0.8.x, 0.9.x and 0.10.x
- Added support for Kafka 0.10.0.0
- Added support for AVDL
- Updated to use MEANS.js 0.2.3.0 (Scalajs-Nodejs)
- Trifecta UI (CLI version)
- Miscellaneous bug fixes
- Trifecta UI (TypeSafe Play version)
- Miscellaneous bug fixes
- Trifecta UI (TypeSafe version)
- Fixed issue with out of memory errors while streaming messages
- Trifecta UI (CLI version)
- Fixed issue with missing web resources
- Trifecta UI
- Now a TypeSafe Play Application
- Updated the user interface
- Bug fixes
-
Trifecta Core
- Fixed issue with the application failing if the configuration file is not found
- Upgraded to Kafka 0.8.2-beta
- Kafka Query language (KQL) (formerly Big-Data Query Language/BDQL) has grammar simplification
- The "with default" clause is no longer necessary
- Upgraded to Kafka 0.8.2.0
- Added configuration key to support multi-tenant Zookeeper setups
- Added support for Kafka
v0.8.2.0v9.0.0 consumers
-
Trifecta UI
- Added capability to navigate directly from a message (in the Inspect tab) to its decoder (in the Decoders tab)
- Decoder tab user interface improvements
- Observe tab user interface improvements
- The Consumers section has been enhanced to display topic and consumer offset deltas
- Redesigned the Replicas view to report under-replicated partitions.
- The Topics section has been enhanced to display topic offset deltas
- Query tab user interface improvements
- Multiple queries can be executed concurrently
- The embedded web server now supports asynchronous request/response flows
- Added real-time message streaming capability to the Inspect tab
- Swapped the Inspect and Observe modules
- Added a new Brokers view to the Observe module
- Reworked the Brokers view (Inspect module)
- Fixed sort ordering of partitions in the Replicas view (Inspect module)
- Fixed potential bug related to retrieving the list of available brokers
- Now a TypeSafe Play Application w/updated the user interface
Trifecta offers a single-page web application (via Angular.js) with a REST service layer and web-socket support, which offers a comprehensive and powerful set of features for inspecting Kafka topic partitions and messages.

To start the Play web application, issue the following from the command line:
$ unzip trifecta_ui-0.20.0.zip
$ cd trifecta_ui-0.20.0/bin
$ ./trifecta_ui &
You'll see a few seconds of log messages, then a prompt indicating the web interface is ready for use.
[warn] application - Logger configuration in conf files is deprecated and has no effect. Use a logback configuration file instead.
[info] p.a.l.c.ActorSystemProvider - Starting application default Akka system: application
[info] application - Application has started
[info] play.api.Play$ - Application started (Prod)
[info] p.c.s.NettyServer$ - Listening for HTTP on /0:0:0:0:0:0:0:0:9000
Next, open your browser and navigate to http://localhost:9000 (if you're running locally or the hostname/IP address of the remote host where the web application is running).
Additionally, Trifecta UI introduces a few new properties to the application configuration file (located in $HOME/.trifecta/config.properties). NOTE: The property values shown below are the default values.
# the embedded web server host/IP and port for client connections
trifecta.web.host = localhost
trifecta.web.port = 8888
# the interval (in seconds) that changes to consumer offsets will be pushed to web-socket clients
trifecta.web.push.interval.consumer = 15
# the interval (in seconds) that sampling messages will be pushed to web-socket clients
trifecta.web.push.interval.sampling = 2
# the interval (in seconds) that changes to topics (new messages) will be pushed to web-socket clients
trifecta.web.push.interval.topic = 15
# the number of actors to create for servicing requests
trifecta.web.actor.concurrency = 10
Trifecta UI supports decoding Avro-encoded messages and displaying them in JSON format. To associate an Avro schema to a
Kafka topic, place the schema file in a subdirectory with the same name as the topic. For example, if I wanted to
associate an Avro file named quotes.avsc to the Kafka topic shocktrade.quotes.avro, I'd setup the following
file structure:
$HOME/.trifecta/decoders/shocktrade.quotes.avro/quotes.avsc
The name of the actual schema file can be anything you'd like. Once the file has been placed in the appropriate location, restart Trifecta UI, and your messages will be displayed in JSON format.

Additionally, once a "default" decoder is configured for a Kafka topic, the CLI application can use them as well. For more details about using default decoders with the CLI application click here.
Trifecta UI has powerful support for viewing Kafka messages, and when the messages are in either JSON or Avro format Trifecta displays them as human readable (read: pretty) JSON documents.

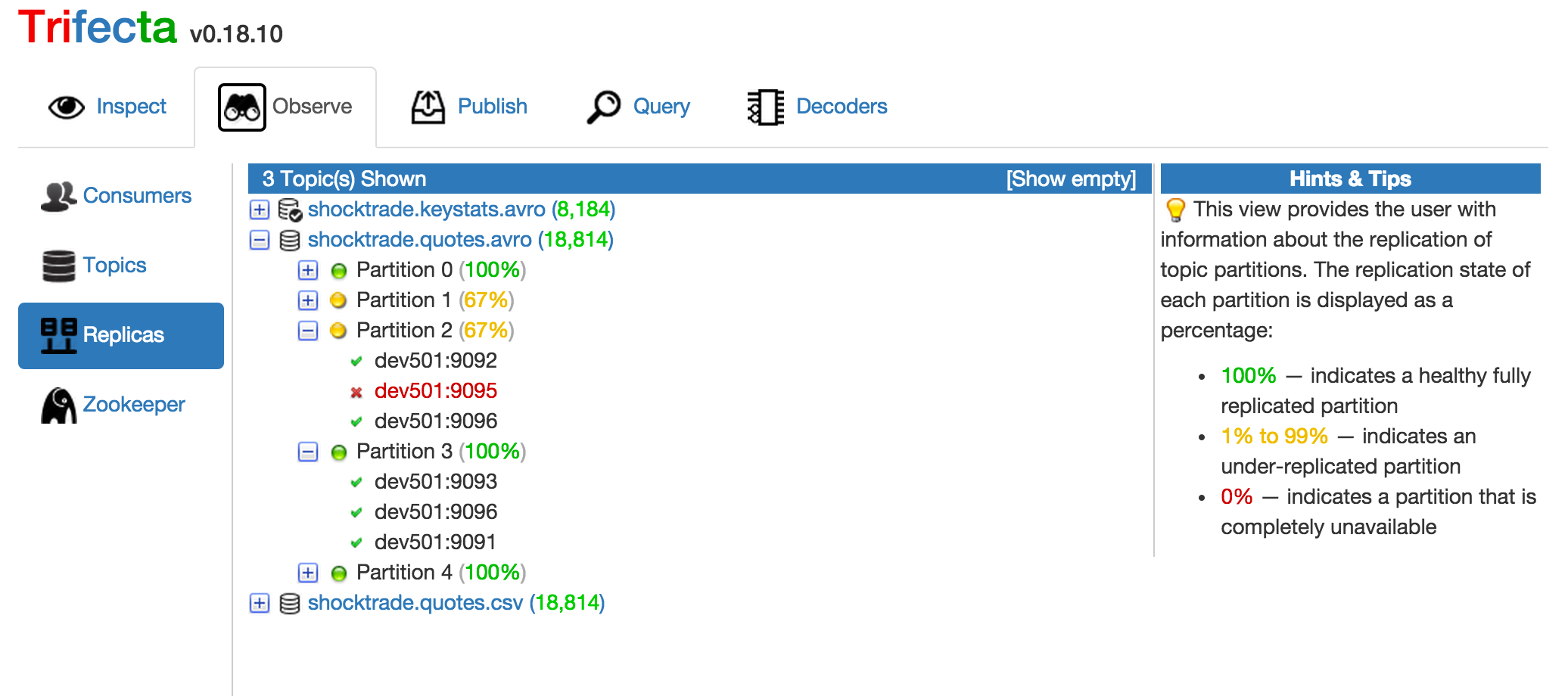
Trifecta UI provides a comprehensive view of the current state of replication for each topic partition.
Trifecta UI also provides a way to execute queries against Avro-encoded topics using the Kafka Query Language (KQL). KQL is a SQL-like language with syntax as follows:
select <fields> from <topic> [with <decoder>]
[where <condition>]
[limit <count>]
Consider the following example:
select symbol, exchange, lastTrade, open, close, high, low
from "shocktrade.quotes.avro"
where lastTrade <= 1 and volume >= 1,000,000
limit 25The above query retrieves the symbol, exchange, lastTrade, open, close, high and low fields from messages
within the Kafka topic shocktrade.quotes.avro (using the default decoder) filtering for only messages where the
lastTrade is less than or equal to 1, the volume is greater than or equal to 1,000,000, and limiting the
number of results to 25.
Now consider a similar example, except here we'll specify a custom decoder file (avro/quotes.avsc):
select symbol, exchange, lastTrade, open, close, high, low
from "shocktrade.quotes.avro" with "avro:file:avro/quotes.avsc"
where lastTrade <= 1 and volume >= 1,000,000
limit 25
For more detailed information about KQL queries, click here.
Trifecta CLI (Command Line Interface) is a REPL tool that simplifies inspecting Kafka messages, Zookeeper data, and optionally Elastic Search documents and MongoDB documents via simple UNIX-like commands (or SQL-like queries).
Trifecta exposes its commands through modules. At any time to see which modules are available one could issue the modules command.
core:/home/ldaniels> modules
+ ---------------------------------------------------------------------------------------------------------- +
| name className loaded active |
+ ---------------------------------------------------------------------------------------------------------- +
| cassandra com.github.ldaniels528.trifecta.modules.cassandra.CassandraModule true false |
| core com.github.ldaniels528.trifecta.modules.core.CoreModule true true |
| elasticSearch com.github.ldaniels528.trifecta.modules.elasticsearch.ElasticSearchModule true false |
| etl com.github.ldaniels528.trifecta.modules.etl.ETLModule true false |
| kafka com.github.ldaniels528.trifecta.modules.kafka.KafkaModule true false |
| mongodb com.github.ldaniels528.trifecta.modules.mongodb.MongoModule true false |
| zookeeper com.github.ldaniels528.trifecta.modules.zookeeper.ZookeeperModule true false |
+ ---------------------------------------------------------------------------------------------------------- +
To execute local system commands, enclose the command you'd like to execute using the back-ticks (`) symbol:
core:/home/ldaniels> `netstat -ptln`
To see all available commands, use the help command (? is a shortcut):
core:/home/ldaniels> ?
+ ---------------------------------------------------------------------------------------------------------------------- +
| command module description |
+ ---------------------------------------------------------------------------------------------------------------------- +
| ! core Executes a previously issued command |
| $ core Executes a local system command |
| ? core Provides the list of available commands |
| autoswitch core Automatically switches to the module of the most recently executed command |
. .
. .
. .
| ztree zookeeper Retrieves Zookeeper directory structure |
+ ---------------------------------------------------------------------------------------------------------------------- +
To see the syntax/usage of a command, use the syntax command:
core:/home/ldaniels> syntax kget
Description: Retrieves the message at the specified offset for a given topic partition
Usage: kget [-o outputSource] [-d YYYY-MM-DDTHH:MM:SS] [-a avroSchema] [topic] [partition] [offset]
To view all of the Kafka commands, use the -m switch and the module name
kafka:/> ? -m kafka
+ ------------------------------------------------------------------------------------------------------------------- +
| command module description |
+ ------------------------------------------------------------------------------------------------------------------- +
| kbrokers kafka Returns a list of the brokers from ZooKeeper |
| kcommit kafka Commits the offset for a given topic and group |
| kconsumers kafka Returns a list of the consumers from ZooKeeper |
| kcount kafka Counts the messages matching a given condition |
| kcursor kafka Displays the message cursor(s) |
| kfetch kafka Retrieves the offset for a given topic and group |
| kfetchsize kafka Retrieves or sets the default fetch size for all Kafka queries |
| kfind kafka Finds messages matching a given condition and exports them to a topic |
| kfindone kafka Returns the first occurrence of a message matching a given condition |
| kfirst kafka Returns the first message for a given topic |
| kget kafka Retrieves the message at the specified offset for a given topic partition |
| kgetkey kafka Retrieves the key of the message at the specified offset for a given topic partition |
| kgetminmax kafka Retrieves the smallest and largest message sizes for a range of offsets for a given partition |
| kgetsize kafka Retrieves the size of the message at the specified offset for a given topic partition |
| kinbound kafka Retrieves a list of topics with new messages (since last query) |
| klast kafka Returns the last message for a given topic |
| kls kafka Lists all existing topics |
| knext kafka Attempts to retrieve the next message |
| kprev kafka Attempts to retrieve the message at the previous offset |
| kreset kafka Sets a consumer group ID to zero for all partitions |
| kstats kafka Returns the partition details for a given topic |
| kswitch kafka Switches the currently active topic cursor |
+ ------------------------------------------------------------------------------------------------------------------- +
To list the replica brokers that Zookeeper is aware of:
kafka:/> kbrokers
+ ---------------------------------------------------------- +
| jmx_port timestamp host version port |
+ ---------------------------------------------------------- +
| 9999 2014-08-23 19:33:01 PDT dev501 1 9093 |
| 9999 2014-08-23 18:41:07 PDT dev501 1 9092 |
| 9999 2014-08-23 18:41:07 PDT dev501 1 9091 |
| 9999 2014-08-23 20:05:17 PDT dev502 1 9093 |
| 9999 2014-08-23 20:05:17 PDT dev502 1 9092 |
| 9999 2014-08-23 20:05:17 PDT dev502 1 9091 |
+ ---------------------------------------------------------- +
To list all of the Kafka topics that Zookeeper is aware of:
kafka:/> kls
+ ------------------------------------------------------ +
| topic partitions replicated |
+ ------------------------------------------------------ +
| Shocktrade.quotes.csv 5 100% |
| shocktrade.quotes.avro 5 100% |
| test.Shocktrade.quotes.avro 5 100% |
| hft.Shocktrade.quotes.avro 5 100% |
| test2.Shocktrade.quotes.avro 5 100% |
| test1.Shocktrade.quotes.avro 5 100% |
| test3.Shocktrade.quotes.avro 5 100% |
+ ------------------------------------------------------ +
To see a subset of the topics (matches any topic that starts with the given search term):
kafka:/> kls shocktrade.quotes.avro
+ ------------------------------------------------ +
| topic partitions replicated |
+ ------------------------------------------------ +
| shocktrade.quotes.avro 5 100% |
+ ------------------------------------------------ +
To see a detailed list including all partitions, use the -l flag:
kafka:/> kls -l shocktrade.quotes.avro
+ ------------------------------------------------------------------ +
| topic partition leader replicas inSync |
+ ------------------------------------------------------------------ +
| shocktrade.quotes.avro 0 dev501:9092 1 1 |
| shocktrade.quotes.avro 1 dev501:9093 1 1 |
| shocktrade.quotes.avro 2 dev502:9091 1 1 |
| shocktrade.quotes.avro 3 dev502:9092 1 1 |
| shocktrade.quotes.avro 4 dev502:9093 1 1 |
+ ------------------------------------------------------------------ +
To see the statistics for a specific topic, use the kstats command:
kafka:/> kstats Shocktrade.quotes.csv
+ --------------------------------------------------------------------------------- +
| topic partition startOffset endOffset messagesAvailable |
+ --------------------------------------------------------------------------------- +
| Shocktrade.quotes.csv 0 5945 10796 4851 |
| Shocktrade.quotes.csv 1 5160 10547 5387 |
| Shocktrade.quotes.csv 2 3974 8788 4814 |
| Shocktrade.quotes.csv 3 3453 7334 3881 |
| Shocktrade.quotes.csv 4 4364 8276 3912 |
+ --------------------------------------------------------------------------------- +
The Kafka module offers the concept of a navigable cursor. Any command that references a specific message offset
creates a pointer to that offset, called a navigable cursor. Once the cursor has been established, with a single command,
you can navigate to the first, last, previous, or next message using the kfirst, klast, kprev and knext commands
respectively. Consider the following examples:
To retrieve the first message of a topic partition:
kafka:/> kfirst Shocktrade.quotes.csv 0
[5945:000] 22.47.44.46.22.2c.31.30.2e.38.31.2c.22.39.2f.31.32.2f.32.30.31.34.22.2c.22 | "GDF",10.81,"9/12/2014"," |
[5945:025] 34.3a.30.30.70.6d.22.2c.4e.2f.41.2c.4e.2f.41.2c.2d.30.2e.31.30.2c.22.2d.30 | 4:00pm",N/A,N/A,-0.10,"-0 |
[5945:050] 2e.31.30.20.2d.20.2d.30.2e.39.32.25.22.2c.31.30.2e.39.31.2c.31.30.2e.39.31 | .10 - -0.92%",10.91,10.91 |
[5945:075] 2c.31.30.2e.38.31.2c.31.30.2e.39.31.2c.31.30.2e.38.30.2c.33.36.35.35.38.2c | ,10.81,10.91,10.80,36558, |
[5945:100] 4e.2f.41.2c.22.4e.2f.41.22 | N/A,"N/A" |
The previous command resulted in the creation of a navigable cursor (notice below how our prompt has changed).
kafka:Shocktrade.quotes.csv/0:5945> _
Let's view the cursor:
kafka:Shocktrade.quotes.csv/0:5945> kcursor
+ ------------------------------------------------------------------- +
| topic partition offset nextOffset decoder |
+ ------------------------------------------------------------------- +
| Shocktrade.quotes.csv 0 5945 5946 |
+ ------------------------------------------------------------------- +
Let's view the next message for this topic partition:
kafka:Shocktrade.quotes.csv/0:5945> knext
[5946:000] 22.47.44.50.22.2c.31.38.2e.35.31.2c.22.39.2f.31.32.2f.32.30.31.34.22.2c.22 | "GDP",18.51,"9/12/2014"," |
[5946:025] 34.3a.30.31.70.6d.22.2c.4e.2f.41.2c.4e.2f.41.2c.2d.30.2e.38.39.2c.22.2d.30 | 4:01pm",N/A,N/A,-0.89,"-0 |
[5946:050] 2e.38.39.20.2d.20.2d.34.2e.35.39.25.22.2c.31.39.2e.34.30.2c.31.39.2e.32.37 | .89 - -4.59%",19.40,19.27 |
[5946:075] 2c.31.38.2e.35.31.2c.31.39.2e.33.32.2c.31.38.2e.33.30.2c.31.35.31.36.32.32 | ,18.51,19.32,18.30,151622 |
[5946:100] 30.2c.38.32.32.2e.33.4d.2c.22.4e.2f.41.22 | 0,822.3M,"N/A" | | M,"N/A" |
Let's view the last message for this topic partition:
kafka:Shocktrade.quotes.csv/0:5945> klast
[10796:000] 22.4e.4f.53.50.46.22.2c.30.2e.30.30.2c.22.4e.2f.41.22.2c.22.4e.2f.41.22.2c | "NOSPF",0.00,"N/A","N/A", |
[10796:025] 4e.2f.41.2c.4e.2f.41.2c.4e.2f.41.2c.22.4e.2f.41.20.2d.20.4e.2f.41.22.2c.4e | N/A,N/A,N/A,"N/A - N/A",N |
[10796:050] 2f.41.2c.4e.2f.41.2c.30.2e.30.30.2c.4e.2f.41.2c.4e.2f.41.2c.4e.2f.41.2c.4e | /A,N/A,0.00,N/A,N/A,N/A,N |
[10796:075] 2f.41.2c.22.54.69.63.6b.65.72.20.73.79.6d.62.6f.6c.20.68.61.73.20.63.68.61 | /A,"Ticker symbol has cha |
[10796:100] 6e.67.65.64.20.74.6f.3a.20.3c.61.20.68.72.65.66.3d.22.2f.71.3f.73.3d.4e.4f | nged to: <a href="/q?s=NO |
[10796:125] 53.50.46.22.3e.4e.4f.53.50.46.3c.2f.61.3e.22 | SPF">NOSPF</a>" | | ,N/A,"N/A" |
Notice above we didn't have to specify the topic or partition because it's defined in our cursor. Let's view the cursor again:
kafka:Shocktrade.quotes.csv/0:10796> kcursor
+ ------------------------------------------------------------------- +
| topic partition offset nextOffset decoder |
+ ------------------------------------------------------------------- +
| Shocktrade.quotes.csv 0 10796 10797 |
+ ------------------------------------------------------------------- +
Now, let's view the previous record:
kafka:Shocktrade.quotes.csv/0:10796> kprev
[10795:000] 22.4d.4c.50.4b.46.22.2c.30.2e.30.30.2c.22.4e.2f.41.22.2c.22.4e.2f.41.22.2c | "MLPKF",0.00,"N/A","N/A", |
[10795:025] 4e.2f.41.2c.4e.2f.41.2c.4e.2f.41.2c.22.4e.2f.41.20.2d.20.4e.2f.41.22.2c.4e | N/A,N/A,N/A,"N/A - N/A",N |
[10795:050] 2f.41.2c.4e.2f.41.2c.30.2e.30.30.2c.4e.2f.41.2c.4e.2f.41.2c.4e.2f.41.2c.4e | /A,N/A,0.00,N/A,N/A,N/A,N |
[10795:075] 2f.41.2c.22.54.69.63.6b.65.72.20.73.79.6d.62.6f.6c.20.68.61.73.20.63.68.61 | /A,"Ticker symbol has cha |
[10795:100] 6e.67.65.64.20.74.6f.3a.20.3c.61.20.68.72.65.66.3d.22.2f.71.3f.73.3d.4d.4c | nged to: <a href="/q?s=ML |
[10795:125] 50.4b.46.22.3e.4d.4c.50.4b.46.3c.2f.61.3e.22 | PKF">MLPKF</a>" | | N/A,"N/A" |
To retrieve the start and end offsets and number of messages available for a topic across any number of partitions:
kafka:Shocktrade.quotes.csv/0:10795> kstats
+ --------------------------------------------------------------------------------- +
| topic partition startOffset endOffset messagesAvailable |
+ --------------------------------------------------------------------------------- +
| Shocktrade.quotes.csv 0 5945 10796 4851 |
| Shocktrade.quotes.csv 1 5160 10547 5387 |
| Shocktrade.quotes.csv 2 3974 8788 4814 |
| Shocktrade.quotes.csv 3 3453 7334 3881 |
| Shocktrade.quotes.csv 4 4364 8276 3912 |
+ --------------------------------------------------------------------------------- +
NOTE: Above kstats is equivalent to both kstats Shocktrade.quotes.csv and
kstats Shocktrade.quotes.csv 0 4. However, because of the cursor we previously established, those arguments
could be omitted.
To see the current offsets for all consumer group IDs:
kafka:Shocktrade.quotes.csv/0:10795> kconsumers
+ ------------------------------------------------------------------------------------- +
| consumerId topic partition offset topicOffset messagesLeft |
+ ------------------------------------------------------------------------------------- +
| dev Shocktrade.quotes.csv 0 5555 10796 5241 |
| dev Shocktrade.quotes.csv 1 0 10547 10547 |
| dev Shocktrade.quotes.csv 2 0 8788 8788 |
| dev Shocktrade.quotes.csv 3 0 7334 7334 |
| dev Shocktrade.quotes.csv 4 0 8276 8276 |
+ ------------------------------------------------------------------------------------- +
Let's change the committed offset for the current topic/partition (the one to which our cursor is pointing) to 6000
kafka:Shocktrade.quotes.csv/0:10795> kcommit dev 6000
Let's re-examine the consumer group IDs:
kafka:Shocktrade.quotes.csv/0:10795> kconsumers
+ ------------------------------------------------------------------------------------- +
| consumerId topic partition offset topicOffset messagesLeft |
+ ------------------------------------------------------------------------------------- +
| dev Shocktrade.quotes.csv 0 6000 10796 4796 |
| dev Shocktrade.quotes.csv 1 0 10547 10547 |
| dev Shocktrade.quotes.csv 2 0 8788 8788 |
| dev Shocktrade.quotes.csv 3 0 7334 7334 |
| dev Shocktrade.quotes.csv 4 0 8276 8276 |
+ ------------------------------------------------------------------------------------- +
Notice that the committed offset, for consumer group dev, has been changed to 6000 for partition 0.
Finally, let's use the kfetch to retrieve just the offset for the consumer group ID:
kafka:Shocktrade.quotes.csv/0:10795> kfetch dev
6000
The Kafka Module also provides the capability for watching messages (in near real-time) as they become available. When
you watch a topic, a watch cursor is created, which allows you to move forward through the topic as new messages appear.
This differs from navigable cursors, which allow you to move back and forth through a topic at will. You can take
advantage of this feature by using two built-in commands: kwatch and kwatchnext.
First, kwatch is used to create a connection to a consumer group:
kafka:Shocktrade.quotes.csv/0:10795> kwatch shocktrade.quotes.avro dev -a file:avro/quotes.avsc
Some output will likely follow as the connection (and watch cursor) are established. Next, if a message is already available, it will be returned immediately:
{
"symbol":"MNLDF",
"exchange":"OTHER OTC",
"lastTrade":1.18,
"tradeDate":null,
"tradeTime":"1:50pm",
"ask":null,
"bid":null,
"change":0.0,
"changePct":0.0,
"prevClose":1.18,
"open":null,
"close":1.18,
"high":null,
"low":null,
"volume":0,
"marketCap":null,
"errorMessage":null
}
kafka:[w]shocktrade.quotes.avro/4:23070> _
To retrieve any subsequent messages, you use the kwatchnext command:
kafka:[w]shocktrade.quotes.avro/4:23070> kwatchnext
{
"symbol":"PXYN",
"exchange":"OTHER OTC",
"lastTrade":0.075,
"tradeDate":null,
"tradeTime":"3:57pm",
"ask":null,
"bid":null,
"change":0.01,
"changePct":15.38,
"prevClose":0.065,
"open":0.064,
"close":0.075,
"high":0.078,
"low":0.064,
"volume":1325779,
"marketCap":2.45E7,
"errorMessage":null
}
kafka:[w]shocktrade.quotes.avro/4:23071> _
Did you notice the "[w]" you see in the prompt? This indicates a watch cursor is active. However, because each call to
kwatchnext will also update the navigable cursor, you are free to also use the bi-directional navigation commands
knext and kprev (as well as kfirst and klast). Be aware though, that changes to the navigable cursor do not
affect the watch cursor. Thus after a subsequent use of kwatchnext, the navigable cursor will be overwritten.
To retrieve the list of topics with new messages (since your last query):
kafka:/> kinbound
+ ----------------------------------------------------------------------------------------------------------- +
| topic partition startOffset endOffset change msgsPerSec lastCheckTime |
+ ----------------------------------------------------------------------------------------------------------- +
| Shocktrade.quotes.avro 3 0 657 65 16.3 09/13/14 06:37:03 PDT |
| Shocktrade.quotes.avro 0 0 650 64 16.0 09/13/14 06:37:03 PDT |
| Shocktrade.quotes.avro 1 0 618 56 14.0 09/13/14 06:37:03 PDT |
| Shocktrade.quotes.avro 2 0 618 49 12.3 09/13/14 06:37:03 PDT |
| Shocktrade.quotes.avro 4 0 584 40 10.0 09/13/14 06:37:03 PDT |
+ ----------------------------------------------------------------------------------------------------------- +
Next, we wait a few moments and run the command again:
kafka:/> kinbound
+ ----------------------------------------------------------------------------------------------------------- +
| topic partition startOffset endOffset change msgsPerSec lastCheckTime |
+ ----------------------------------------------------------------------------------------------------------- +
| Shocktrade.quotes.avro 1 0 913 295 15.6 09/13/14 06:37:21 PDT |
| Shocktrade.quotes.avro 3 0 952 295 15.6 09/13/14 06:37:21 PDT |
| Shocktrade.quotes.avro 2 0 881 263 13.9 09/13/14 06:37:21 PDT |
| Shocktrade.quotes.avro 4 0 846 262 13.8 09/13/14 06:37:21 PDT |
| Shocktrade.quotes.avro 0 0 893 243 12.8 09/13/14 06:37:21 PDT |
+ ----------------------------------------------------------------------------------------------------------- +
Trifecta supports Avro integration for Kafka. The next few examples make use of the following Avro schema:
{
"type": "record",
"name": "StockQuote",
"namespace": "Shocktrade.avro",
"fields":[
{ "name": "symbol", "type":"string", "doc":"stock symbol" },
{ "name": "lastTrade", "type":["null", "double"], "doc":"last sale price", "default":null },
{ "name": "tradeDate", "type":["null", "long"], "doc":"last sale date", "default":null },
{ "name": "tradeTime", "type":["null", "string"], "doc":"last sale time", "default":null },
{ "name": "ask", "type":["null", "double"], "doc":"ask price", "default":null },
{ "name": "bid", "type":["null", "double"], "doc":"bid price", "default":null },
{ "name": "change", "type":["null", "double"], "doc":"price change", "default":null },
{ "name": "changePct", "type":["null", "double"], "doc":"price change percent", "default":null },
{ "name": "prevClose", "type":["null", "double"], "doc":"previous close price", "default":null },
{ "name": "open", "type":["null", "double"], "doc":"open price", "default":null },
{ "name": "close", "type":["null", "double"], "doc":"close price", "default":null },
{ "name": "high", "type":["null", "double"], "doc":"day's high price", "default":null },
{ "name": "low", "type":["null", "double"], "doc":"day's low price", "default":null },
{ "name": "volume", "type":["null", "long"], "doc":"day's volume", "default":null },
{ "name": "marketCap", "type":["null", "double"], "doc":"market capitalization", "default":null },
{ "name": "errorMessage", "type":["null", "string"], "doc":"error message", "default":null }
],
"doc": "A schema for stock quotes"
}
Let's retrieve the first message from topic Shocktrade.quotes.avro (partition 0) using an Avro schema as our optional message decoder:
kafka:/> kfirst Shocktrade.quotes.avro 0 -a file:avro/quotes.avsc
{
"symbol":"GES",
"exchange":"NYSE",
"lastTrade":21.75,
"tradeDate":null,
"tradeTime":"4:03pm",
"ask":null,
"bid":null,
"change":-0.41,
"changePct":-1.85,
"prevClose":22.16,
"open":21.95,
"close":21.75,
"high":22.16,
"low":21.69,
"volume":650298,
"marketCap":1.853E9,
"errorMessage":null
}
Let's view the cursor:
kafka:shocktrade.quotes.avro/2:9728> kcursor
+ ---------------------------------------------------------------------------------- +
| topic partition offset nextOffset decoder |
+ ---------------------------------------------------------------------------------- +
| Shocktrade.quotes.avro 0 0 1 AvroDecoder(schema) |
+ ---------------------------------------------------------------------------------- +
The kfirst, klast, kprev and knext commands also work with the Avro integration:
kafka:shocktrade.quotes.avro/2:9728> knext
{
"symbol":"GEO",
"exchange":"NYSE",
"lastTrade":41.4,
"tradeDate":null,
"tradeTime":"4:03pm",
"ask":null,
"bid":null,
"change":0.76,
"changePct":1.87,
"prevClose":40.64,
"open":40.55,
"close":41.4,
"high":41.49,
"low":40.01,
"volume":896757,
"marketCap":2.973E9,
"errorMessage":null
}
Since Avro is based on JSON, we can also express the same data in Avro compatible JSON format:
kafka:shocktrade.quotes.avro/2:9728> kget -f avro_json
{
"symbol":"GEO",
"exchange":{
"string":"NYSE"
},
"lastTrade":{
"double":41.4
},
"tradeDate":null,
"tradeTime":{
"string":"4:03pm"
},
"ask":null,
"bid":null,
"change":{
"double":0.76
},
"changePct":{
"double":1.87
},
"prevClose":{
"double":40.64
},
"open":{
"double":40.55
},
"close":{
"double":41.4
},
"high":{
"double":41.49
},
"low":{
"double":40.01
},
"volume":{
"long":896757
},
"marketCap":{
"double":2.973E9
},
"errorMessage":null
}
You can also associate a Kafka topic to a "default" Avro schema. To associate an Avro schema to the topic, place the
schema file in a subdirectory with the same name as the topic. For example, if I wanted to associate an Avro file named
quotes.avsc to the Kafka topic shocktrade.quotes.avro, I'd setup the following file structure:
$HOME/.trifecta/decoders/Shocktrade.quotes.avro/quotes.avsc
The name of the actual schema file can be anything you'd like. Once the file has been placed in the appropriate location, restart Trifecta, and default decoder will be ready for use.
In our last example, we did the following:
kafka:/> kfirst Shocktrade.quotes.avro 0 -a file:avro/quotes.avsc
With a default decoder, we can do this instead:
kafka:/> kfirst Shocktrade.quotes.avro 0 -a default
You can view the key for any message by using the kgetkey command. Let's start by retrieving the last available message
for a topic/partition.
kafka:/> klast Shocktrade.quotes.csv 0
[10796:000] 22.4e.4f.53.50.46.22.2c.30.2e.30.30.2c.22.4e.2f.41.22.2c.22.4e.2f.41.22.2c | "NOSPF",0.00,"N/A","N/A", |
[10796:025] 4e.2f.41.2c.4e.2f.41.2c.4e.2f.41.2c.22.4e.2f.41.20.2d.20.4e.2f.41.22.2c.4e | N/A,N/A,N/A,"N/A - N/A",N |
[10796:050] 2f.41.2c.4e.2f.41.2c.30.2e.30.30.2c.4e.2f.41.2c.4e.2f.41.2c.4e.2f.41.2c.4e | /A,N/A,0.00,N/A,N/A,N/A,N |
[10796:075] 2f.41.2c.22.54.69.63.6b.65.72.20.73.79.6d.62.6f.6c.20.68.61.73.20.63.68.61 | /A,"Ticker symbol has cha |
[10796:100] 6e.67.65.64.20.74.6f.3a.20.3c.61.20.68.72.65.66.3d.22.2f.71.3f.73.3d.4e.4f | nged to: <a href="/q?s=NO |
[10796:125] 53.50.46.22.3e.4e.4f.53.50.46.3c.2f.61.3e.22 | SPF">NOSPF</a>" |
Now let's view the key for message using the kgetkey command:
kafka:Shocktrade.quotes.csv/0:10796> kgetkey
[000] 31.34.31.30.35.36.33.37.31.34.34.36.35 | 1410563714465 |
To ensure you'll notice the change in the cursor's position, let's reposition the cursor to the beginning of the topic/partition:
kafka:Shocktrade.quotes.csv/0:10796> kfirst
[5945:000] 22.47.44.46.22.2c.31.30.2e.38.31.2c.22.39.2f.31.32.2f.32.30.31.34.22.2c.22 | "GDF",10.81,"9/12/2014"," |
[5945:025] 34.3a.30.30.70.6d.22.2c.4e.2f.41.2c.4e.2f.41.2c.2d.30.2e.31.30.2c.22.2d.30 | 4:00pm",N/A,N/A,-0.10,"-0 |
[5945:050] 2e.31.30.20.2d.20.2d.30.2e.39.32.25.22.2c.31.30.2e.39.31.2c.31.30.2e.39.31 | .10 - -0.92%",10.91,10.91 |
[5945:075] 2c.31.30.2e.38.31.2c.31.30.2e.39.31.2c.31.30.2e.38.30.2c.33.36.35.35.38.2c | ,10.81,10.91,10.80,36558, |
[5945:100] 4e.2f.41.2c.22.4e.2f.41.22 | N/A,"N/A" |
kafka:Shocktrade.quotes.csv/0:5945> _
Next, using the kfindonecommand let's search for the last message by key (using hexadecimal dot-notation):
kafka:Shocktrade.quotes.csv/0:5945> kfindone key is 31.34.31.30.35.36.33.37.31.34.34.36.35
Task is now running in the background (use 'jobs' to view)
You may have received the message Task is now running in the background (use 'jobs' to view). This happens whenever a
query is executed that requires more than 5 seconds to complete. You may use the jobs command to check the status of a
background task; however, either way, after a few moments the results should appear on the console:
kafka:Shocktrade.quotes.csv/0:5945> Job #1006 completed
[10796:000] 22.4e.4f.53.50.46.22.2c.30.2e.30.30.2c.22.4e.2f.41.22.2c.22.4e.2f.41.22.2c | "NOSPF",0.00,"N/A","N/A", |
[10796:025] 4e.2f.41.2c.4e.2f.41.2c.4e.2f.41.2c.22.4e.2f.41.20.2d.20.4e.2f.41.22.2c.4e | N/A,N/A,N/A,"N/A - N/A",N |
[10796:050] 2f.41.2c.4e.2f.41.2c.30.2e.30.30.2c.4e.2f.41.2c.4e.2f.41.2c.4e.2f.41.2c.4e | /A,N/A,0.00,N/A,N/A,N/A,N |
[10796:075] 2f.41.2c.22.54.69.63.6b.65.72.20.73.79.6d.62.6f.6c.20.68.61.73.20.63.68.61 | /A,"Ticker symbol has cha |
[10796:100] 6e.67.65.64.20.74.6f.3a.20.3c.61.20.68.72.65.66.3d.22.2f.71.3f.73.3d.4e.4f | nged to: <a href="/q?s=NO |
[10796:125] 53.50.46.22.3e.4e.4f.53.50.46.3c.2f.61.3e.22 | SPF">NOSPF</a>" |
The result is the last message of the topic. Notice that our cursor has changed reflecting the move from offset 5945 to 10796.
kafka:Shocktrade.quotes.csv/0:10796> _
Building on the Avro Integration, Trifecta offers the ability to execute queries against structured data.
Suppose you want to know how many messages contain a volume greater than 1,000,000, you could issue the kcount command:
kafka:Shocktrade.quotes.avro/0:1> kcount volume > 1000000
1350
The response was 1350, meaning there are 1350 messages containing a volume greater than 1,000,000.
Suppose you want to find a message for Apple (ticker: "AAPL"), you could issue the kfindone command:
kafka:Shocktrade.quotes.avro/0:1> kfindone symbol == "AAPL"
{
"symbol":"AAPL",
"exchange":"NASDAQNM",
"lastTrade":109.01,
"tradeDate":null,
"tradeTime":"4:00pm",
"ask":109.03,
"bid":109.01,
"change":0.31,
"changePct":0.29,
"prevClose":108.7,
"open":108.72,
"close":109.01,
"high":109.32,
"low":108.55,
"volume":33691536,
"marketCap":6.393E11,
"errorMessage":null
}
You can also specify complex queries by combining multiple expressions with the and keyword:
kafka:Shocktrade.quotes.avro/1234:4> kfindone lastTrade < 1 and volume > 1000000 -a file:avro/quotes.avsc
{
"symbol":"MDTV",
"exchange":"OTHER OTC",
"lastTrade":0.022,
"tradeDate":null,
"tradeTime":"3:27pm",
"ask":null,
"bid":null,
"change":0.0099,
"changePct":81.82,
"prevClose":0.0121,
"open":0.015,
"close":0.022,
"high":0.027,
"low":0.015,
"volume":1060005,
"marketCap":125000.0,
"errorMessage":null
}
Now suppose you want to copy the messages having high volume (1,000,000 or more) to another topic:
kafka:Shocktrade.quotes.avro/3300:3> kfind volume >= 1000000 -o topic:hft.Shocktrade.quotes.avro
Finally, let's look at the results:
kafka:Shocktrade.quotes.avro/3:0> kstats hft.Shocktrade.quotes.avro
+ ---------------------------------------------------------------------------------- +
| topic partition startOffset endOffset messagesAvailable |
+ ---------------------------------------------------------------------------------- +
| hft.Shocktrade.quotes.avro 0 0 283 283 |
| hft.Shocktrade.quotes.avro 1 0 287 287 |
| hft.Shocktrade.quotes.avro 2 0 258 258 |
| hft.Shocktrade.quotes.avro 3 0 245 245 |
| hft.Shocktrade.quotes.avro 4 0 272 272 |
+ ---------------------------------------------------------------------------------- +
Let's see how these statistics compares to the original:
kafka:Shocktrade.quotes.avro/3:0> kstats Shocktrade.quotes.avro
+ ----------------------------------------------------------------------------------- +
| topic partition startOffset endOffset messagesAvailable |
+ ----------------------------------------------------------------------------------- +
| Shocktrade.quotes.avro 0 0 4539 4539 |
| Shocktrade.quotes.avro 1 0 4713 4713 |
| Shocktrade.quotes.avro 2 0 4500 4500 |
| Shocktrade.quotes.avro 3 0 4670 4670 |
| Shocktrade.quotes.avro 4 0 4431 4431 |
+ ----------------------------------------------------------------------------------- +
Trifecta provides the ability to perform SQL-like queries against Avro-encoded Kafka topics (Read more about Trifecta's Kafka-Avro integration here). The syntax is very similar to SQL except for a few minor differences. Here's the basic syntax:
select <fieldsToDisplay>
from <topic> with <decoder>
where <searchCriteria>
limit <maximumNumberOfResultsToReturn>
Where decoder may be:
- json
- avro:file:path
Consider the following example:
kafka:shocktrade.quotes.avro/0:32050> select symbol, exchange, open, close, high, low
from shocktrade.quotes.avro
with "avro:file:avro/quotes.avsc"
where symbol == "AAPL"
NOTE: Because we didn't specify a limit for the number of results that could be returned, the default value (25) is used.
As with most potentially long-running statements in Trifecta, if the query takes longer than a few seconds to complete, it will be executed in the background.
kafka:shocktrade.quotes.avro/0:32050> Job #607 completed (use 'jobs -v 607' to view results)
+ --------------------------------------------------------------------- +
| partition offset symbol exchange open close high low |
+ --------------------------------------------------------------------- +
| 0 32946 AAPL NASDAQNM 108.72 109.01 109.32 108.55 |
+ --------------------------------------------------------------------- +
NOTE: Although the partition and offset fields weren't specified in the query, they are always included in
the query results.
Let's look at another example:
kafka:shocktrade.quotes.avro/0:32050> select symbol, exchange, lastTrade, open, close, high, low
from shocktrade.quotes.avro
with "avro:file:avro/quotes.avsc"
where lastTrade <= 1 and volume >= 1,000,000
limit 25
Task is now running in the background (use 'jobs' to view)
kafka:shocktrade.quotes.avro/0:32050> Job #873 completed (use 'jobs -v 873' to view results)
+ --------------------------------------------------------------------------------- +
| partition offset symbol exchange lastTrade open close high low |
+ --------------------------------------------------------------------------------- +
| 3 34047 NIHDQ OTHER OTC 0.0509 0.0452 0.0509 0.0549 0.0452 |
| 3 33853 IMRS NASDAQNM 0.2768 0.25 0.2768 0.28 0.2138 |
| 3 33818 VTMB OTHER OTC 0.0014 0.0013 0.0014 0.0014 0.0012 |
| 3 33780 MLHC OTHER OTC 4.0E-4 5.0E-4 4.0E-4 5.0E-4 3.0E-4 |
| 3 33709 ECDC OTHER OTC 1.0E-4 1.0E-4 1.0E-4 1.0E-4 1.0E-4 |
| 3 33640 PWDY OTC BB 0.0037 0.0032 0.0037 0.0043 0.003 |
| 3 33534 BPZ NYSE 0.9599 1.02 0.9599 1.0201 0.92 |
| 3 33520 TAGG OTHER OTC 2.0E-4 1.0E-4 2.0E-4 2.0E-4 1.0E-4 |
| 3 33515 MDMN OTHER OTC 0.055 0.051 0.055 0.059 0.051 |
| 3 33469 MCET OTHER OTC 5.0E-4 5.0E-4 5.0E-4 5.0E-4 5.0E-4 |
| 3 33460 GGSM OTHER OTC 3.0E-4 3.0E-4 3.0E-4 4.0E-4 3.0E-4 |
| 3 33404 TDCP OTHER OTC 0.0041 0.0041 0.0041 0.0041 0.0038 |
| 3 33337 GSS AMEX 0.305 0.27 0.305 0.31 0.266 |
| 3 33254 MDTV OTHER OTC 0.022 0.015 0.022 0.027 0.015 |
| 2 33246 AMRN NGM 0.9 0.9128 0.9 0.93 0.88 |
| 2 33110 TRTC OTHER OTC 0.38 0.3827 0.38 0.405 0.373 |
| 2 33068 AEMD OTHER OTC 0.2419 0.26 0.2419 0.2625 0.23 |
| 2 33060 ZBB AMEX 0.6101 0.65 0.6101 0.65 0.55 |
| 2 33058 TUNG OTHER OTC 0.0019 0.0021 0.0019 0.0021 0.0016 |
| 2 33011 DKAM OTHER OTC 1.0E-4 2.0E-4 1.0E-4 2.0E-4 1.0E-4 |
| 2 32984 ADMD OTHER OTC 0.001 0.001 0.001 0.0011 9.0E-4 |
| 2 32905 GLDG OTHER OTC 2.0E-4 2.0E-4 2.0E-4 2.0E-4 2.0E-4 |
| 2 32808 RBY AMEX 0.9349 0.821 0.9349 0.94 0.821 |
| 2 32751 PZG AMEX 0.708 0.6 0.708 0.73 0.5834 |
| 2 32731 PAL AMEX 0.15 0.15 0.15 0.1555 0.145 |
+ --------------------------------------------------------------------------------- +
To view the Zookeeper keys at the current hierarchy level:
zookeeper@dev501:2181:/> zls
consumers
storm
controller_epoch
admin
controller
brokers
To change the current Zookeeper hierarchy level:
zookeeper:localhost:2181:/> zcd brokers
/brokers
Now view the keys at this level:
zookeeper:localhost:2181:/brokers> zls
topics
ids
Let's look at the entire Zookeeper hierarchy recursively from our current path:
zookeeper:localhost:2181/brokers> ztree
/brokers
/brokers/topics
/brokers/topics/shocktrade.quotes.avro
/brokers/topics/shocktrade.quotes.avro/partitions
/brokers/topics/shocktrade.quotes.avro/partitions/0
/brokers/topics/shocktrade.quotes.avro/partitions/0/state
/brokers/topics/shocktrade.quotes.avro/partitions/1
/brokers/topics/shocktrade.quotes.avro/partitions/1/state
/brokers/topics/shocktrade.quotes.avro/partitions/2
/brokers/topics/shocktrade.quotes.avro/partitions/2/state
/brokers/topics/shocktrade.quotes.avro/partitions/3
/brokers/topics/shocktrade.quotes.avro/partitions/3/state
/brokers/topics/shocktrade.quotes.avro/partitions/4
/brokers/topics/shocktrade.quotes.avro/partitions/4/state
/brokers/ids
/brokers/ids/3
/brokers/ids/2
/brokers/ids/1
/brokers/ids/6
/brokers/ids/5
/brokers/ids/4
Let's view the contents of one of the keys:
zookeeper:localhost:2181/brokers> zget topics/Shocktrade.quotes.csv/partitions/4/state
[00] 7b.22.63.6f.6e.74.72.6f.6c.6c.65.72.5f.65.70.6f.63.68.22.3a.31.2c.22.6c.65 | {"controller_epoch":1,"le
[25] 61.64.65.72.22.3a.35.2c.22.76.65.72.73.69.6f.6e.22.3a.31.2c.22.6c.65.61.64 | ader":5,"version":1,"lead
[50] 65.72.5f.65.70.6f.63.68.22.3a.30.2c.22.69.73.72.22.3a.5b.35.5d.7d | er_epoch":0,"isr":[5]}
Since we now know the contents of the key is text-based (JSON in this case), let's look at the JSON value using
the format flag (-f json) to transform the JSON in a nice human-readable format.
zookeeper:localhost:2181/brokers> zget topics/Shocktrade.quotes.csv/partitions/4/state -f json
{
"controller_epoch": 3,
"leader": 6,
"version": 1,
"leader_epoch": 2,
"isr": [6]
}
Next, let's set a key-value pair in Zookeeper:
zookeeper:localhost:2181/> zput /test/message "Hello World"
To retrieve the value we've just set, we can use the zget command again:
zookeeper:localhost:2181/> zget /test/message
[00] 48.65.6c.6c.6f.20.57.6f.72.6c.64 | Hello World
The zput command also allows us to set other types of values besides strings. The following example demonstrates
setting a binary array literal using hexadecimal dot-notation.
zookeeper:localhost:2181/> zput /test/data de.ad.be.ef.ca.fe.ba.be
The default value types for integer and decimal values are long and double respectively. However, you can also
explicitly set the value type using the type flag (-t).
zookeeper:localhost:2181/> zput /test/data2 123.45 -t float
The valid value types are:
- bytes
- char
- double
- float
- integer
- json
- long
- short
- string
To verify that all of the key-value pairs were inserted we use the zls command again:
zookeeper:localhost:2181/> zls /test
data
message
data2
To view all of the Zookeeper commands, use the -m switch and the module name (zookeeper in this case):
zookeeper:localhost:2181/> ? -m zookeeper
+ ----------------------------------------------------------------------------------------- +
| command module description |
+ ----------------------------------------------------------------------------------------- +
| zcd zookeeper Changes the current path/directory in ZooKeeper |
| zexists zookeeper Verifies the existence of a ZooKeeper key |
| zget zookeeper Retrieves the contents of a specific Zookeeper key |
| zls zookeeper Retrieves the child nodes for a key from ZooKeeper |
| zmk zookeeper Creates a new ZooKeeper sub-directory (key) |
| zput zookeeper Sets a key-value pair in ZooKeeper |
| zreconnect zookeeper Re-establishes the connection to Zookeeper |
| zrm zookeeper Removes a key-value from ZooKeeper (DESTRUCTIVE) |
| zruok zookeeper Checks the status of a Zookeeper instance (requires netcat) |
| zstats zookeeper Returns the statistics of a Zookeeper instance (requires netcat) |
| ztree zookeeper Retrieves Zookeeper directory structure |
+ ----------------------------------------------------------------------------------------- +
Trifecta has basic built-in support for querying and inspecting the state of Apache Cassandra clusters. To establish a
connection to a Cassandra cluster, use the cqconnect command:
core:/home/ldaniels> cqconnect dev528
From this point, you need to select a keyspace to execute queries against. To do this, use the keyspace command:
cql:cluster1:/> keyspace shocktrade
Now that a keyspace has been selected, you can execute queries against the column families (tables) found within the keyspace.
cql:cluster1:shocktrade> cql "select name, symbol, exchange, lastTrade, volume from stocks where symbol = 'AAPL' limit 5"
+ --------------------------------------------------- +
| name lasttrade exchange symbol volume |
+ --------------------------------------------------- +
| Apple Inc. 557.36 NASDAQ AAPL 14067517 |
+ --------------------------------------------------- +
You can view basic cluster information by issuing the clusterinfo command:
cql:cluster1:shocktrade> clusterinfo
+ -------------------------------------------------------------------- +
| name value |
+ -------------------------------------------------------------------- +
| Cluster Name cluster1 |
| Partitioner org.apache.cassandra.dht.Murmur3Partitioner |
| Consistency Level ONE |
| Fetch Size 5000 |
| JMX Reporting Enabled true |
+ -------------------------------------------------------------------- +
You can describe keyspaces and tables with the describe command:
cql:cluster1:shocktrade> describe keyspace shocktrade
CREATE KEYSPACE shocktrade WITH REPLICATION = { 'class' : 'org.apache.cassandra.locator.SimpleStrategy',
'replication_factor': '3' } AND DURABLE_WRITES = true;
You can retrieve the list of all the commands that Cassandra Module offers with the help (?) command.
? -m cassandra
To establish a connection to a local/remote Elastic Search peer, use the econnect command:
core:/home/ldaniels> econnect dev501:9200
+ ----------------------------------- +
| name value |
+ ----------------------------------- +
| Cluster Name ShockTrade |
| Status green |
| Timed Out false |
| Number of Nodes 5 |
| Number of Data Nodes 5 |
| Active Shards 10 |
| Active Primary Shards 5 |
| Initializing Shards 0 |
| Relocating Shards 0 |
| Unassigned Shards 0 |
+ ----------------------------------- +
Once connected, the server statistics above will be returned.
To create a document, use the eput command:
elasticSearch:localhost:9200/> eput /quotes/quote/AMD { "symbol":"AMD", "lastSale":3.33 }
+ --------------------------------------- +
| created _index _type _id _version |
+ --------------------------------------- +
| true quotes quote AMD 3 |
+ --------------------------------------- +
To retrieve the document we've just created, use the eget command:
elasticSearch:localhost:9200/quotes/quote/AMD> eget /quotes/quote/AMD
{
"symbol":"AMD",
"lastSale":3.55
}
Now let's do something slightly more advanced. Let's use Trifecta's powerful search and copy features to copy a message from a Kafka Topic to create (or update) an Elastic Search document. NOTE: Some setup steps have been omitted for brevity. See Kafka Advanced Search for full details.
elasticSearch:localhost:9200/quotes/quote/AMD> kfindone symbol == "AAPL" -o es:/quotes/quote/AAPL
{
"symbol":"AAPL",
"exchange":"NASDAQNM",
"lastTrade":109.01,
"tradeDate":null,
"tradeTime":"4:00pm",
"ask":109.03,
"bid":109.01,
"change":0.31,
"changePct":0.29,
"prevClose":108.7,
"open":108.72,
"close":109.01,
"high":109.32,
"low":108.55,
"volume":33691536,
"marketCap":6.393E11,
"errorMessage":null
}
Finally, let's view the document we've created:
kafka:shocktrade.quotes.avro/4:5429> eget /quotes/quote/AAPL
{
"symbol":"AAPL",
"exchange":"NASDAQNM",
"lastTrade":109.01,
"tradeDate":null,
"tradeTime":"4:00pm",
"ask":109.03,
"bid":109.01,
"change":0.31,
"changePct":0.29,
"prevClose":108.7,
"open":108.72,
"close":109.01,
"high":109.32,
"low":108.55,
"volume":33691536,
"marketCap":6.393E11,
"errorMessage":null
}
Please note we could also use any of the Kafka message retrieve commands (kget, kfirst, knext, kprev and klast)
to copy a Kafka message as an Elastic Search document. See the following example:
kafka:shocktrade.quotes.avro/4:5429> kget -o es:/quotes/quote/AAPL
Sometimes we need to copy a set of messages, and copying them one-by-one can be tedious and time-consuming; however, there
is a command for just this sort of use-case. The copy command can be used to copy messages from any Avro- or JSON-capable
input source (e.g. Kafka or Elastic Search) to any Avro- or JSON-capable output source. Consider the following example.
Here we're copying messages from a Kafka topic to an Elastic Search index using the symbol field of the message as the
ID for the Elastic Search document.
es:localhost:9200/> copy -i topic:shocktrade.quotes.avro -o es:/quotes/quote/$symbol -a file:avro/quotes.avsc
Once the operation has completed, the copy statistics are displayed:
es:localhost:9200/> Job #1845 completed (use 'jobs -v 1845' to view results)
+ -------------------------------------------------- +
| runTimeSecs records failures recordsPerSecond |
+ -------------------------------------------------- +
| 27.0 3367 0 143.3 |
+ -------------------------------------------------- +
Let's start by connecting to a MongoDB instance:
mongo:mongodb$> mconnect dev601
Next, let's choose a database to work in:
mongo:mongodb$> use shocktrade
Finally, let's retrieve a document. In this example, we'll retrieve a stock quote for Apple Inc. (ticker: AAPL)
mongo:mongodb$> mget Stocks { "symbol" : "AAPL" }
{
"_id":{
"$oid":"51002b2d84aebf0342cfb659"
},
"EBITDA":5.913E10,
"active":true,
"ask":98.77,
"askSize":null,
"assetClass":"Equity",
"assetType":"Common Stock",
"avgVolume":null,
"avgVolume10Day":59306900,
"avgVolume3Month":54995300,
"baseSymbol":null,
"beta":1.03,
"bid":98.76,
"bidSize":null,
"bookValuePerShare":20.19,
"businessSummary":"\n Apple Inc. designs, manufactures, and markets personal computers and related personal computing and mobile communication devices along with a variety of related software, services, peripherals, and networking solutions. The Company sells its products worldwide through its online stores, its retail stores, its direct sales force, third-party wholesalers, and resellers.\n ",
"change":-0.42,
"change52Week":44.37,
"change52WeekHigh":null,
"change52WeekLow":null,
"change52WeekSNP500":16.41,
"changePct":-0.42,
"cikNumber":320193,
"close":98.76
}
To view all of the MongoDB commands, use the -m switch and the module name (mongodb in this case):
mongo:mongodb$> ? -m mongodb
+ ------------------------------------------------------------------ +
| command module description |
+ ------------------------------------------------------------------ +
| mconnect mongodb Establishes a connection to a MongoDB cluster |
| mfindone mongodb Retrieves a document from MongoDB |
| mget mongodb Retrieves a document from MongoDB |
| mput mongodb Inserts a document into MongoDB |
| use mongodb Sets the current MongoDB database |
+ ------------------------------------------------------------------ +