Windows support #5
Comments
|
Spent some time in Windows today trying to get my head around the issues involved here. Not as straightforward as I hoped unfortunately.
And that's all I have for now. Would be happy for others to pitch in here because this isn't a very high priority for me. |
|
someone is writting a pouch db layer to use your levelup code. its over here: https://github.com/chesles/pouchdb |
|
OK peeps, the real solution to this is to simply use libuv since we have direct access to it anyway! I've already completed the basics of a leveldb port to libuv but unfortunately it requires Node 0.9 because of a required feature only introduced to libuv a month ago. So, maybe by the time 0.8 comes to an end we'll have proper Windows support in LevelUP. |
|
Hey that's great news! |
|
Awesome! Could you create an unstable branch with Node.js 0.9? This way we could start testings in our scripts :) |
|
I'll keep you informed here when I have something interesting, I have a branch on the go but it's only a start. |
|
A quick update on this. I have a libuv port.h working across platforms, but unfortunately there's a lot more work for an env.cc required for Windows/libuv than I suspected. There's even a few things we can't do with libuv and will have to be done manually for different platforms. |
|
it looks like Ben closed the LubUV issue requesting a different API to file seeking. So whats the way forward for getting a windows port now ? |
|
yeah, it'll just mean an |
|
i see. Of course i would want to eliminate the need for the conditionals too. If you can get a build going in travis woudl be awesome. I am also looking for libraries to allow levelup to be distributed like i see no reason why we cant get something like riak working On 10 February 2013 12:19, Rod Vagg notifications@github.com wrote:
Contact details: |
|
For distribution you can check out level-scuttlebutt by dominictarr. Re riak: we mustn't forget that leveldb is just an unopinionated storage engine. There are versions or riak that use leveldb though. |
|
thanks I know what you mean. I agree its great to keep levelup as an I was not suggesting we implement distributed storage in levleup. But more I see that scuttle butt has map reduce to allow many storage instances to But i am more thinking of data replication, key ring based storage, leveldb it would be really great to add a list of these to the main level db web On 10 February 2013 12:36, Julian Gruber notifications@github.com wrote:
Contact details: |
|
Ok i correct myself. you have the Modules page in the wiki :) On 10 February 2013 13:04, Ged Wed gedw99@gmail.com wrote:
Contact details: |
|
level-scuttlebutt takes one opinionated approach. |
|
I am building a 3D cad modelling system and tons of json data I need to Originally I used pouchdb and couxhdb. But I want to replace all of it with level dB. G
|
|
@rvagg Is there a list of changes required before Windows support is working? I want to use LevelDB for a project I'm working on, but cross-platform support is a promise I'd like to keep. I'd be willing to help put some time into this if needed. There will be a slight learning curve for me as I get up to speed. If you're looking for help, hit me up! |
|
Pretty much all of this needs to be implemented. See the POSIX version. Tho we're using libuv to do it so some of it is not as hard as it looks. |
|
Great! In the meantime, I've started working on a Bitcask clone that I'm hoping to keep 100% JavaScript. For the project I'm working on, I should be able to offer both strategies (Bitcask clone, LevelDB) once cross-platform compatibility is complete for LevelDB. Once I'm done with the Bitcask-y stuff, I should have some availability to look at this. (I don't think it will take much longer. It's delightfully simple.) Thanks again for the info. I'll be on the lookout for that commit. |
|
@kevinswiber excellent! reading the document you link, bitcask sounds architecturally very similar to leveldb - except that since it uses an in memory hash-table as an index it doesn't seem like it would support range queries - just straight gets. Is that correct? Are the inactive files stored sorted or unsorted? |
|
@dominictarr The keys are all unsorted, so range queries aren't as easy. To accomplish this with Basho's Bitcask implementation, we'd have to iterate over the keys until all matches are found or the end is reached. For my clone-ish implementation, I'm thinking of doing the key-sort (perhaps in the hint file), to hopefully reap the SSTable benefit in this design. Then range queries should perform better. (We're way off-topic, though. I'm @kevinswiber on Twitter and kswiber at gmail if you want to take it off the levelup issues list.) |
|
Hey Kevin are you thinking of building a RIAK like system on top of G On 12 March 2013 14:47, Kevin Swiber notifications@github.com wrote:
Contact details: |
|
@gedw99 Yeah, something like that. Long-term, I'm planning to build a distributed key-value database that can be easily embedded in Node.js apps. My current use case is to add built-in caching support for an HTTP proxy and origin server I'm building. Some constraints are:
Thinking down the road, I'll give @dominictarr's Scuttlebutt implementation a go for gossiping nodes. But virtual bucket distribution, gossip protocol, consistent hashing, vector clocks, hinted handoff, anti-entropy measures... none of these matter without a solid database structure. So that's the first priority. I'd prefer to default to a 100% JavaScript database as the default, while allowing folks to branch out to other implementations as needed (such as LevelDB). |
|
Keven, thats exactly what i have been wanting to do, but no time. I reckon i can help test and do some bug fixing once the base architecture One thing that i feel is important to incorporate is offline browser
is this something on your roadmap too i wonder ? On 12 March 2013 16:56, Kevin Swiber notifications@github.com wrote:
Contact details: |
|
@gedw99 Yep. The idea is to remain decentralized, peer-to-peer. Availability first, consistency second. Hit me up on Twitter or e-mail if you want to talk further. My Issues list etiquette is currently suspect. ;) |
|
@kevinswiber @gedw99 I assure you that such discussions are infact on topic in a levelup issues! as it's pretty much become a clearing house for such things I started working on a pure js leveldb clone, with the leveldown api My plan was to use a new line separated json format for simplicity, and then swap it out with something binary compatible with leveldb later. I think @mixu also needs to be a part of this discussion! |
Looks like a normal levelup issue to me. |
|
@dominictarr Awesome. If you can throw your thoughts into Issues for json-sst and json-logdb, I'd love to take a look. For my Bitcask effort (which I just started yesterday), I already have parts of the in-memory keydir and the active file puts/gets/deletes working. My next step is to look at log file cycling, merging, and hint file management. It will probably take more studying and tinkering than real development time (I'm hoping). I'm not sure there will be anything reusable in there, but it should be an interesting science experiment we can examine. |
|
/cc @chilts cause he's also working in this area. https://github.com/chilts/level-dyno |
|
Of course, this "Windows Support" issue is the wrong place for me to describe the project, but the short of it is to try and replicate similar functionality to DynamoDB. I think it's different to @dominictarr's level-scuttlebutt since each server won't hold 100% of the data. Also, the algorithm for the eventual consistency is different. Anyway, just a work in progress at the moment and level-dyno is just a small beginning. :) |
|
For those interested in the Bitcask clone I mentioned, I open-sourced the start of it here: I have some plans for it that stray from Bitcask (such as indexing map reduce operations). Right now, basic get, put, and remove functionality is there. You can set a maxFileSize, which will create new data files based on growth. All keys are stored in memory on medea.open. The keydir holds information regarding the value's data file and offset. You can do basic (non-cached) map-reduce operations using medea.mapReduce. I haven't implemented the separate merge process yet that cleans up the log files, but I thought I'd open source it sooner than later. It's usable even without that at the moment. Unlike LevelDB, Medea stores key-value pairs unsorted. I'm planning to add sorted index support using map-reduce operations sometime in the future. That should allow range queries and other goodies that are slightly better performance-wise. Cheers. |
|
@kevinswiber if you get sorting working properly you could plug in as a backend to levelup. From 0.7 we'll have a |
|
@kevinswiber what advantage comes from not sorting? what do you think? |
|
I think the primary advantage is in a lack of code complexity. I believe FWIW, Basho is actually promoting LevelDB as a backend storage for Riak That said, I'd love to branch Medea with LSM trees and SSTables for a Sent from my iPhone On Mar 18, 2013, at 8:37 PM, Dominic Tarr notifications@github.com wrote: @kevinswiber https://github.com/kevinswiber what advantage comes from not what do you think? — |
|
Bitcask also puts everything into RAM too doesn't it? so you hit ceilings pretty quickly. LevelDB has a lot more flexibility around caching I think. |
|
The entire key set is in RAM. Keys in memory point to files and offsets for Sent from my iPhone On Mar 18, 2013, at 9:09 PM, Rod Vagg notifications@github.com wrote: Bitcask also puts everything into RAM too doesn't it? so you hit ceilings — |
|
Gents, For the sake of development speed, I started off using a JavaScript object as a hash table for key:file/offset pairs in memory. It turns out this hits V8 pretty intensely and slows everything down. I switched it out for a red black tree, but it's actually slower (maybe my rb tree sucks, too). Any suggestions for a JavaScript-only hash table in Node? Does something significant already exist? Also, a concern is that the hashing, inserts, resizing, etc. will be too CPU-intensive in JavaScript under heavy load. I'm hoping this isn't true. I'd love to keep it pure JavaScript for ease of deployment and future maintenance. Thanks. |
|
@kevinswiber How does you red black compare with these ones https://github.com/scttnlsn/redblack.js and https://github.com/vadimg/js_bintrees ? |
|
@sandfox Thanks for the tips. Redblack.js was quite a bit slower, and I couldn't get the js_bintrees RBTree to find any keys. Not sure what's going on there. My RedBlackTree implementation might be all right. I'm not sure my assessment of the problem was correct. I don't think the V8 hash table is actually performing that poorly at the numbers I'm using. The profiler shows a lot of time spent in ScavengeObject, which I believe is used by the GC. Maybe I'll play with the bufferizing trick you mentioned. Thanks! |
|
you can turn off garbage collection in v8 i think. Or at least control it On 20 March 2013 16:47, Kevin Swiber notifications@github.com wrote:
Contact details: |
|
Everyone: Thanks for the great discussion around this. I just pushed v0.0.2 to NPM. @juliangruber has a great repo showing benchmark comparisons. Thanks to his recent work, Medea just made the list: https://github.com/juliangruber/multilevel-bench Snippet: Here are some numbers from my machine: Intel Core i5, 8GB DDR3 RAM, Node v0.10.1: I'm sure all these numbers will change over time, but I'm pretty happy with this for now. It's good enough to fit my use case (Web caching). Cheers! |
|
Check this out peeps see windows branch on LevelDOWN and current rvagg/leveldb libuv-port branch. No snappy yet but I don't imagine that to be a problem. This also requires Node 0.10+ cause Lots of cleanup to do and I have to make sure the compile works on non-Windows platforms, but we're getting close. Distributing binaries is a whole different issue but we can think about that later. |
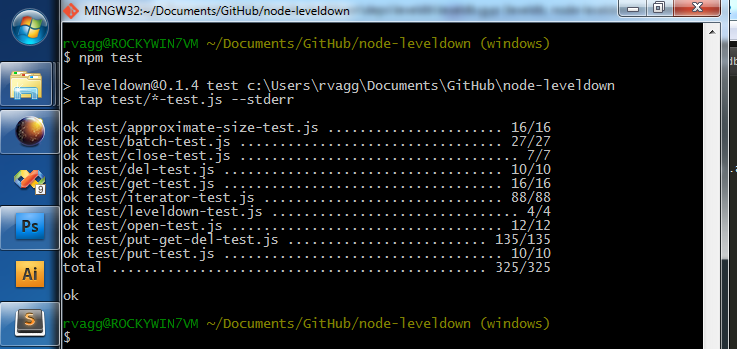
|
Thanks. Ged
|
|
@rvagg Excellent! I might fire up my dusty Windows 7 VM and check it out. How does the performance compare running on libuv vs LevelDB's built-in POSIX support? I'd be interested in seeing some metrics. This is great. |
|
Ragg. Can you give us a download link where we can get the binary. Want to
|
|
@kevinswiber I have no idea about performance, I'd love someone to try and come up with some benchmarks. The bits that libuv are doing are pretty simple and are just providing a wrapper around some thread stuff. The stuff that will matter more is code I've pulled in from here. You can have a look at it here. There's some things in there that I'd rather bind to libuv but that can wait for another day. It's also possible that there are things in there that could be done more efficiently but I haven't spent much time looking over it. I'd be happy for anyone else that wants to contribute to have a look over it! My suspicion from seeing the speed of the tests is that it's not going to live up to posix performance, but I may just be observing process start/top and file create/delete overhead. It's also possible that my Window VM is having trouble performing well (and I'm not running it on an SSD, which I normally use on my Linux machines). @gedw99 I don't have binaries for you, I'm thinking that post-release I may be able to produce 64 and 32 bit bundles for download that you can put in your node_modules directory, as a stop-gap. But not yet. I recommend that you get set up for running node-gyp on your machine then you'll be able to compile other native addons. The components are all free but it can be a bit of a pain on 64 bit machines. The details are all here, there's nothing particularly difficult, it's just annoying. |
|
LevelUP@0.7.0 now uses LevelDOWN@0.2.x which has Windows support. See the top of the README for instructions on what you need in order for it to compile when you |
|
awesome stuff ! |
(Was "Windows build fails", ed:RV)
Actual NPM error log:
https://gist.github.com/3730932
I just found something about compiling leveldb in Windows:
https://groups.google.com/d/msg/leveldb/VuECZMnsob4/tROLqJq_JcEJ
And here are the aditional packages that are needed:
http://www.boost.org/users/download
And some more information from official source:
http://code.google.com/p/leveldb/source/browse/WINDOWS?name=windows
The text was updated successfully, but these errors were encountered: