✨ 😅 Is possibale to use the ChatGPT of OpenAI to train this ChatGPT? #23
Comments
|
Its forbidden by the ToS.
…On Thu, Feb 2, 2023, 05:48 YonV1943 曾伊言 ***@***.***> wrote:
OpenAI used *40 people* when training their own chatGPT, and the
annotation process lasted for *3 months*.
It is difficult for our open source community (github) to reproduce the *Reinforcement
Learning by Human Feedback (RLHF)* environment for this work, as OpenAI
also employs 40 people to complete human feedback.
However, we can *treat OpenAI's web version of chatGPT as human annotated
data* for us 😅 when training our own chatGPT.
—
Reply to this email directly, view it on GitHub
<#23>, or
unsubscribe
<https://github.com/notifications/unsubscribe-auth/ADHLOZGFVYESLMIZA5GIZX3WVM4ANANCNFSM6AAAAAAUORK4DU>
.
You are receiving this because you are subscribed to this thread.Message
ID: ***@***.***>
|
|
You means that "it is forbidden by the Terms of Service (ToS) of OpenAI ChatGPT". Maybe the open source community can have other ways to train chatGPT, especially the RL Human Feedback part in Step 2. |
Using NEOX for RLAIF as a substitute for RLHF may be a plausible solution. Anthropic showed promising results with synthetic data generation. The nonprofit Ought was able to successfully train a reward model with RLAIF for summarization with NEO (1.3b). I am working with CarperAI and a small group to open-source a few datasets as part of a bigger project relating to this. Harrison Chase and John Nay of LangChain also offered to help. We plan to generate synthetic data for different tasks relating to SFT, RLAIF, CoT, and training the reward models. |
|
Can you point me to where they have those results? I only saw the paper
…On Fri, Feb 3, 2023 at 2:57 PM Enrico Shippole ***@***.***> wrote:
You means that "it is forbidden by the Terms of Service (ToS) of OpenAI
ChatGPT". Thank you for your response to this issue.
Maybe the open source community can have other ways to train chatGPT,
especially the RL Human Feedback part in Step 2.
Using NEOX for RLAIF as a substitute for RLHF may be a plausible solution.
Anthropic showed promising results with synthetic data generation.
—
Reply to this email directly, view it on GitHub
<#23 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AYKSSRBPGGJISEOA2LGRZTLWVVWK7ANCNFSM6AAAAAAUORK4DU>
.
You are receiving this because you are subscribed to this thread.Message
ID: ***@***.***>
|
|
Please check this |
|
Thanks a lot!
…On Sun, Feb 5, 2023 at 5:45 AM Muhammad AL-Qurishi ***@***.***> wrote:
Please check this
https://github.com/LAION-AI/Open-Assistant
—
Reply to this email directly, view it on GitHub
<#23 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AYKSSRCZOKHQ2OTJJ6WOIODWV6HGDANCNFSM6AAAAAAUORK4DU>
.
You are receiving this because you commented.Message ID:
***@***.***>
|
|
It is possibale to use the ChatGPT of OpenAI to train our own ChatGPT.
|
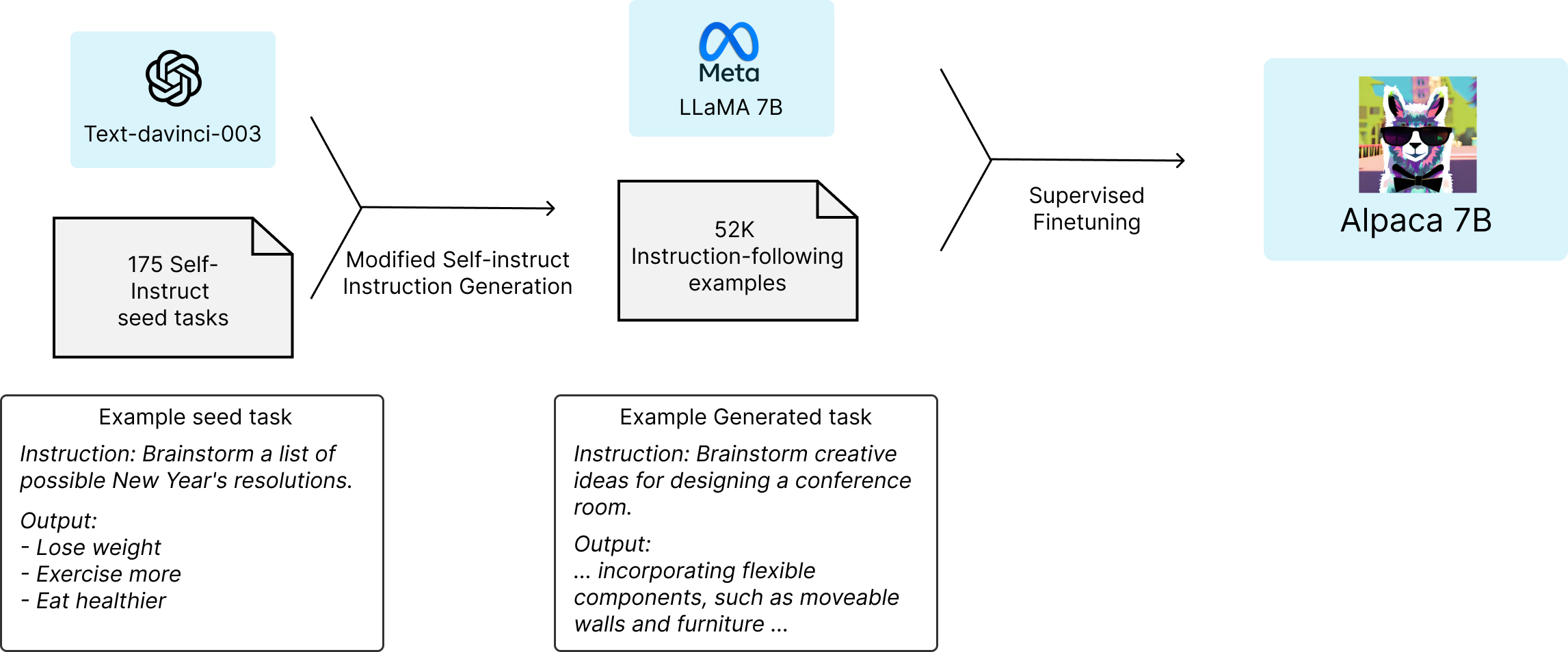
Thanks a lot for your insightful sharing :) Can you explain please how the method you used for training is compatible with ChatGPT and LLAMA 2 ToS? |
OpenAI used 40 people when training their own chatGPT, and the annotation process lasted for 3 months.
It is difficult for our open source community (github) to reproduce the Reinforcement Learning by Human Feedback (RLHF) for this work, as OpenAI also employs 40 people to complete human feedback.
However, we can treat OpenAI's web version of chatGPT as human, who can annotate data ✨ for us when training our own chatGPT.
This sounds a bit funny😅, but I currently think it's doable.
@lucidrains
The text was updated successfully, but these errors were encountered: