Ziploq is a lightweight message-synchronization device with ultra-high performance. It lets you quickly merge data
from any number of data sources reactively, without having to reach for large frameworks such as Project Reactor or
Akka Streams. It doesn't matter whether the input data is ordered or not, the output will always be ordered! (In case
of data from external systems: data transmission delays and disconnections are all handled automatically
out-of-the-box, too!)
Ziploq is built with infinite real-time data sequences in mind, but works just as well for in-memory datasets. This design results in a low memory footprint and a high message throughput. With this lib, it's easy to set up pipelines capable of handling millions of transactions per second ("tps") on a regular desktop computer (i5 6600)!
For your convenience, Ziploq also provides simple strategies for handling backpressure on both Producer and Consumer side.
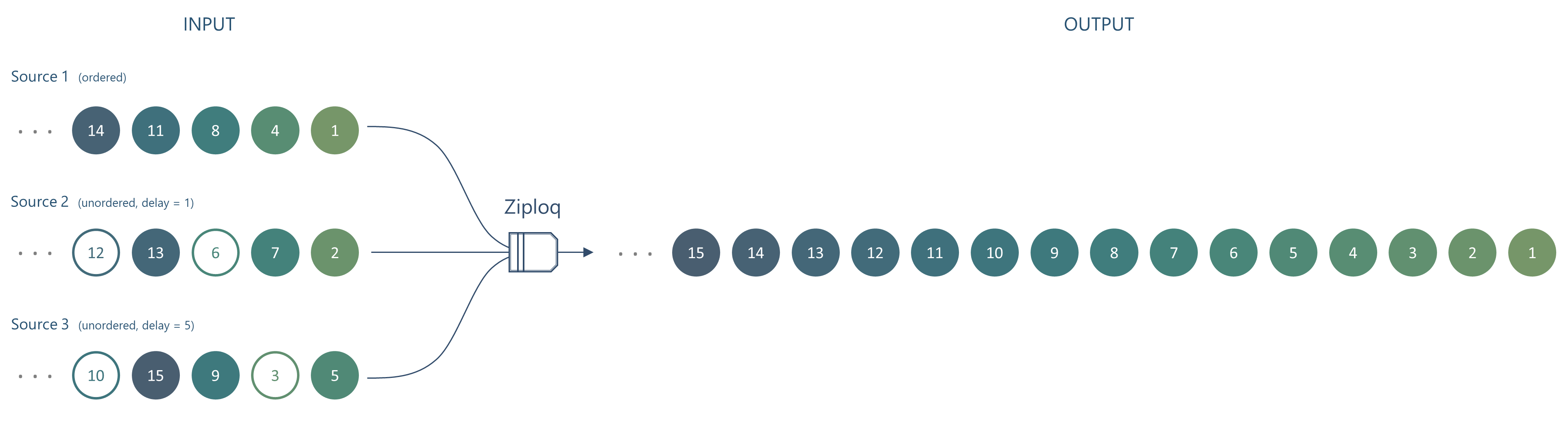 Image showing merging of 3 data sources using Ziploq. The output is ordered even though some of the input isn't.
Image showing merging of 3 data sources using Ziploq. The output is ordered even though some of the input isn't.
For a complete code example, please refer to Code Example.
Create a new Ziploq instance using the factory
Ziploq<MyMsg> ziploq = ZiploqFactory.create(msgComparator);After registering your data sources, retrieve the merged output as a regular Java Stream to set up your reactive
data processing pipe
ziploq.stream()
//map, filter, and so on....
.forEach(result -> doSomethingUseful(result));The stream will emit messages when available, or otherwise block. When complete() has been called for all input
consumers and all messages have been processed, the Stream will terminate.
It is also possible to retrieve the ordered output by using old-school methods take() and poll().
If you've already got all data from a source available in-memory you can register the full ordered dataset directly
with the Ziploq instance
ziploq.registerDataset(dataset, toTimestamp, name);Register a new ordered input source
SynchronizedConsumer<MyMsg> consumer = ziploq.registerOrdered(capacity, backPressureStrategy, name); or an unordered input source
SynchronizedConsumer<MyMsg> consumer = ziploq.registerUnordered(businessDelay, capacity, backPressureStrategy, name, comparator)); Feed messages into the Ziploq machinery by calling consumer.onEvent(msg, businessTs) for each incoming message. When
no more messages are available, call complete().
If you're developing a real-time application that has to keep pushing messages even when some input data sources are
not producing any -- ZipFlow is the way to go. To create an instance, do exactly as before but add a systemDelay
parameter:
ZipFlow<MyMsg> zipflow = ZiploqFactory.create(systemDelay, msgComparator);When registering input data sources with ZipFlow you'll get the turbo-charged flavor of SynchronizedConsumer called
FlowConsumer. These consumers use a vector clock consisting of both business time and system time, where the latter
is used for heartbeating functionality. This allows messages to be dispatched through the synchronizer even at times
when some input sources are silent, as long as they progress their system time.
To publish updates for the system clock at times when no new messages are available, simply call
consumer.updateSystemTime(systemTs).
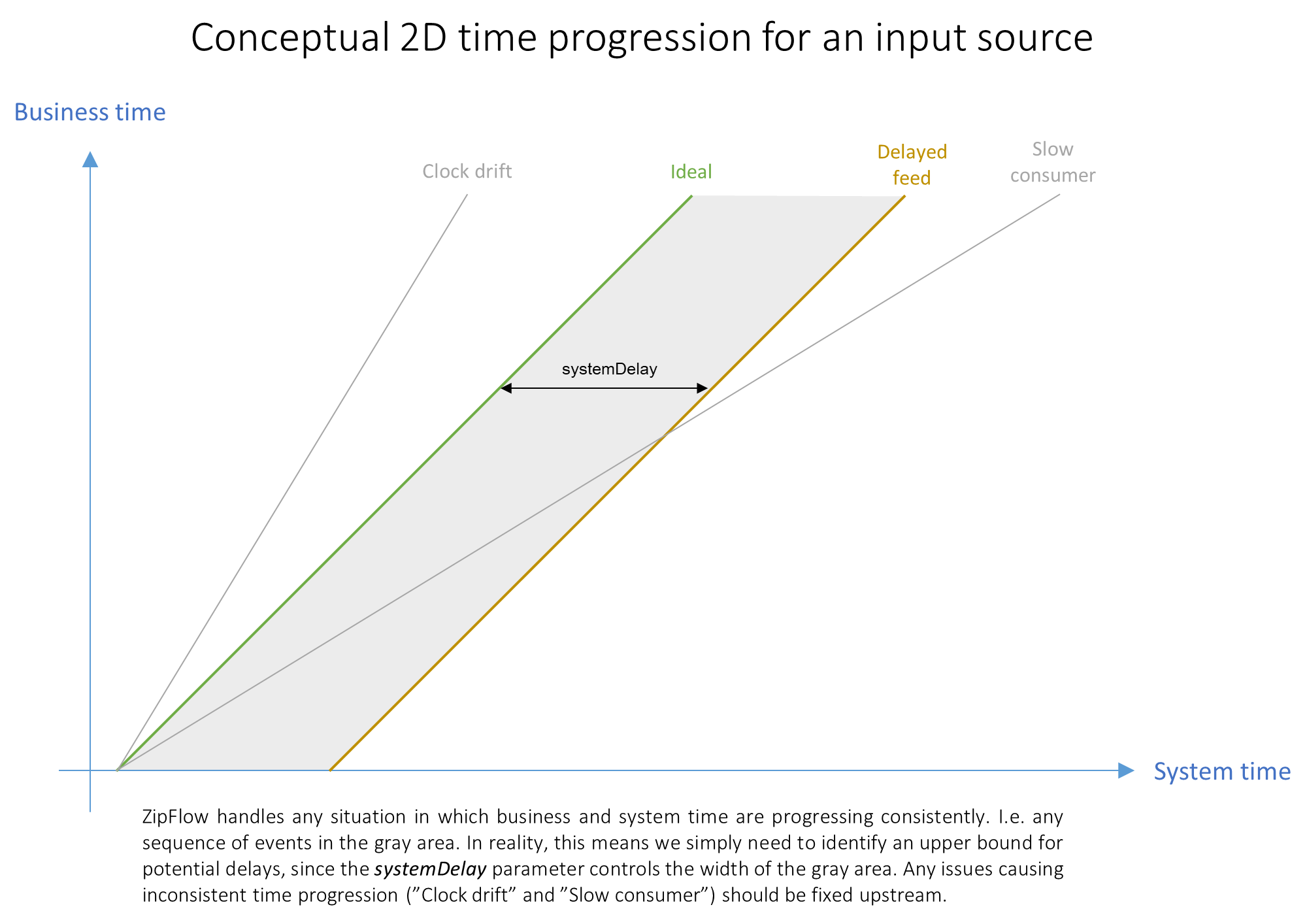
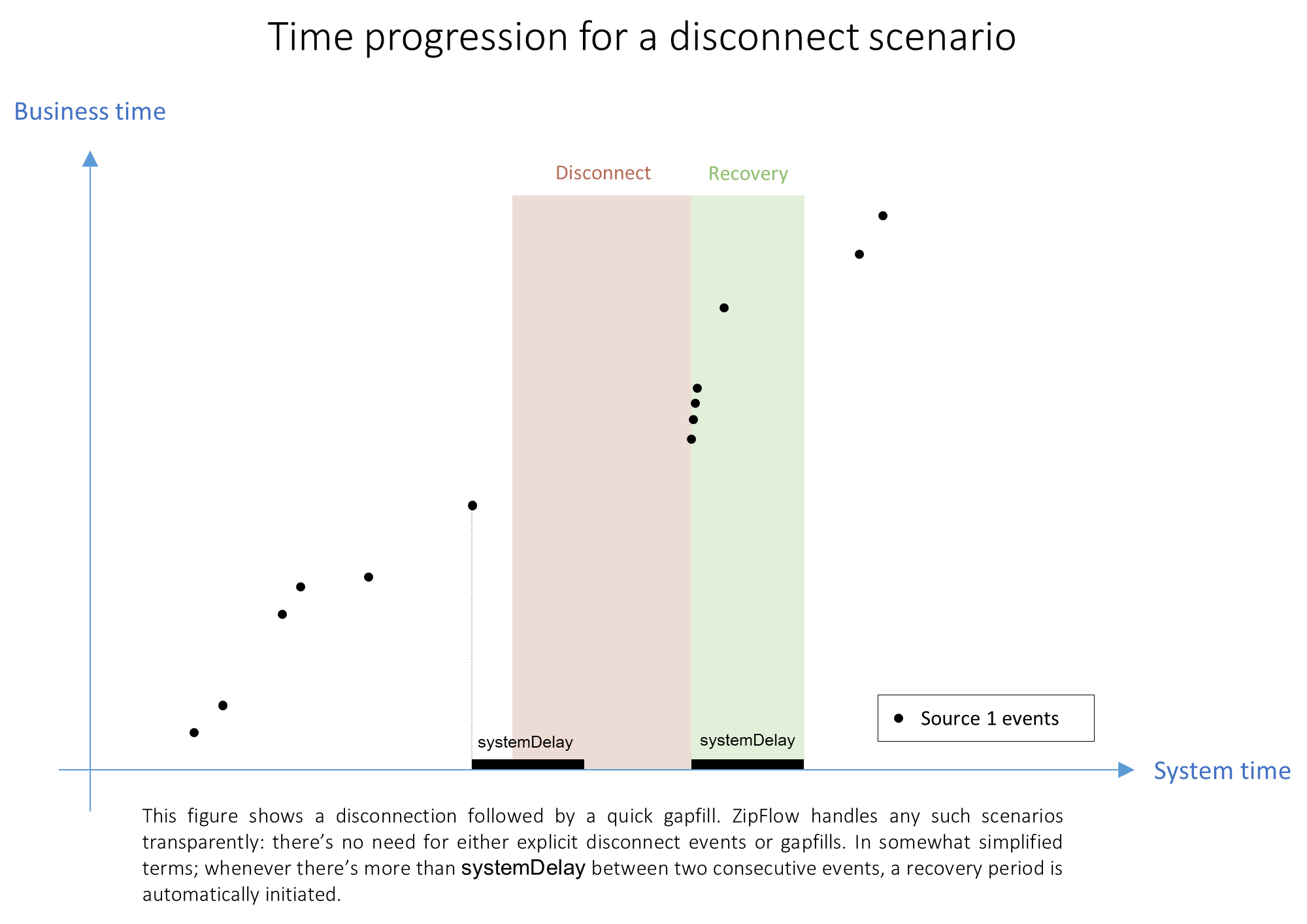
Reasoning about message sequences becomes much easier when looking at 2D plots of business time vs system time. The following chart illustrates standard scenarios seen from a vector clock perspective.
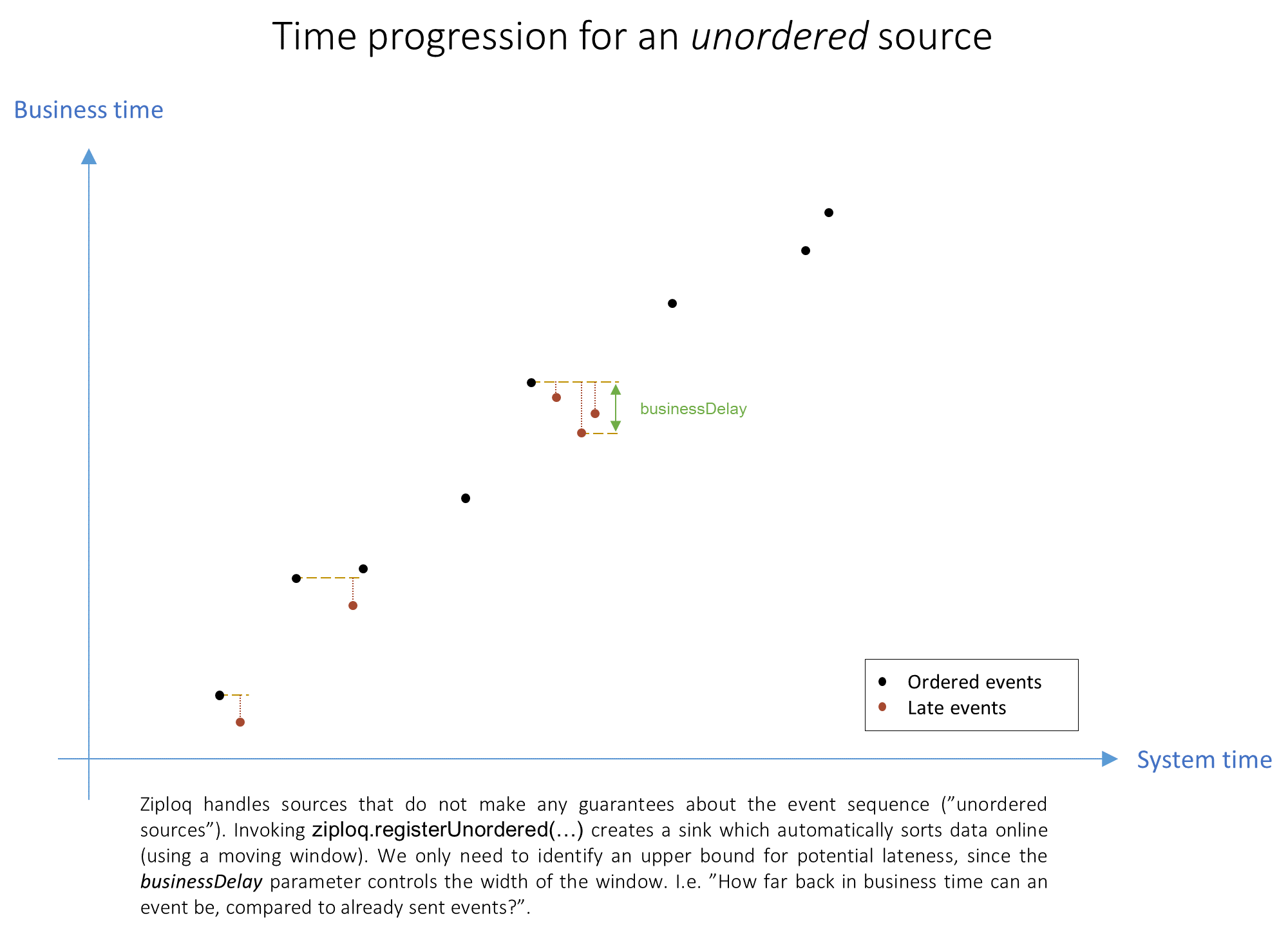
Sorting of unordered data is carried out online. You only need to
know how much delayed messages can be (at most) in terms of the business clock compared to previously processed
messages from the same source. Setting the businessDelay to, for example, 100ms means we never expect to see a
message with business timestamp T-101 coming in after a message from the same source with business timestamp T
has already been processed.
Most of the time, we recommend sourcing the business clock from a global business clock (epoch millisecond timestamps). However, business time is completely decoupled from system time, so any integer (64-bit long), such as a global sequence number, can be used. The key is that messages are always being sequenced first with respect to the business clock. In high-frequency applications, secondary sorting criteria can easily be configured to provide sub-millisecond (total) ordering.
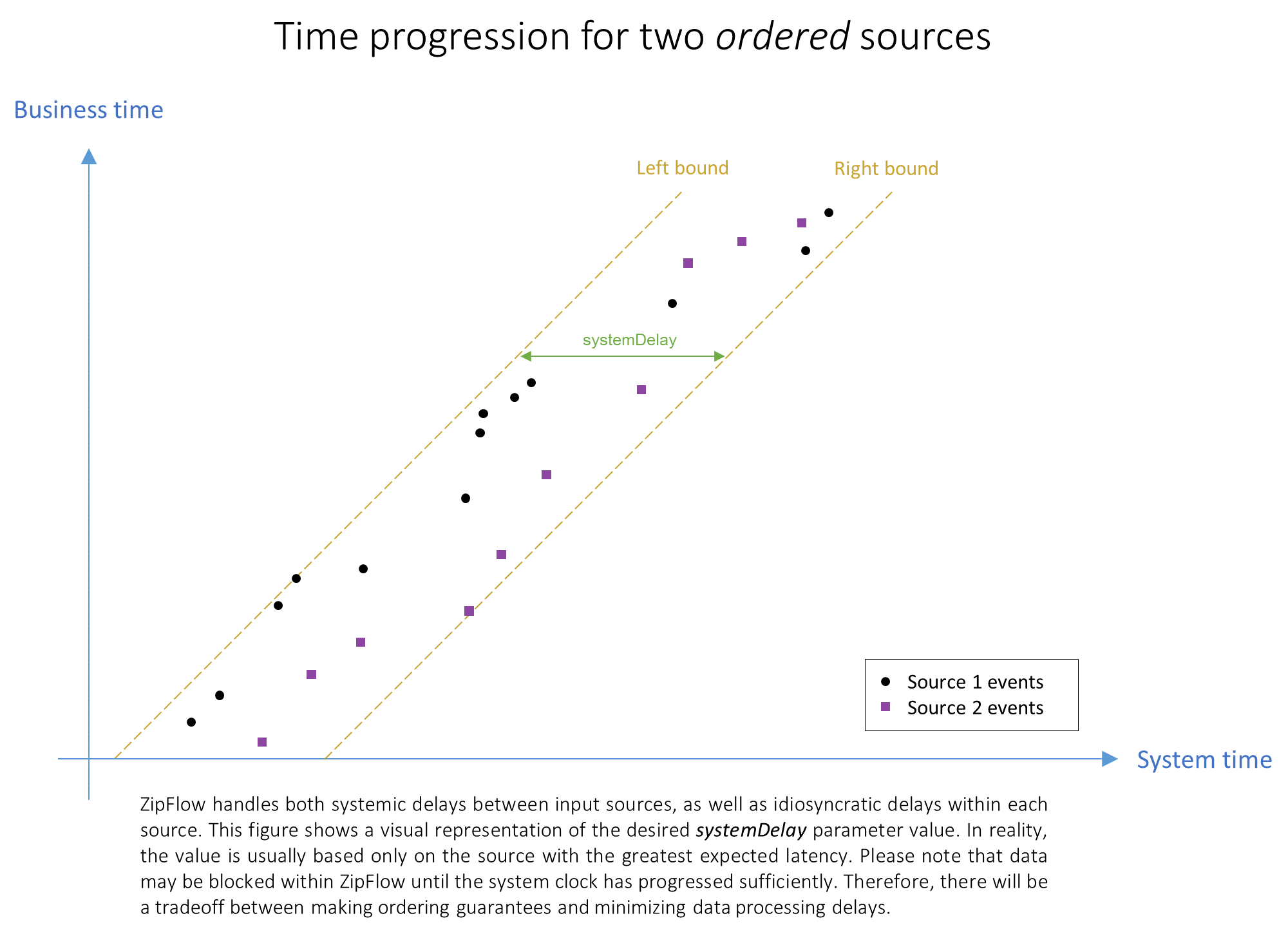
ZipFlow has been designed with real-time processing in mind. Therefore, a secondary clock has been introduced, which
is called the system clock. Making each producer continuously publish their system time allows for advancing the
message sequence even at times when input sources are silent. This mechanism can be considered a modern form of
heartbeating; in which all sources drive event time together. The heartbeating frequency is governed by the
systemDelay parameter; during normal operation it is expected that system time is progressed in steps not larger than
the configured delay.
When dealing with real-time processing, the system clock should be driven by wall-clock time. In this way, it's just a matter of configuration when it comes to how much real-time delay is acceptable within your application.
In many real-world applications the data is coming from external data sources. In case a data connection goes down, the producer should stop publishing system time. Instead, simply wait until the connection has been re-established and then start publishing messages again. From a vector clock perspective this might involve a jump in system (wall-clock) time, but no immediate jump in business time. Ziploq will automatically detect such a jump in the producer's system clock and initiate a recovery grace period for that producer (in system time) to complete its recovery and, thus, guarantee output sequencing is not impacted.
This library uses SLF4J for logging, so please make sure you've got your logger configured to handle this. Log entries will be written if any input sources break the ordering contract resulting in out-of-sequence message flows.
By default, only a non-decreasing business timestamp sequence is enforced. If you'd want the framework to also check
that the input data sequence is compliant with the configured Comparator (if any) set the system property
ziploq.log.comparator_compliant=true.
The framework also warns when the blocking action to wait for output has not returned within a certain time-frame. If
this happens, information about the sources that are silent--causing the block--will be provided. The default timeout
is 120000 milliseconds (2 minutes) and can be adjusted with the system property ziploq.log.wait_timeout.
Creating a Ziploq instance, registering one dataset and two ordered input data producers and then operating on the
merged, ordered output is done in the following way
public static void main(String[] args) {
//Create ziploq
Comparator<MyMsg> tiebreaker = Comparator.comparing(MyMsg::getMessage);
Ziploq<MyMsg> ziploq = ZiploqFactory.create(tiebreaker);
//Register dataset
List<MyMsg> dataset = loadDataset("Dataset");
ziploq.registerDataset(dataset, MyMsg::getTimestamp, "Dataset");
//Register input data producers
Producer producerA = new Producer("Producer-A",
ziploq.registerOrdered(128, BackPressureStrategy.BLOCK, "Source-A"));
Producer producerB = new Producer("Producer-B",
ziploq.registerOrdered(128, BackPressureStrategy.BLOCK, "Source-B"));
//Start data producers
producerA.start();
producerB.start();
//Retrieve an ordered output stream
ziploq.stream()
.map(Entry::getMessage)
.map(MyMsg::getMessage)
.forEach(System.out::println);
}
static List<MyMsg> loadDataset(String id) {
return IntStream
.range(0, 1001)
.mapToObj(i -> new MyMsg(id+"-"+i, i))
.collect(Collectors.toList());
}In the simplest case, consider Producer and MyMsg classes as per below
class Producer extends Thread {
private final SynchronizedConsumer<MyMsg> consumer;
private final String id;
public Producer(String id, SynchronizedConsumer<MyMsg> consumer) {
this.id = id;
this.consumer = consumer;
}
@Override
public void run() {
IntStream
.range(0, 1001)
.mapToObj(i -> new MyMsg(id+"-"+i, i))
.forEach(msg -> consumer.onEvent(msg, msg.getTimestamp()));
consumer.complete();
}
}class MyMsg {
private final String message;
private final long timestamp;
public MyMsg(String message, long timestamp) {
this.message = message;
this.timestamp = timestamp;
}
public String getMessage() {
return message;
}
public long getTimestamp() {
return timestamp;
}
}Running this program will output messages from 0 to 1000. The tiebreaker comparator guarantees that "Dataset"
messages come first, then "Producer-A" messages and last "Producer-B" messages when timestamps are equal.
Dataset-0
Producer-A-0
Producer-B-0
Dataset-1
Producer-A-1
Producer-B-1
...
Dataset-999
Producer-A-999
Producer-B-999
Dataset-1000
Producer-A-1000
Producer-B-1000
Remember that we had registered both input source with capacity set to '128' and BackPressureStrategy.BLOCK? This
guarantees none of the consumers will ever have held more than 128 messages in memory (at the same time) when the
input data was merged. Instead, if a consumer's internal buffer were to reach 128 messages its onEvent(...) method
would block until the downstream catches up, ensuring that we never go out-of-memory.
This might not be a concern when only passing a few thousand Strings through the pipe, but just imagine scenarios in which we're processing millions or even billions of rich messages!
Feel free to be creative! The class SyncQueueFactory allows direct creation of Multi-Producer Single-Consumer
(MPSC) queues, which can be useful as buffers, etc. For example, queues from createUnordered(...) comes with built-in
online sorting for queued messages based on a vector clock. All queues are lock-free concurrent MPSC queues built on
top of data structures from the lightning-fast JCTools library.
Feel free to reach out if you have any questions or queries! For issues, please use Github's issue tracking functionality.
Måns Tegling, 2019