Actualmente vivimos un crecimiento importante en lo que son los sistemas con grandes volúmenes de datos, los cuales están muchas veces desestructurados, o requieren de algún tipo de procesamientos específico para poder resolver un problema, o inferir un nuevo dato a partir de ellos.
Big Data, Machine Learning, Business Intelligence, entre otros, son términos que nos empiezan a resultar más familiares, pero que también hacen que los sistemas que debemos construir tengan requerimientos más complejos, haciendo que las arquitecturas y tecnologías “tradicionales” no sean una solución eficaz para algunos problemas que podemos comenzar a encontrar.
Bajo este abanico de tecnologías muchas veces no tenemos claro qué problema podemos atacar. Es bajo este contexto que en este artículo haremos una breve reseña sobre Storm, para entender qué hace, cómo lo hace y cómo se para con respecto a otros productos de similares características.
Según su sitio Storm es un sistema de computación en tiempo real distribuido [1]. Si yo tuviera que definirlo, podría decir que es un sistema de procesamiento distribuido, orientado a ejecución de tareas paralelas, procesando los datos como flujos.
Si buscamos por internet también podemos definirlo en función de cómo se compara con Hadoop (en el sitio marca algo como “Storm hace en tiempo real, lo que Hadoop hace en batch”), o con Spark, incluso Kafka. Esto se debe a que muchos problemas de los que atacan este tipo de frameworks son similares, o incluso se complementan para resolver problemas más complejos.
Para entender cómo Storm hace lo que dice debemos entender algunos conceptos como el de Topología.
Una Topología es un grafo acíclico dirigido donde los nodos contienen alguna lógica de procesamiento. Se denominan a estos nodos Spouts cuando son los nodos iniciales de la topología, mientras que los nodos intermedios son denominados Bolts. Estos nodos se conecta a través de Streams por los que viajan las tupas que contienen los datos de la Topología. En la siguiente imagen los Spouts quedan representados por las canillas y los Bolts por las gotas, mientras que las flechas representan los Streams entre los nodos.
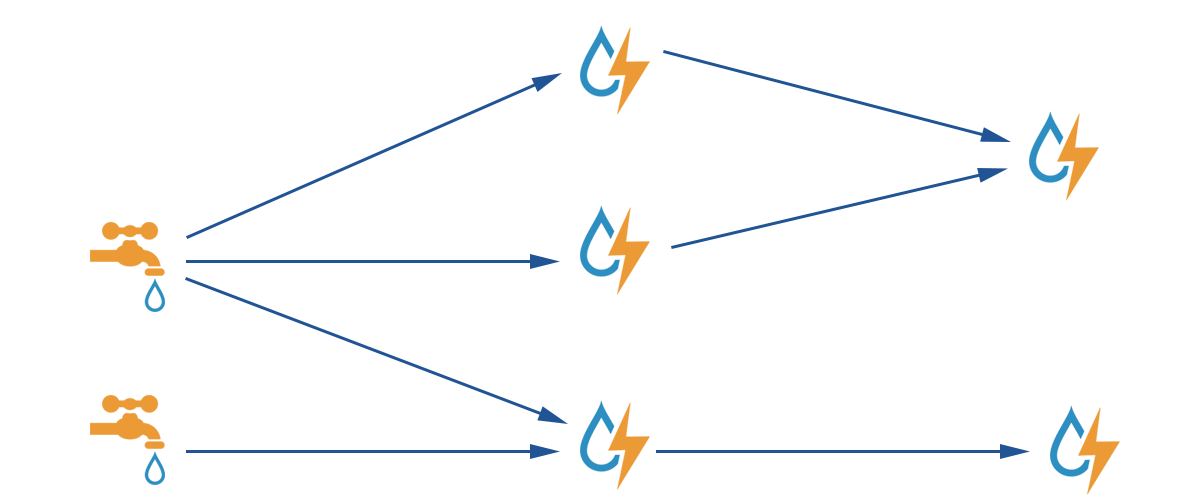
Los Spouts representados por canillas son los nodos que producen los datos de la Topología, sea conectándose a una base de datos, tomando mensajes de una cola de mensajería, u obteniendo datos desde un servicio REST. Los Spouts emitirán las tuplas (tipo de dato a través de donde se envían los mensajes dentro de la Topología). Tambien pueden ejecutar de forma paralela entre sí y de manera distribuida.
Los Bolts representados por gotas realizara algún procesamiento sobre las tuplas recibidas, emitiendo nuevas tuplas para la Topología. Estos también pueden ejecutar de forma paralela entre sí y distribuida.
Todos estos nodos del grafo se conectan a través de Streams. Un Stream es una secuencia desordenada de tuplas emitidas y procesadas de manera paralela y distribuida.
Estos Streams pueden agruparse para poder manipular como las tuplas son distribuidas entre las Tasks de un Bolt. Estas Tasks representan los hilos de ejecución de un Bolt dado definido por su nivel de paralelismo en la Topología, por lo que el agrupamiento de Streams define como las tuplas de un Stream viajan de un conjunto de Tasks a otro grupo de Tasks.
Las Topologías se ejecutan a través de uno o más Workers los cuales representan una JVM que ejecuta una o más Tasks de la Topología. Storm intentará distribuir las Tasks entre los distintos Workers del sistema de la mejor forma posible según se lo configure.
Todo esto no tiene tanto atractivo si no se garantiza al menos el procesamiento de todos los mensajes de la Topología, considerando un mensaje procesado cuando a recorrido todo el grafo de cómputo de la Topología según se haya definido.
Storm garantiza esto a través de un mecanismo de confirmación de los mensajes, la definición de timeouts de mensaje y la manipulación de mensajes repetidos, pudiendo configurar todo este comportamiento en la Topología. Queda a criterio del lector profundizar el tema ya que existen muchas implementaciones y mecanismos para manipular el comportamiento de un Stream.
Se han manejado una cantidad importante de conceptos que pueden ser confusos, por lo que aplicaremos los conceptos anteriormente descritos en un ejemplo. En este repositorio encontraremos un ejemplo que pueden ejecutar [2].
Para ejecutar este ejemplo solo necesitamos Java 1.8 o superior.
Luego de haber clonado el repositorio podemos ejecutar la topología del ejemplo con el comando "./gradlew run".
Antes de ejecutar entendamos un poco que va a realizar el ejemplo. En el ejemplo tenemos un Spout que genera frases simulando un flujo interminable de frases y luego una serie de Bolts que procesan dichas frases para contar las palabras de interés que se van produciendo en el flujo.
Para realizar esto se crea un Spout que es el encargado de emitir las frases (SendPhrasesSpout), un Bolt que se encarga de tomar un frase y partirla es sus palabras (PhraseToWordsBolt), un Bolt que se encarga de normalizar las palabras pasándolas todas a minúsculas (ToLowerCaseBolt), otro Bolt que quita las palabras que no nos interesan contar (FilterWordsBolt) y un Bolt final que cuenta cada palabra (WordCountBolt). Esta topología queda definida en la clase main StormExampleMain como se muestra a continuación.
final TopologyBuilder topologyBuilder = new TopologyBuilder();
topologyBuilder.setSpout("SendPhrasesSpout", new SendPhrasesSpout(), 10);
topologyBuilder.setBolt("PhraseToWordsBolt", new PhraseToWordsBolt(), 15).shuffleGrouping("SendPhrasesSpout");
topologyBuilder.setBolt("ToLowerCaseBolt", new ToLowerCaseBolt(), 40).shuffleGrouping("PhraseToWordsBolt");
topologyBuilder.setBolt("FilterWordsBolt", new FilterWordsBolt(), 20).shuffleGrouping("ToLowerCaseBolt");
topologyBuilder.setBolt("WordCountBolt", new WordCountBolt(), 10).
fieldsGrouping("FilterWordsBolt", new Fields("word"));En este ejemplo se puede ver la definición de los Spouts y Bolts y el nivel de paralelismo definido en cada uno (cantidad de Tasks que lo ejecutan).
Como se ve en el código de ejemplo cada Bolt se suscribe a un Spout o un Bolt para recibir las tuplas que estos emiten. En el código se ve como todos se conectan a través de shuffleGrouping, salvo el ultimo que se conecta a través de fieldGrouping donde además se especifica un campo word, esto refiere al agrupamiento de Streams. En los primeros casos no es importante para el procesamiento a que Task del Bolt va la tupla, pero al tener que contar las palabras necesitamos que una misma palabra valla a una misma task, para no tener un count en una task y otro count en otra task.
Con el codigo anterior queda totalmente definida la topología, pero veamos ahora como es la definición de un Spout.
public class SendPhrasesSpout extends BaseRichSpout {
private static final String[] phrases = {"Hola como estas", "Hola como te va", "Este es otro ejemplo",
"Ejemplo es lo que sobra", "Estas en el horno", "El horno de mi mama", "Estas fraces son un ejemplo de encaje",
"Encaje tiene el vestido de mi mama", "Mama es mal", "Mama es buena", "Vamos los pibes", "Pibes era un perfume",
"El perfume un gran libro es", "Ahora le pinto Yoda"};
private SpoutOutputCollector collector;
@Override
public void open(final Map conf, final TopologyContext context, final SpoutOutputCollector collector) {
this.collector = collector;
}
@Override
public void nextTuple() {
int rnd = new Random().nextInt(phrases.length);
collector.emit(Collections.singletonList(phrases[rnd]));
}
@Override
public void declareOutputFields(final OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("phrase"));
}
}En este caso implementamos el formato típico de Spouts a través del BaseRichSpout. En este caso solo tenemos que implementar tres métodos, el open para la definición del Spout, el nextTuple que se ejecuta cada tanto tiempo para emitir un valor, y el declareOutputFields, el cual define el formato de las tuplas de salida. Solo con estas definiciones ya tenemos un Spout.
La definición de un Bolt no es muy diferente como queda mostrado en el siguiente ejemplo.
public class PhraseToWordsBolt extends BaseRichBolt {
private OutputCollector collector;
@Override
public void prepare(final Map stormConf, final TopologyContext context, final OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(final Tuple input) {
final String phrase = input.getStringByField("phrase");
Arrays.stream(phrase.split(" ")).forEach(w -> collector.emit(Collections.singletonList(w)));
}
@Override
public void declareOutputFields(final OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}La única diferencia importante entre un Bolt y un Spout es que el primero define un execute en vez de un nextTuple, y éste recibe una tupla en vez de crearla, como se ven en el ejemplo.
Tanto en el Spout como en el Bolt para emitir una tupla se ejecuta la función emit.
Pueden ver el resto de las definiciones de la topologia para entender mejor cómo funciona. Al ejecutar el ejemplo tal cual está, deben de tener como resultado 10 archivos con el numero de Task y las palabras contadas por cada una, y una palabra no debería aparecer en distintas Tasks. El numero 10 es debido a que el ultimo Bolt tiene 10 en el paralelismo, al aumentar o disminuir este numero cambiara la cantidad de archivos en ese valor.
Al ejecutar el ejemplo, se debe tener en cuenta que una topología no termina, por lo que va a quedar ejecutando interminablementa hasta que la detengamos.
No, pero están relacionados. Tanto Spark como Hadoop realizan paralelismo a nivel de procesamiento de datos, en cambio Storm realiza paralelismo a nivel de ejecución de tareas. Entre Spark y Storm existen “sabores” que realizan un trabajo muy similar.
Spark Streaming y Storm Trident son casi productos equivalentes que difieren en el enfoque: Spark Streaming le da la posibilidad a éste de construir aplicaciones para procesar Streams de datos, creando microtransacciones de batches Spark. En tanto Storm Trident ayuda a la ejecución de Streams transaccionales muy parecidos a los Streams de Spark.
Kafka también se confunde con Storm por la similitud entre Stream y una cola distribuida. En verdad una cola distribuida es solo eso, no implica un procesamiento paralelo en sí. Muchas soluciones con Storm utilizan Kafka como fuentes de datos Spout para poder alimentar de manera paralela a la Topología Storm, el cual cuenta con Spouts para conexiones con Kafka y con otros motores de colas de mensajes.
1 * Apache Storm