Home
Welcome to the stockER wiki!

-
Training Set: Used to train the model
-
Test Set: Used for test
-
Validation Set: Used before test(validation check)
-
k-fold Cross-Validation
-
LOOCV(Leave-One-Out Cross Validation):
- Advantage: Less bias
- Disadvantage: Too many calculations (NFL)
- Bootstrapping: sampling randomly from set D to D', m times. (n(D) = n(D') = m)
- So-called, out of bag prediction(~36.8% may not be sampled --> used for the testing phase, not training)
- Used if data set is hard to classify into groups & fewer data sets
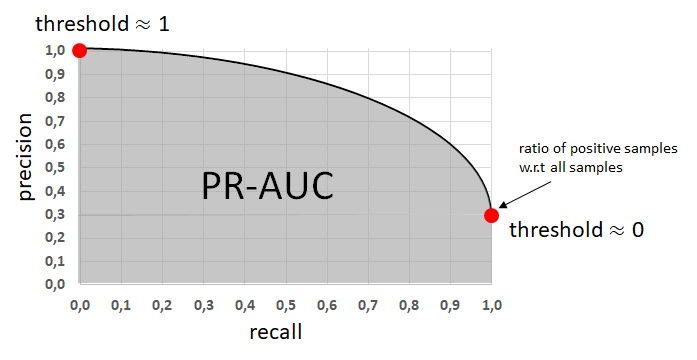
- Recall and Precision
- Precision: True Positive / (True Positive + False Positive): 양성이라 판정했을 때의 진짜 양성일 능력
- Recall: True Positive / (True Positive + False Negative): 양성을 양성이라 할 능력
- Bias-Variance-Decomposition
BVD_explanation
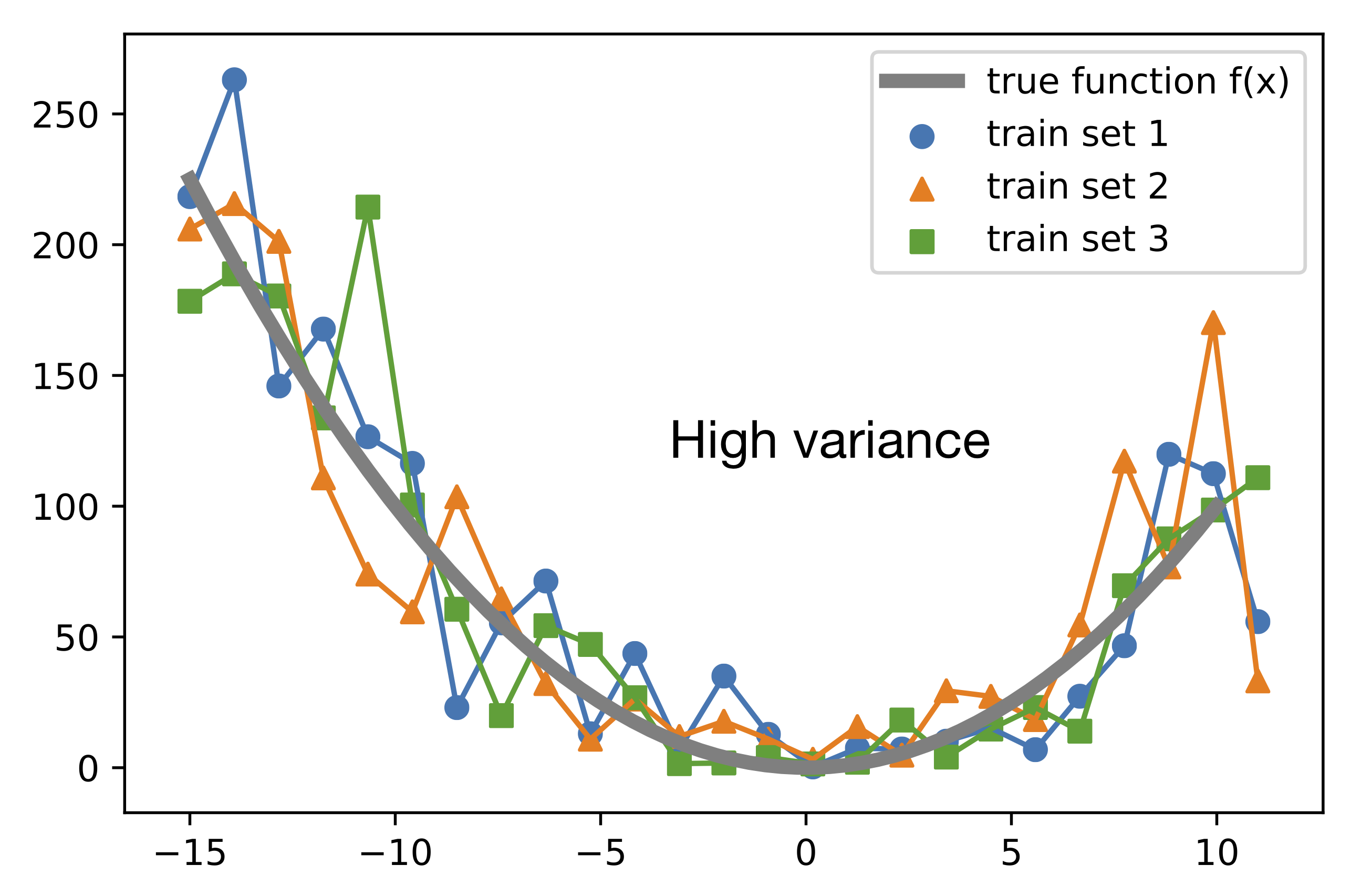
- Error = bias**2 + var + eps(noise)
- t검정 내용 추가 요망...
**Projection onto the hyperplane <-> least square method <-> Euclidian distance minimization **
-
Multivariable Linear Regression: Least Square Method <-> Projection onto a hyperplane in Euclidian space f(x) = Wx + B ~ y
-
Log Linear Regression: f(x) = Wx + B ~ ln(y)
3.Logisitic Regression: Uses sigmoid function as a surrogate function of unit step function f(x) = Wx + B ~ ln(y/(1-y))
- W and B determined easily by Maximum Likelihood Theorem
- LMM(Lagrange Multiplier Method)
- SVD(Singular Value Decomposition)
- GRQ(Generalized Rayleigh Quotient)
Too much positive or negative value compared to a negative and positive value, respectively
Thus,
-
change system's threshold --> Rescaling method
-
Undersampling: getting rid of too much data
-
Oversampling: adding data
#MULTILABEL LEARNING???
dddd