[C#] Could Disk Reads be FASTER? #238
Comments
|
There is a tension between sync and async code here. For sync, the better alternative is Thread.Yield (benchmarked in the past). But for async, the better alternative might be what you suggest (Spin), although I have not benchmarked this yet. Is the observed cost (throughput) with async significantly degraded to justify a change or a config here? |
|
Actually, async code is already avoiding the The other issues, though, like batching reads and chaining RMW's, are still alive. |
|
Then is this PR still relevant: #241? Will consider the other comments separately. |
|
I closed the PR. |
|
Closing as we have optimized the main goal of reads. We can create new issues if we plan to work on any other issues/ideas mentioned here. |
I've got pretty much every basic operation covered on my POC.
Repo: https://github.com/ThiagoT1/FasterDictionary/tree/unsafe-0.0.3-fastread
Iteration thru the whole KV has ok(ish) performance.
https://github.com/ThiagoT1/FasterDictionary/blob/96407cf3e476f612eb2eb72e895af4c6f9358850/src/FasterDictionary/FasterDictionary.Iterator.cs#L68-L71
Issue
What's killing me now is the random key read performance. I'm talking "mono-threaded" access to KV where a single reader has to retrieve values for thousands of random keys.
Adding, Updating once and Iterating over 1M keys takes less than 2 minutes:
https://github.com/ThiagoT1/FasterDictionary/blob/026248db7bfca8f5b72c22481f732babd8237c8e/tests/FasterDictionary.Tests/UseCases/ArrayAsKeyTests.cs#L157-L190
However, doing the same while replacing the iteration with a 1M key lookup takes 30 minutes:
https://github.com/ThiagoT1/FasterDictionary/blob/026248db7bfca8f5b72c22481f732babd8237c8e/tests/FasterDictionary.Tests/UseCases/ArrayAsKeyTests.cs#L136-L141
This is a regular SSD, with roughly 500 MB/s read/write:
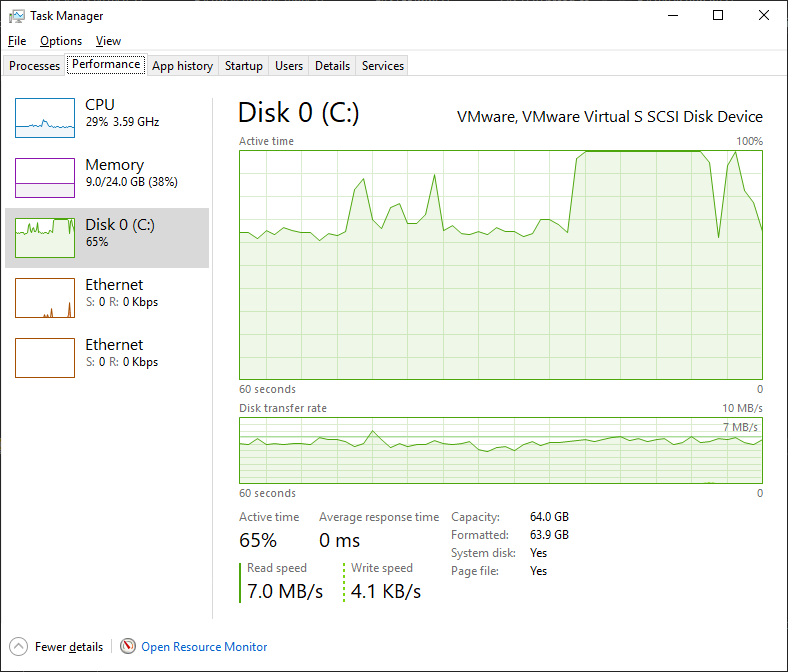
Looking at CPU time eaters on VS 2019 we see that the culprit is
ClientSession<,,,,,>CompletePending, which in turn blames theThread.Yield()insideFasterKV<,,,,,>.InternalCompletePending.Replacing the
Thread.Yield()with aSpinWait.SpinOnce()maintains functionality while greatly reducing CPU Usage.Throughput, however, stays low, since the real bottleneck is the granularity of disk reads (the 30 minute mark is with this one):
Use Cases
Theres two scenarios where one of those strategies - mono-threaded iteration or massive random key lookups - will come into play:
1) Iterate thru a subset of the key set (Read Only)
In this case, every key in the subset will have to be passed to
KVSession.Read, which will have awful performance. This strategy could be replaced (by the KV user) with a whole KV iteration, dismissing keys not in the subset. Not great, though.Proposal
The knowledge about multiple keys in need of retrieval should be passed to KV, by means of a Read method that would accept multiple keys, while returning a AsyncEnumerable<ReadResult> that could be used to process all recovered values.
Such KV method would use that key array to optimize disk access (leveraging address and segment locallity), by means of reading larger chunks less often, whenever possible.
2) Massive RMW of Unitary Keys Already on Disk
In this case, currently both the RMW'er and the Reader are slow, plus (AFAIK) the reader may get an old value, while we wait for the disk access to complete (and the RMW continuation to complete).
Proposal
RMW`s should atomically mark the record as dirty and cause any Read result of that key to yield a status that means we are waiting on a RMW to complete. The reader could optionally continue the read of a (possibly) old value, or place a continuation for when the RMW completes, which would garantee a fresh read up to that point.
This would also let the RMW'er fastly keep issuing the RMW command for the next keys, since a continuation for the actual RMW operation can be placed and there's a guarantee that any readers can wait for the RMW to complete.
The code that actually does the RMW after the disk read could be provided by a new Functions instance, as per #230.
It should also be noted that FASTER was firstly written without TLP in mind, and full adherence to TLP semantics would see the Functions class callbacks gone. But that's probably for another day, isn't it? :)
Also, please note that the same tests without updates complete under 40 seconds. The detail here is that we are changing the value length on purpose, with those updates. This forces the concurrentwriter call to return false, which in turn causes the need of a new slot on the log.
Thanks a lot!
The text was updated successfully, but these errors were encountered: