Michelle Werner (5/22/2022)
Pewlett Hackard is a large company with several thousand employees. Because so many employees are nearing retirement age, the company is concerned about a 'silver tsunami' of exiting employees and vacant positions ahead, and wants to be sure current employees are well-trained and mentored before more experienced staff heads out the door. The HR analyst on staff needs to answer questions about who will be retiring in the next few years and how many positions might need to be filled, and I will be helping him build a hearty relational database from multiple excel files which the company has used to store employee data up to now.
There are six main csv files that store all of the company's employee data. Bobby (the Pewlett Hackard HR analyst) and I worked together to generate this ERD (Entity Relationship Diagram) to have a visual of the conceptual, logical, and physical content of each table that will be added to our final database. The image below clearly shows primary and foreign keys in each table and the way each table relates/connects to another.

The decision was made to use the PostgreSQL environment for the new database and the accompanying PGadmin software to build, access and easily query the data. Once the database was initialized, the empty structure for each of the 6 tables in our ERD was created and the csv content of all 6 was loaded into the new environment. Once each table's content was confirmed without errors, we could begin writing queries to pull specific data and create new tables that contained retirement-specific data -- and easily answer all of our retirement questions.
The two biggest questions being:
- What is the number of retirement eligible employees and what are the jobs they will leave empty?
- Who are the employees that would be the best eligible candidates for any mentorship program?
Initially, we searched for employees of retirement age using the birth date information in the main 'employee' table. We had settled on employees born between January 1st, 1952 and December 31st, 1955 -- and were terrified to realize that was over 90K employees. Because of this we searched by each year individually, but all were fairly consistent with between 21K and ~23K employees/year - so we tried to limit the number by including a length of service range as well and created our first attempt at a retirement list with the query:
SELECT emp_no, first_name, last_name
INTO retirement_info
FROM employees
WHERE (birth_date BETWEEN '1952-01-01' AND '1955-12-31')
AND (hire_date BETWEEN '1985-01-01' AND '1988-12-31');
From there we looked at departments, titles, and salaries individually, and created a few summary tables combining different characteristics like retirement eligible and salary info or retirement eligiblilty and department, etc. In looking closely at that data, we realized that it contained people who no longer worked at Pewlett Hackard with end dates that were already in the past, and noticed that many employees had multiple listings due to promotions and job title changes. We had to rethink our logic. Eventually we succeeded in getting a quality list, and creating a query to return accurate counts and quality information. We used the following:
SELECT DISTINCT ON (e.emp_no) e.emp_no,
e.first_name,
e.last_name,
j.title,
j.from_date,
j.to_date
INTO retirement_count
FROM employees as e
INNER JOIN titles as j
ON (e.emp_no = j.emp_no)
WHERE (e.birth_date BETWEEN '1952-01-01' AND '1955-12-31')
AND (to_date = '9999-01-01')
ORDER BY e.emp_no, j.from_date DESC;
The query above returns 72,458 results, which is equal to the number returned in a query without DISTINCT ON or designating a from_date ORDER BY, but Bobby and I could think of situations where someone might be holding an interim position and perhaps entered as 'current' with two titles (or some other similar entry error since this table does not contain a unique primary key such as 'job_id' and multiple titles are allowable for each employee number), so we agreed this query would knock any issue like that out as well. We were pleasantly surprised that the new query count matched the simpler query (without a DISTINCT ON or from_date consideration). 72,458 employees are retirement age and currently still employed - and that number has been double-checked.
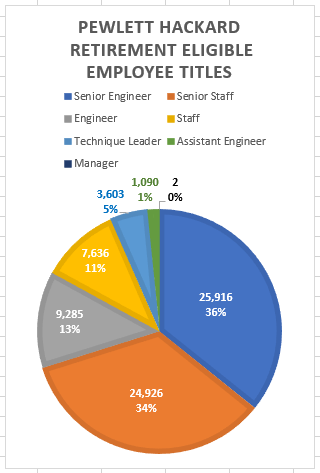
The results of our Pewlett Hackard employee data analysis revealed useful data insights about the potential 'silver tsunami' and answer the initial questions that called for this analysis. Revealing results include:
- The number of current employees that are eligible for retirement is 72,458.
- The titles of these employees indicate the vast majority fall into upper management - including 25,916 Senior Engineers and 24,926 Senior Staff, as well as 3,603 Technique Leaders and 2 managers - leaving only 18,011 eligible retirees employeed in non-leadership positions (see Fig 2 on right).
- The number of current employees eligible for the mentorship program (with the birth year restriction set to 1965) is 1,549.
- If all employees eligible for the mentorship program participated, the mentorship pool would contain 283 Senior Engineers, 422 Senior Staff, 77 Technique Leaders, 404 Engineers, 61 Assistant Engineers, and 302 Staff.
Fig 2. Pewlett Hackard Retirement Eligible Employee Titles
Because of the high number of retirement aged people currently employed at Pewlett Hackard, an analysis of employee data was requested with the following original list requests:
- A list of employees containing their unique employee number, their last name, first name, gender, and salary (Employee Info).
- A list of managers for each department, including the department number, name, and the manager's employee number, last name, first name, and the starting and ending employment dates (Management Info).
- An updated current employee list that includes the employee's departments so that sorting out the Department Retirees can be done efficiently in the future.
We were able to successfully complete that task, and to provide several additional lists of data, including:
- A list of retirement eligible employees and their last known title (Retirement Titles)
- A list and count of the job titles of the retirement eligible employees (Unique Titles)
- A list of employees born in 1965 who would be eligible for the Mentorship program and with their current titles (Mentorship Eligibility)
We were able to identify all current retirement eligible employees and to calculate that there are more than enough mentors available for the planned mentoring program. However, the scope of the mentoring program seems insufficient. The number of mentees is extremely small in comparison to the number of anticipated upcoming empty positions. As the 'silver tsunami' begins to make an impact, 72.5 thousand jobs will need to be filled and the mentorship program, as it stands, will only pair up 1.5 thousand employees.
Also, the requested info looked at latest "title" of both mentor and mentee and it is not clear whether the plan is to match up retiring employees and mentees with the same title - or for mentees to be mentored in order to 'level-up'. The latter seems like it would be more incentivising for a mentorship program. Because of this, we broadened the mentee birth date from 1965 to 1964-1969 and created lists of employees with their last title AND department info so that better matching could take place. These lists are:
- A list of retirement eligible employees, last known title and department (Retirement Department Needs)
- A list of potential mentees - with birth years expanded to include all years from 1964-1969 (Department Eligibility)
Comparing these lists will not only facilitate better matching and better mentee opportunity and incentive, it will also increase the number of mentorships in the program which will hopefully offset the potential 'silver tsunami' openings at a much higher rate. The success of any promoted employees will depend on both job-readiness (and the truly impactful benefit of a great mentor) - AND proper staffing at all levels. Training only 2% of people needed (1.5/72.5) will not have the impact the mentorship program is intending. Increasing the program to the dates we have suggested would increase the program potential job-filling rate from 2% to 26%, still lacking, but better.
Further analysis to group this information and create unique title-department counts could be offered.
-
Increase the age-range of the mentorship program for a higher employee pool to fill vacant jobs - and a higher staff success rate in promoted positions.
-
Look at department needs when matching, in addition to titles.