Perform first healthcheck on startup without waiting the specified interval #33410
Comments
|
@thaJeztah WDYT? Looking at the docs I couldn't find anything that allows this. |
|
I think the reason for this is that a lot of container may need a "warm up time" (e.g. database getting ready to accept connections) so if the first health check is performed directly after the container is started, it would result in a lot of "false positives". Now that we have Still I wonder if there's many containers that may report I understand the use-case, but I'm not sure about the consequences if we change this, as it may break existing setups ping @dongluochen @stevvooe wdyt? |
|
@thaJeztah This is a little surprising. Why would we wait at all to run the healthcheck? The "start period" should be the time after which we consider a failure to be a hard failure. If the health check succeeds under that time, the container should go into service. @alexpirine I'd recommend you test if this works as expected. That wording may be inaccurate. |
|
@stevvooe I tested it and the behavior is as currently described in the documentation. The very first check is run only after the defined health check interval, and the container goes into service only after it is completed. So it can take quite a lot of time to reload all the replicas. |
|
@alexpirine Ok, it really should just start running and only consider a fault as a failure until after the start period to minimize bring up. We should consider this a bug. |
|
I think one way to address the issue without break the compatibility is to have the default value of |
|
Created a PR #33918 with the following changes:
With the above changes, backward-compatibility will be maintained. Please take a look |
|
Looking forward to this enhancement. I also need the health check to be run immediately after the container has started. |
…terval This fix tries to address the issue raised in moby#33410 where the first healthcheck was only performed after the specified interval. That might be problematic in case the interval is long yet, as is specified in moby#33410. This fix make the following changes: 1. The first healthcheck is performed on startup (at time 0) 2. The first healthcheck is only valid when no-wait = true The changes allows the backward-compatibility while at the same time it is possbile to address the issue raised in moby#33410. Additional test cases have been added. This fix fixes moby#33410. Signed-off-by: Yong Tang <yong.tang.github@outlook.com>
|
There are GUIs like 'Portainer visualizer' which do not show the tasks at all when filtering for "running" tasks - which means healthy in their filtering. 'starting' has to be 'starting' - defined by start-period and not by interval. I also want to use long time intervals - but not waiting for the first check getting healthy. As @thaJeztah wrote
the health-start-period has been implemented through all "stages" with docker/cli#475 |
|
There are two problems in the actual healthcheck when using the swarm mode:
Therefore, the solution for the healthcheck must be to run the first check on time 0 and not on time interval x1 Optionally, the I tried to make some examples of "existing setups" and compared them with the suggested solution.
@thaJeztah There is one thing which will probably break in my opinion. I think this could be fixed with
|
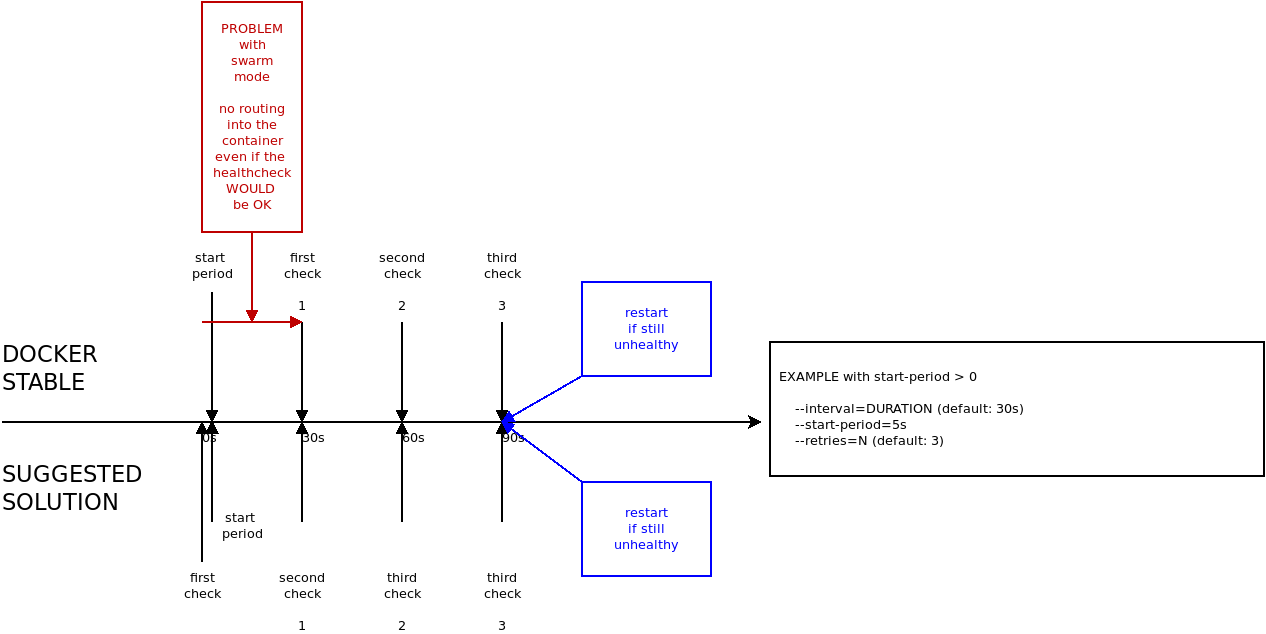
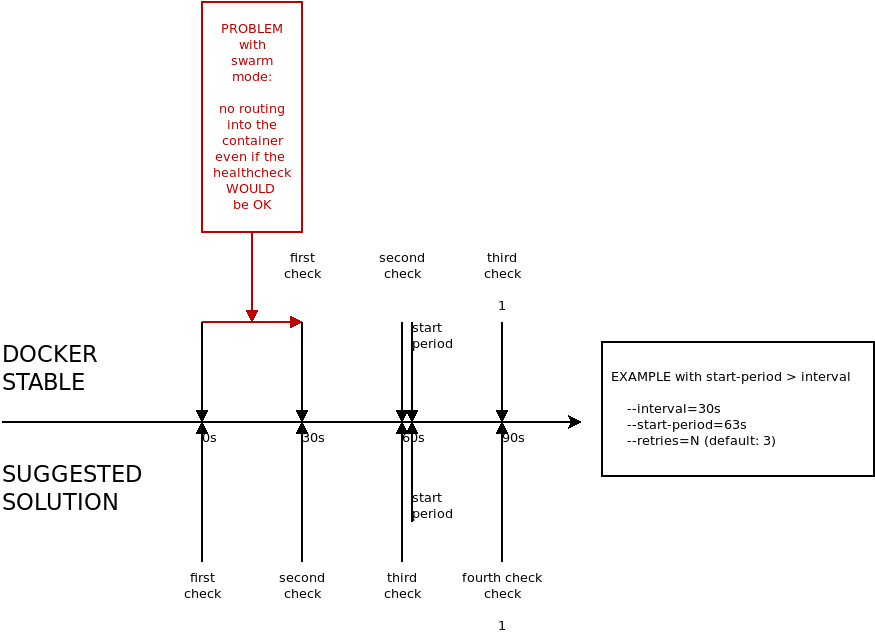
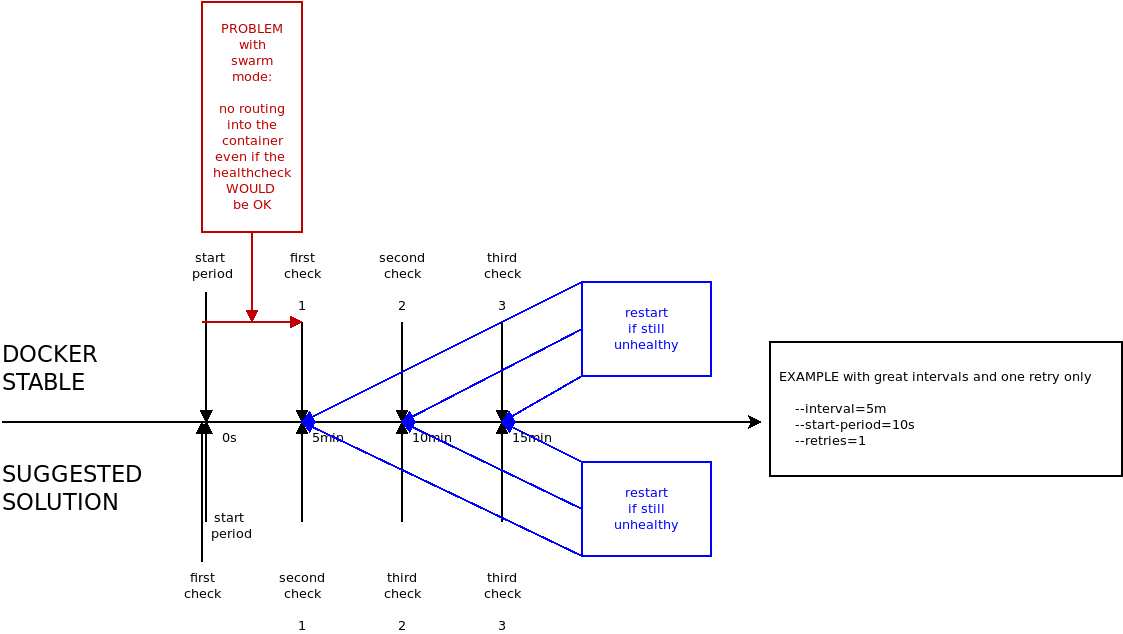
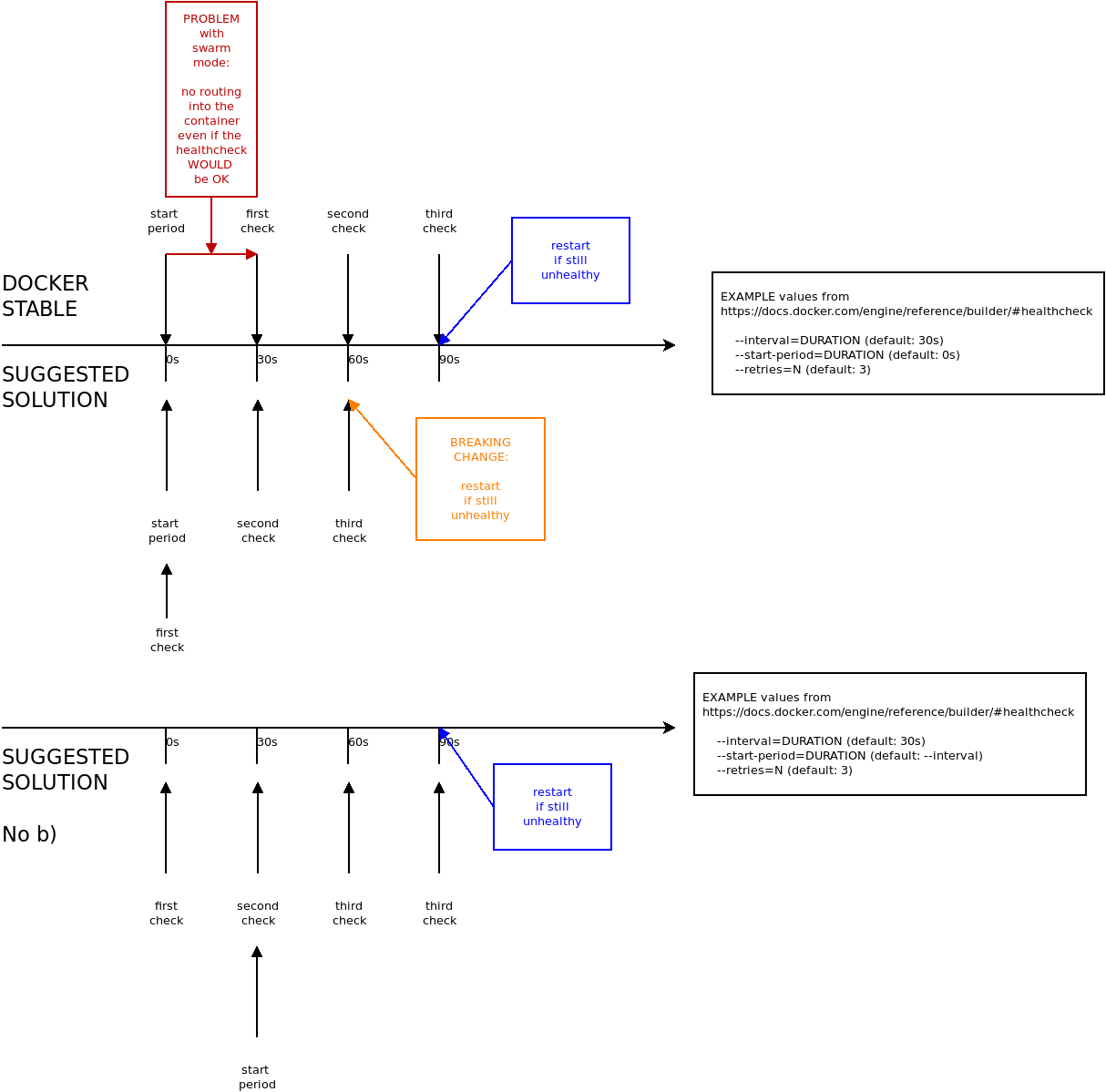
|
In the suggested solution above, I still do not see how a container that needs --start-period time to get healthy would become available any sooner than --interval seconds? This can only be achieved when a health check is done after --start-period seconds. As long as that does not happen, any container that is not healthy instantly will not be available for --interval time... |
|
@dtakken I must admit that you are right. Thanks for your correction, I have not seen that. So, what would you suggest? (Still hoping somebody will have a simple solution for all that ...) |
|
The simplest solution would be to change Docker behavior and perform a health check just after --start-period seconds. In case there are concerns about breaking existing setups, a new option would need to be introduced. Something like --check-on-start could trigger an additional check just when the container is expected to have started, after --start-period seconds. Since --start-period is zero by default, enabling --check-on-start would do a first health check immediately, which makes sense for most containers. For containers that need a second to start, setting --start-period=2 for instance would do a health check after two seconds. @thaJeztah: Which of these two options would be acceptable? |
That would defeat the purpose of The start-period for that reason, should always be made longer than
@rdxmb If I understand correctly, the breaking change would be that "retry-count" expiration would occur one "interval" time sooner than before (because the first health check is started at |
|
@thaJeztah The main problem with the current approach is for checks that take a long time or checks that are resource intensive. For example, we got a container where we run the healthcheck every 20 min because check healthcheck causes ~20 secs of CPU load. So with this setup it means that it takes us 20 minutes before the first traffic is routed to the container, which makes any restarting process quite problematic... ;-) |
|
@thaJeztah correct. However, like @dtakken explained, it does not really fix the actual problems... |
You are completely right about that one @thaJeztah. I should have proposed to introduce an option to run an additional health check just before
This is exactly the source of the problems. This forces us to either use a really short How about introducing a
The periodical checks every |
|
Indeed @alexpirine, it looks like the option that I propose for Docker mimics Kubernetes. |
|
Seems like this issue could be easily solved by copying Kubernetes' approach. Add Default What is the concern with this implementation? |
|
I think a far more flexible solution would be to provide an option such as Typically during container start, I want the interval to be low (in single digit seconds), to get the new version up quickly. But during normal operation, I don't want logs full of health check requests. |
|
I think the best solution to fix this issue is what @ColdHeat explained. |
|
Hello, I still have had a subscription for this issue, although I have been working with kubernetes instead of swarm for over a year. TLDR: They use separate definitions for |
|
Is this still under active consideration? I also encounter situations where I would like to run a health check shortly after the container comes up, but then after that, I wish for a longer interval. E.g.
|
|
Ideally it should have 2 intervals. start_period = 30s At start - checks every 5 seconds for 30 seconds. I am wondering, why docker devs unable to build usable logic. This is annoying. How long this issue will be opened? |
|
People creates bug reports and pull requests but has no feedback at all for a years. |
|
This feature would be really great to have. I would like to run a health check shortly after startup and then at spaced intervals thereafter. Same idea as xkortex's comment. The problem with the current functionality is summed up perfectly by @cpuguy83 in his comment here. "Typically when a container is just starting you want to check if it is ready more quickly than a typical healthcheck might run. Without this users have to balance between running healthchecks to frequently vs taking a very long time to mark a container as healthy for the first time." |
|
Any updates on this? |
|
We can run the first health check at MIN(start-period, interval) to solve this issue. |
The way Docker health checks work is: 1. The container is started 2. Docker waits a full healthcheck `interval` 3. A healthcheck is made. If OK, mark as healthy The problem is that (as described in 2.), Docker always waits a full interval before doing the first check. The `interval` configuration serves 2 purposes: - wait time before the first health check - wait time between subsequent health checks This annoyance is also described in: moby/moby#33410 The way this manifests as a problem is when reverse-proxying with Traefik, like we do by default in https://github.com/spantaleev/vaultwarden-docker-ansible-deploy Traefik refuses to reverse-proxy to containers which are unhealthy (Health Status=starting is also considered unhealthy). This means that Vaultwarden, with its current 60 second healthcheck interval will take a full minute to become healthy and to be reachable by Traefik. In vaultwarden-docker-ansible-deploy, we currently work around this by overriding the default health check interval: https://github.com/spantaleev/vaultwarden-docker-ansible-deploy/blob/015c459970d41743bd75980c2df02e389e1b461b/roles/custom/devture_vaultwarden/templates/vaultwarden.service.j2#L15-L36 With our workaround (which this patch also applies), it *only* takes 10 seconds after Vaultwarden startup and until Traefik would reverse-proxy to it.
|
Why are there no updates on this one even though it seems reasonably simple to implement and there have also been lots of requests for it? |
|
To bypass this problem I use this script in Perl but simply adaptable to other languages #!/usr/bin/env perl
# script to use in docker healthcheck to bypass this problem
# https://github.com/moby/moby/issues/33410
# exit(0) no problem, exit(1) problem
# check an url every interval seconds from the first run.
# If called in other time do nothing and exit(0)
# usage in docker compose
# healthcheck:
# test: ${APPPATH}/bin/hc -i 300 https://url.to:3000/check
# interval: 10s # this defines the first run
#
# REMEMBER .hc must not exists and/or doesn't be deployed to container
use Mojo::Util qw(getopt);
use Mojo::File;
use LWP::Simple;
use FindBin;
use constant CFG => $FindBin::Bin . '/.hc';
getopt 'i|interval=i' => \my $interval;
die "Url can't be empty" unless $ARGV[0];
my $cfg = Mojo::File->new(CFG);
# first run, always ok
&e($cfg,0) unless (-e CFG);
# if now - mtime is < interval do nothing and exit with prev value
exit($cfg->slurp) if (time - $cfg->stat->mtime< $interval);
# perform real check (function "get" return undef if fails)
exit(&e($cfg, get($ARGV[0]) ? 0 : 1));
sub e {
$_[0]->spurt($_[1]);
exit($_[1]);
}Hoping it will be fixed soon |
|
+1 on this. |
|
+1 Would be amazing to have this solved as it is frustrating to have the interval control how fast you deploy new releases when using CI. One of the main benefits of docker swarm and health checks is that we can deploy with zero downtime, but this ruins the experience and introduces an artifical lag to the deployment. Several other comments has already started what we need to archive.
|
|
+1, would be amazing to have it |
|
The original problem in this thread is specific, asking to run the first health check before not after the first interval. I can't easily tell what changed since. I understand the backward compatibility with making this specific change. As others pointed out, I believe this particular issue brings into question the practicality of the single health probe for readiness and liveness. In my case, it is difficult to reconcile these concerns with a single health probe. I can work around it with a test command similar to this: #33410 (comment) by touching a file to indicate readiness, and running either the readiness or liveness probe depending on whether this file exists. However, it is a hack that overlaps with the intent of start-period, so I'm concerned about maintainability. I believe readiness and liveness concerns can be separated without breaking the existing conventions, perhaps by including an optional start-test kind of option for use cases that demand a separate readiness probe. |
|
I implemented this some time ago here: #40894 |
|
Changes are merged into moby/moby, but there are other ecoysystem changes that are required. |
This is a feature request.
Currently, health checks work and are great to ensure continuous, uninterrupted service, even when rolling updates.
However, I might want to specify a rather long health check interval, let's say 5 minutes, because my health check checks for a few different things and is a bit time- and resource-consuming.
The documentation states:
This doesn't work well with continuous delivery, since I'll have to wait 5 minutes before the first container with my new software version is available. This is a long time to wait. And I don't really want to end up with containers running different versions of software for a long period time.
Why couldn't we just run the first health check right after startup, without waiting for
intervaldelay?The text was updated successfully, but these errors were encountered: