{kind=link}
{kind=link}
This small project test the novel architecture Kolmogorov-Arnold Networks (KAN) in the reinforcement learning paradigm to the CartPole problem.
KANs are promising alternatives of Multi-Layer Perceptrons (MLPs). KANs have strong mathematical foundations just like MLPs: MLPs are based on the universal approximation theorem, while KANs are based on Kolmogorov-Arnold representation theorem. KANs and MLPs are dual: KANs have activation functions on edges, while MLPs have activation functions on nodes. This simple change makes KANs better (sometimes much better!) than MLPs in terms of both model accuracy and interpretability.

For more information about this novel architecture please visit:
- The official Pytorch implementation of the architecture: https://github.com/KindXiaoming/pykan
- The research paper: https://arxiv.org/abs/2404.19756
The implementation of Kolmogorov-Arnold Q-Network (KAQN) offers a promising avenue in reinforcement learning. In this project, we replace the Multi-Layer Perceptron (MLP) component of Deep Q-Networks (DQN) with the Kolmogorov-Arnold Network. Furthermore, we employ the Double Deep Q-Network (DDQN) update rule to enhance stability and learning efficiency.
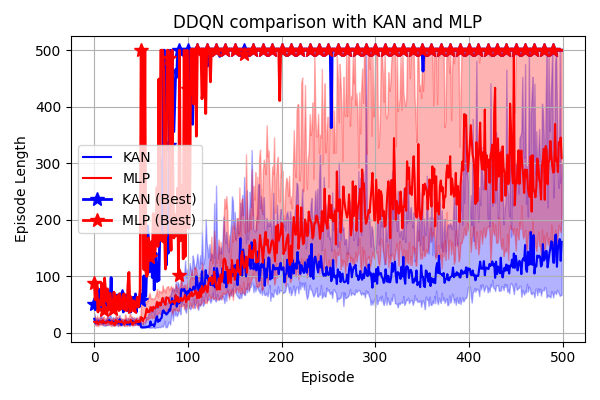
The following plot compare DDQN implementation with KAN (width=8) and the classical MLP (width=32) on the CartPole-v1 environment for 500 episodes on 32 seeds (with 50 warm-ups episodes).
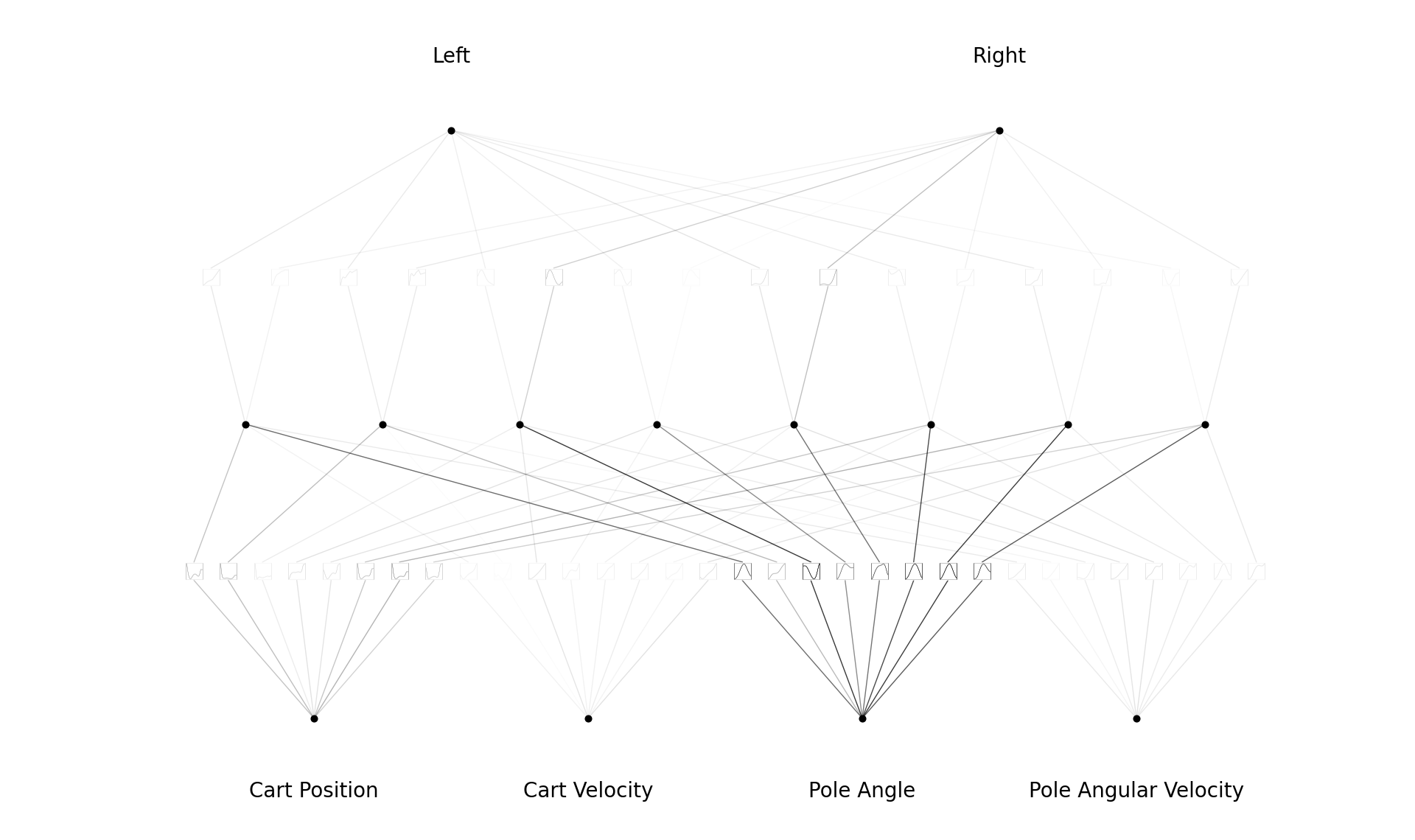
The following plot displays the interpretable policy learned by KAQN during a successful training session.
- Observation: KAQN exhibits unstable learning and struggles to solve
CartPole-v1across multiple seeds with the current hyperparameters (refer toconfig.yaml). - Next Steps: Further investigation is warranted to select more suitable hyperparameters. It's possible that KAQN encounters challenges with the non-stationary nature of value function approximation. Consider exploring alternative configurations or adapting KAQN for policy learning.
- Performance Comparison: It's noteworthy that KAQN operates notably slower than DQN, with over a 10x difference in speed, despite having fewer parameters. This applies to both inference and training phases.
- Interpretable Policy: The learned policy with KANs is more interpretable than MLP, I'm currently working on extraction on interpretable policy...
In a web application, we showcase a method to make a trained RL policy interpretable using KAN. The process involves transferring the knowledge from a pre-trained RL policy to a KAN. The process involve:
- Train the KAN using observations from trajectories generated by a pre-trained RL policy, the KAN learns to map observations to corresponding actions.
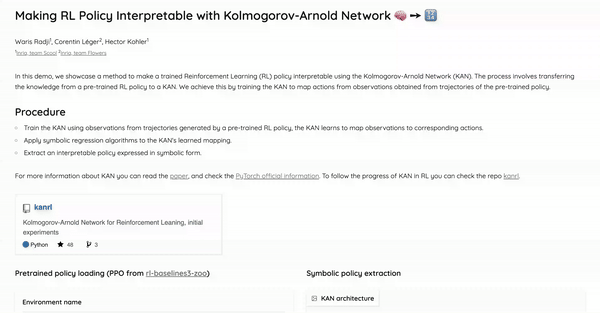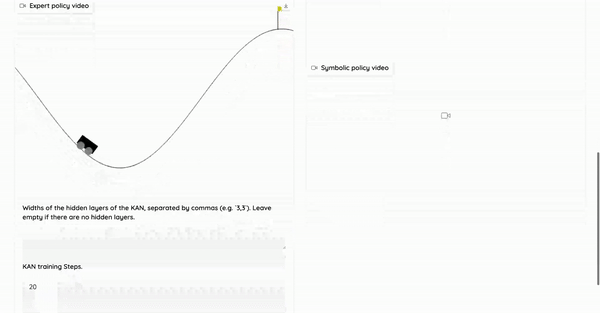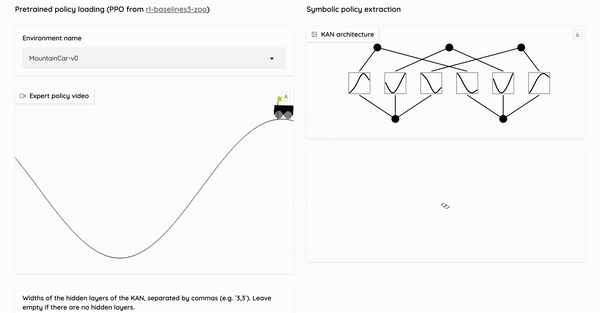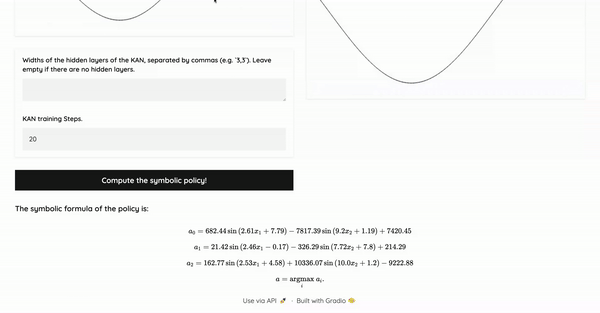
- Apply symbolic regression algorithms to the KAN's learned mapping.
- Extract an interpretable policy expressed in symbolic form.
To launch the app (after cloning the repo), run :
cd interpretable
python app.pyThere is also a live-demo on Hugging Face : https://huggingface.co/spaces/riiswa/RL-Interpretable-Policy-via-Kolmogorov-Arnold-Network
I welcome the community to enhance this project. There are plenty of opportunities to contribute, like hyperparameters search, benchmark with classic DQN, implementation of others algorithm (REINFORCE, A2C, etc...) and additional environment support. Feel free to submit pull requests with your contributions or open issues to discuss ideas and improvements. Together, we can explore the full potential of KAN and advance the field of reinforcement learning ❤️.