- 聚类假设。同一个簇的样本拥有同一个标签
- 流形假设。相近的样本有相似的输出
- 纯半监督学
学习的目的是为了在新的样本上性能更好(为了泛化性能) - 直推学习
学习的目的是为了能更好的预测本样本中无标签的数据(不强调泛化性能)
主动学习是和外部的专家进行交互,而半监督学习强调的是系统内部的自我学习
- 构造相似矩阵
- 传播
LP算法是基于Graph的,因此需要先构建一个图,图的每一个节点就是一个样本点,边的权值是衡量相连的样本之间的相似性 ,节点i和节点j的边权值计算为:
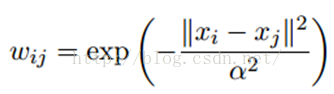
假设数据中拥有N个有label的样本,构建NXN的概率转移矩阵:
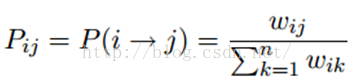
1) 执行传播:F=PF 2) 重置F矩阵中label样本的标签,即:把Y1<-原来的Y1 3) 重复1,2直到F收敛

LP算法通过构建Graph,计算样本之间的距离,从而获得样本之间的相似矩阵(样本一定要归一化,和计算距离相关的操作,一定要进行归一化)