Reduce allocations and add a Sally7MemoryPool #23
Conversation
This enables further optimizations.
The allocations for the IMemoryOwner are gone...so make a better pool.
This reverts commit f66f8cf73b69c24158a40392ef1cfed667fc26ca.
Ideally this saves one call to Socket.ReceiveAsync, as all data is already read.
|
|
||
| private bool _isDisposed; // volatile, etc. not needed as the lock in Dispose has release semantics | ||
|
|
||
| public Sally7MemoryPool(int bufferSize) => _bufferSize = bufferSize; |
There was a problem hiding this comment.
This implementation of the memory pool assumes / has as pre-requisite that the bufferSize (i.e. the size rented from the pool) is always the same. According to my understanding of the code, this is assumption holds, as the bufferSize is determined from
Lines 114 to 115 in cfbd857
There was a problem hiding this comment.
Yes, to my knowledge it's not possible to transfer more than one PDU at a time (though COTP -IIRC- actually has support for sequences of PDU's) with Siemens PLC's, resulting in a known max message length.
| using System.Diagnostics; | ||
| using System.Runtime.InteropServices; | ||
|
|
||
| namespace Sally7.Infrastructure |
There was a problem hiding this comment.
Hm, should this be under Internal instead? It's not really "inftrastructure" or is it?
There was a problem hiding this comment.
It's one of those naming struggles. It supports the project but is not the product itself, as such infrastructure is valid I guess. Internal is just as good though, recently I've used Internal over Infrastructure for all my work projects.
There was a problem hiding this comment.
recently I've used Internal over Infrastructure for all my work projects.
Similar situation in my projects. I'll move this type to "internal", also because it's "Sally's pool" as internal implementation detail.
Didn't think enough when creating the code, just before while creating the PR.
| public void Dispose() | ||
| { | ||
| #if DEBUG | ||
| Memory.Span.Clear(); |
There was a problem hiding this comment.
Without this debugging is strange, as contents from previous usage of the memory will be there.
It's not user-visible, i.e. won't be any concern for release-builds.
Do you want to enable the clearing in release too?
Cost is there, but it's quite cheap, as the implementation is vectorized in .NET.
There was a problem hiding this comment.
I'm not sure. It's not exposed, so it shouldn't be an issue, OTOH it is very confusing if you ever do look at it...
|
|
||
| namespace Sally7.Internal | ||
| { | ||
| internal partial class SocketTpktReader |
There was a problem hiding this comment.
Implemenation from main-branch, just split out into separate file -- see comment in description of PR.
| jobChannel = Channel.CreateBounded<byte>(maxNumberOfConcurrentRequests); | ||
| sendChannel = Channel.CreateBounded<byte>(1); | ||
| receiveChannel = Channel.CreateBounded<byte>(1); | ||
| this.memoryPool = memoryPool ?? MemoryPool<byte>.Shared; |
There was a problem hiding this comment.
The Sally7MemoryPool used in S7Connection will be injected here. This is just a "safety-net" to fall back to the shared memory pool.
|
|
||
| await sendChannel.Reader.ReadAsync().ConfigureAwait(false); | ||
| _ = await sendSignal.WaitAsync().ConfigureAwait(false); |
There was a problem hiding this comment.
For the potential concurrency-issue I don't believe this will change anything (I mean that the "result" is awaited and discarded). C# isn't allowed to optimize this call away, nor will do the JIT as the generated state machine code explicitely has the setup for the awaiter.
But with the _ = await ... it's more explicit (and in ASP.NET they write the code that way too -- maybe for good reason? I don't know).
There was a problem hiding this comment.
Following the ASP.NET Core practices seems like a good idea. I know in some cases warnings are produced for unused return values, but I guess those should've shown up here already if that would be the reason.
| @@ -52,7 +52,7 @@ private static void ConvertToLong(ref long value, ReadOnlySpan<byte> input, int | |||
|
|
|||
| private static void ConvertToLongArray<TTarget>(ref long[]? value, ReadOnlySpan<byte> input, int length) | |||
There was a problem hiding this comment.
Just as info: I tried a generic struct based version, as the JIT needs to create special code for generics over value types, so that these tiny methods can be inlined. But in essence the code gets ugly, and perf isn't better -- the delegate invocation here is traded against a virtual call from a base-class to the implementation, so no net win.
|
I only looked at your message and comments for now, but again I'm very impressed. Will take a look at the rest soon, for now I haven't seen anything which would make me hesitant to merge this. |
|
Is there a significant advantage of not just using the shared MemoryPool on netstandard2.1+ ? |
|
The default MemoryPool (aka Shared instance) allocates a That pinning the memories (on .NET 5 onwards) becomes effectively free is a nice spin-off of the custom pool. |
{kind=link}
There was a problem hiding this comment.
First of all, there's a few things I'm not extremely fond of:
- I prefer using
varover explicit types, many of the changes use explicit types. My preference forvaris because it's short and because it doesn't require changing when return types of methods change (and often variable are just passed along). - The added complexity to the csproj file for supporting netstandard21 / net5 or net framework. I'm not sure if there's a better way than this, but at least it's pretty explicit.
Aside from these two points though, I really like how this turned out. The Sally7MemoryPool is a great idea because now it's a MemoryPool that has the exact semantics that Sally7 needs. I'm wondering about the impact for our own (Viscon) applications though, because we will probably perform 1000s of reads at the same time (in larger projects), possibly resulting in 1000s of buffers in the POH. Then again, assuming it's less than 10k requests, it's less than 10k * 960 bytes, which is less than 10MB of memory. I couldn't find a size limit for the POH (only searched quickly), so I'm assuming that it'll work out.
Again this is a nice feature that can prove useful in other PLC communication libraries, for instance implicit communication over Ethernet/IP also has a fixed size, so there it would work just as well.
| public async ValueTask<int> ReadAsync(Memory<byte> message) | ||
| { | ||
| int count = 0; | ||
| Memory<byte> buffer = message; // try to read as much a possible |
There was a problem hiding this comment.
After actually pushing out this in a release, I'm having second thoughts on this. If multiple responses are already waiting, this might read more than one response. The reason I was only reading 4 bytes is that the TPKT header is 4 bytes, so there was no chance of reading more than one response at a time. Now with this change it's possible to read multiple responses in one go, while only the first response is processed.
Also, performance-wise I'm not sure if the ValueTask approach has much to offer over the SocketAwaitable. The idea behind the SocketAwaitable is that the same object can be re-used for multiple requests, while a ValueTask (to my knowledge) is only allocation-free when the execution is synchronous, which logically only is on subsequent reads if the first read was for less data than was available from the OS. Your last benchmark actually shows a higher mean and error than second to last, and while the number action allocations is reduced the number of AsyncTaskMethodBuilder allocations has increased. And all this is actually in combination with an invalid premise of reading as much data as possible initially, although I think subsequent reads should actually complete synchronously and get most advantage of the ValueTask approach in case more data was available anyway.
Could you perhaps benchmark this again with an initial buffer size / slice of 4 bytes? If that actually performs better than using the SocketAwaitable then it makes sense to keep this one in, otherwise we'd better revert back to SocketAwaitable only.
There was a problem hiding this comment.
If multiple responses are already waiting, this might read more than one response
I'm not that familiar with the internal S7 communication, so maybe that's a unthaught question: isn't it alway read followed by read, so in sequentialized manner? Are true concurrent request over the same connection allowed?
Now with this change it's possible to read multiple responses in one go, while only the first response is processed.
That would be bad 😢 Sorry therefore.
As for the release: you can "unlist" the package from search-results. The url should be https://www.nuget.org/packages/Sally7/0.11.0/Manage
a ValueTask (to my knowledge) is only allocation-free when the execution is synchronous
Correct -- when no advances mechanism like VT-pooling are used.
My motivation for using the VT is that the socket-methods SendAsync, and ReceiveAsync with VT can be used, thus avoiding an allocation for a Task over there, as the VT in the sockets is based on IValueTaskSource<TResult>, and that instance is cached.
Now I had another thought about the SocketAwaitable -- maybe my mind got mis-routed due the work for sockets in the runtime-repo with a focus on VTs... SocketAwaitable is a good implementation too, so now I'm not sure if there are real benefits of the VT. Will need to investigate that a bit more.
Your last benchmark actually shows a higher mean and error than second to last
Wondered the same, my conclusion was network latencies between the two different machines (PLC ran inside an VM) used in the benchmarks. So for these I would read them with caution.
and while the number action allocations is reduced the number of AsyncTaskMethodBuilder allocations has increased.
I should measure the total count of operations (reads) performed in order to take these into the relation. Being lazy, I just put in the ratio of AsyncTaskMethodBuilder to action delegate allocations, as a rough measure / relation.
Could you perhaps benchmark this again
Will do (tomorrow).
There was a problem hiding this comment.
If multiple responses are already waiting, this might read more than one response
I'm not that familiar with the internal S7 communication, so maybe that's a unthaught question: isn't it alway read followed by read, so in sequentialized manner? Are true concurrent request over the same connection allowed?
Yes, and actually I've only recently started supporting that because of the additional complexity. That's where the ConcurrentRequestExecutor comes into play. AFAIK the S7 1500 allows up to 3 concurrent requests, I doubt if other PLC's actually support more than 1 request at a time though (but it's negotiated during communication setup, so we're still safe). Because a second (and third) request can already be queued at the PLC you can effectively have reads/writes processing almost continuously as long as network latency is low enough. OTOH if latency is higher this elimates the need for the roundtrip to be completed, theoretically providing almost 50% of a performance improvement. Anyway, Sally7: 🚀
Now with this change it's possible to read multiple responses in one go, while only the first response is processed.
That would be bad 😢 Sorry therefore. As for the release: you can "unlist" the package from search-results. The url should be https://www.nuget.org/packages/Sally7/0.11.0/Manage
No worries. I'm feeling a bit off this week (having a cold, sick child) so I thought let's do this! and while I've skimmed through the code and your initial message multiple times only now I suddenly noticed the issue.
Also, I knew about unlisting, but initially thought I'd leave it as is. I now unlisted it, I guess we'll have this sorted soon anyway.
a ValueTask (to my knowledge) is only allocation-free when the execution is synchronous
Correct -- when no advances mechanism like VT-pooling are used. My motivation for using the VT is that the socket-methods SendAsync, and ReceiveAsync with VT can be used, thus avoiding an allocation for a Task over there, as the VT in the sockets is based on
IValueTaskSource<TResult>, and that instance is cached. Now I had another thought about the SocketAwaitable -- maybe my mind got mis-routed due the work for sockets in the runtime-repo with a focus on VTs... SocketAwaitable is a good implementation too, so now I'm not sure if there are real benefits of the VT. Will need to investigate that a bit more.
Actually SocketAwaitable also avoids the Task allocation, but then of course you need to take care of recycling the SocketAwaitable to avoid allocating those instead of Tasks. In Sally7 that was fairly easy though. In cases where that's not so easy, it's probably better to make use ValueTask methods.
Your last benchmark actually shows a higher mean and error than second to last
Wondered the same, my conclusion was network latencies between the two different machines (PLC ran inside an VM) used in the benchmarks. So for these I would read them with caution.
I'm actually doing all my development on a laptop (with a desktop i9 9900K though), if I unplug the power supply I can't reliably benchmark duration at all. Also quite funny to see that BenchmarkDotNet immediately needs a larger amount of cycles to establish a 'reliable' result.
and while the number action allocations is reduced the number of AsyncTaskMethodBuilder allocations has increased.
I should measure the total count of operations (reads) performed in order to take these into the relation. Being lazy, I just put in the ratio of AsyncTaskMethodBuilder to action delegate allocations, as a rough measure / relation.
I understand, I'm not sure if that relation has any significance though 😜
Could you perhaps benchmark this again
Will do (tomorrow).
Thanks, no need to hurry (it's nothing like skiing 😆). I need to see if I can get something reliable for benchmarks into the repo so that anyone can easily reproduce results. I think I've done all my benchmarking against a sample project that I only have locally or against a real PLC at a customer, both aren't pretty.
There was a problem hiding this comment.
PTAL at #25
Theres (too much) description for the investigation.
Thanks for pushing me to investigate this, I find it very intersting. It's like in skiing. Need to push to the limits and beyond 😉
|
ad ad POH: |
No worries, it's actually funny how the compiler-safety vs inference is a pro for one and a con for the other. I'm also unaware of what other (larger) projects are using, because for the sake of compliance I would consider different code styles in open source projects. Actually professionally I'm not using underscore prefixes for fields. Personally I'd like to change that, but the team prefers to stick to camelCase (because that's what they're used to). Anyway, it doesn't bother me, otherwise I would've requested changes. Maybe my wording (not fond of) wasn't the best either, I guess having that as one of the two remarks should count as a compliment 😉
I the end I was thinking the same shouldn't be an issue.
I agree, this is out of the scope of Sally7. Actually for our case with 1000s of concurrent reads Sally7 in no way will be the bottleneck at this moment. I also don't have any performance figures for how fast we're actually performing the reads (and writes, but reads are far more important in our case), it has always been fast enough so priority has always been in other areas. Anyway, thanks again for your contribution! |
Description
Reading values from a PLC was run with a profiler, there some allocations appeared that could be avoided. This PR tries to reduce some of these allocations.
Some APIs needed for this are only available beginning with .NET 5, hence a new build-target was added.
Benchmarks
Benchmarks for reading from a SoftPLC
The PLC is run in virtual machine (https://github.com/fbarresi/SoftPlc docker), and simple short-values are read.
Measured time isn't that accurate here (network latencies, etc.), and they are quite flaky, but my main point is reduction of allocations.
Baseline
Custom memory pool
As mentioned above a profiler showed allocations for the default (= shared) memory pool.
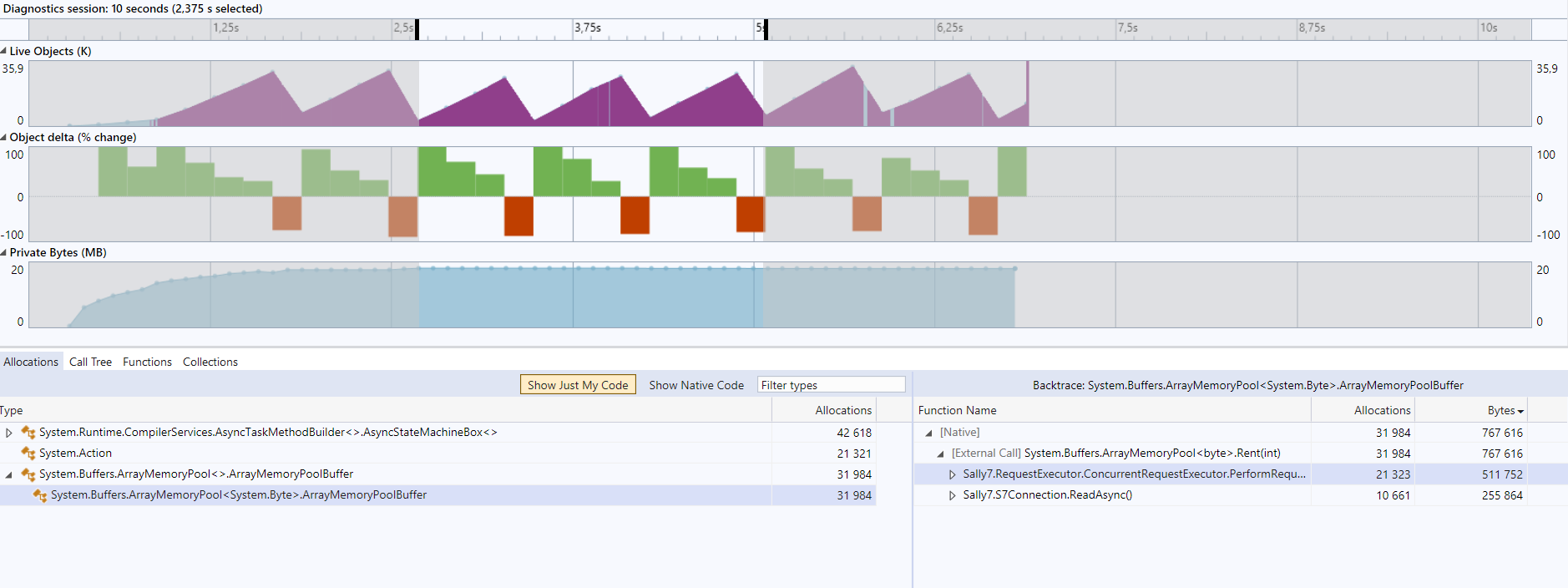
Before:

After:
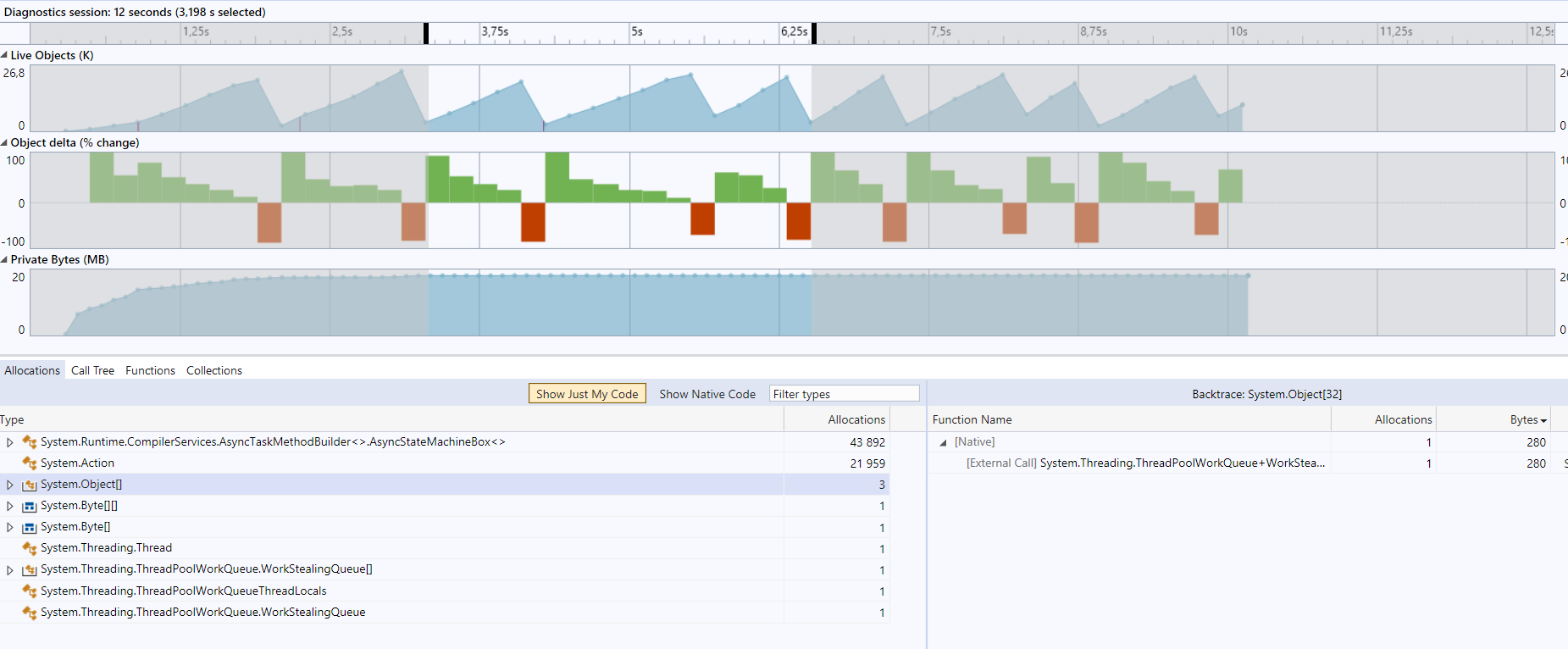
The custom memory pool
Sally7MemoryPoolhas the advantage over theArrayPool<byte>.Sharedthat the memories are created from already pinned arrays (on .NET 5 onwards only), so that pinning the Memory is free, and pinning the memory needs to be done in the socket.Final
Custom memory pool + ValueTask (VT) based socket operations (for > .NET Standard 2.1)
Note that the ratio of allocations from
ActiontoAsyncStateMachineBox<>got better from 21.959 / 43.892 to 13.461 /53.836 -- so less allocations for action-delegates are needed.
As the code for .NET 5 and .NS 2.1 is quite different from the code for older runtimes (sometimes referred as "desktop"), two separate cs-files are created, and included via settings in the csproj-file, instead of using conditional compilation.
Note: the difference of 72 bytes to the previous step (custom memory pool) is exactly the size of a task (that is saved by the value task).
The VT based version tries to read as much from the socket, namely the
SocketTpktReader, so ideally can avoid some further reads, as all data is already there.Benchmarks for the custom memory pool
To demonstrate the benefit of the custom memory pool a bit further, a benchmark that "simulates" a socket operation. I.e. rent a memory from the pool, pin the memory (for the IO-operation), then unpin and return the memory to the pool.
For .NET 5.0, and newer, the arrays are allocated on the pinned object heap (POH). Hence pinning the memory is free (or at very little cost), whilst pinning a memory, where the backing array isn't pre-allocated, has quite a huge cost. That's the main reason for the 3x speedup.
Benchmark code