Accelerating Mie scattering codes for exoplanet cloud opacity calculation using machine learning. (Potential application: future JWST data.)
All-in-all, complex non-linear relationships between 16 molecular species were learned across a variety of conditions spanning many orders of magnitude.
The training data is incredibly sparse, only millions of samples from numerical codes with 18 free parameters, some of which vary by many orders of magnitude, and all of which have complex non-linear relationships with the rest.
A mean absolute error of 0.7% was achieved with a one in a thousand error of 5%.
The final model is incredibly simple; it has only a few hundred parameters, making it an efficient accelerator.
This is some data of a single species (enstatite). In general, data is sampled from a complicated non-uniform random distribution of the 16 species we designed that should somewhat reflect real exoplanet atmospheres. The existence of one species affects the behavior of all the others.
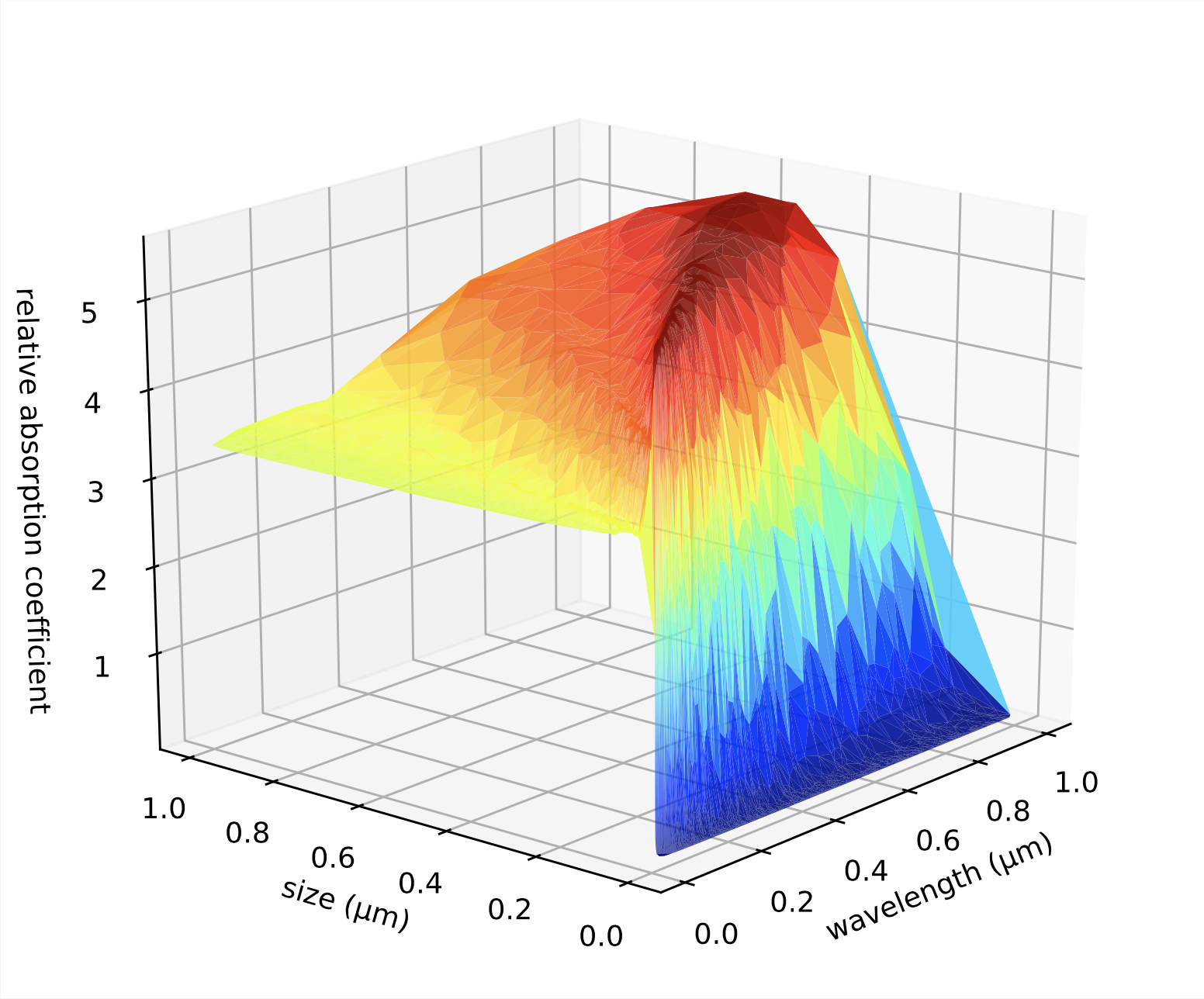
Understand that the model wasn't trained on the above data. The real training data is extremely sparse and probably doesn't contain a single data entry of a composition that even resembles enstatite, let alone it having points for various sizes and wavelengths as shown.
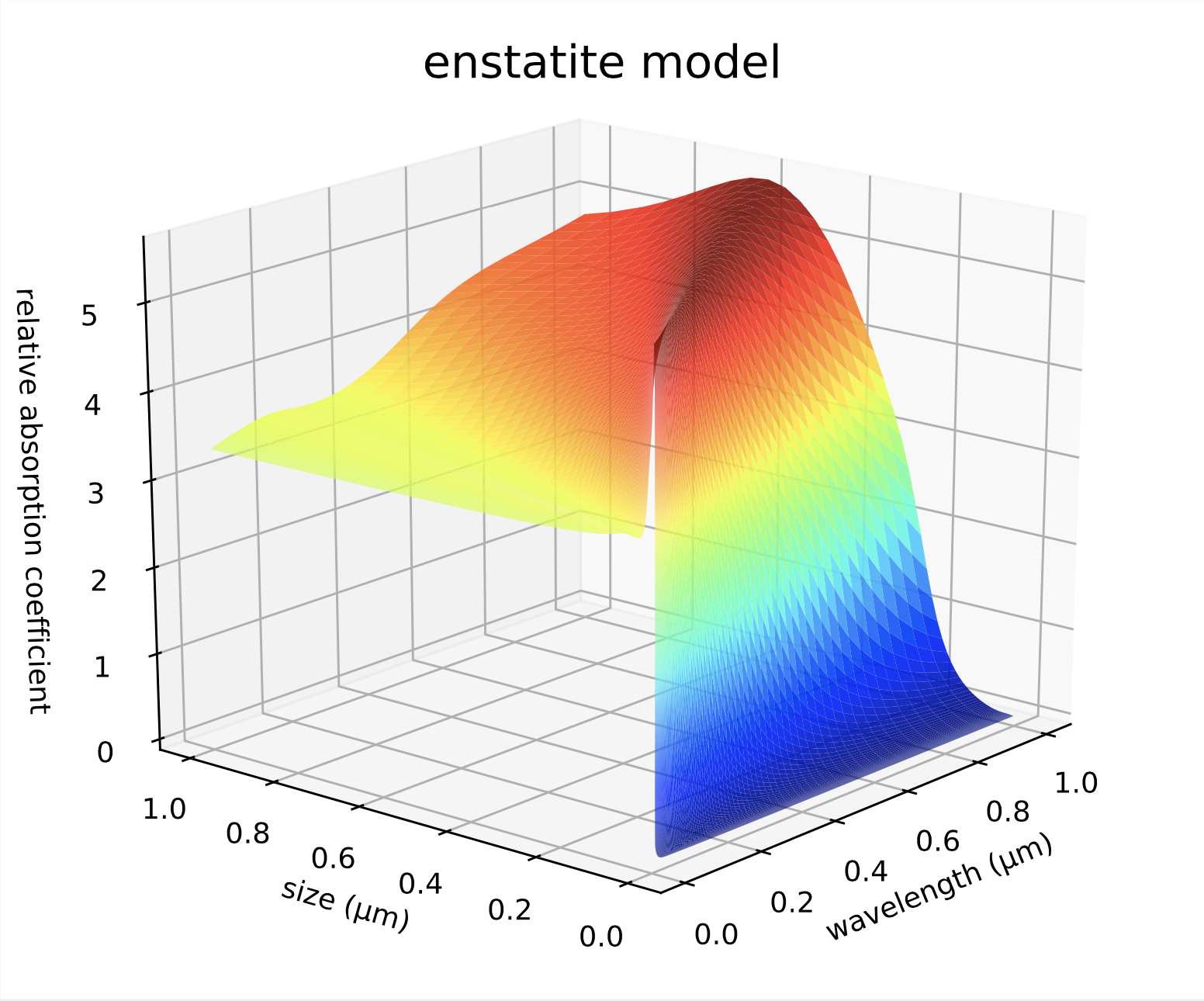
Here the model is performing on the very specific example of enstatite. Due to careful preprocessing, the sharp origin and other more qualitative aspects of the distribution are maintained. This is important for the application (integration).
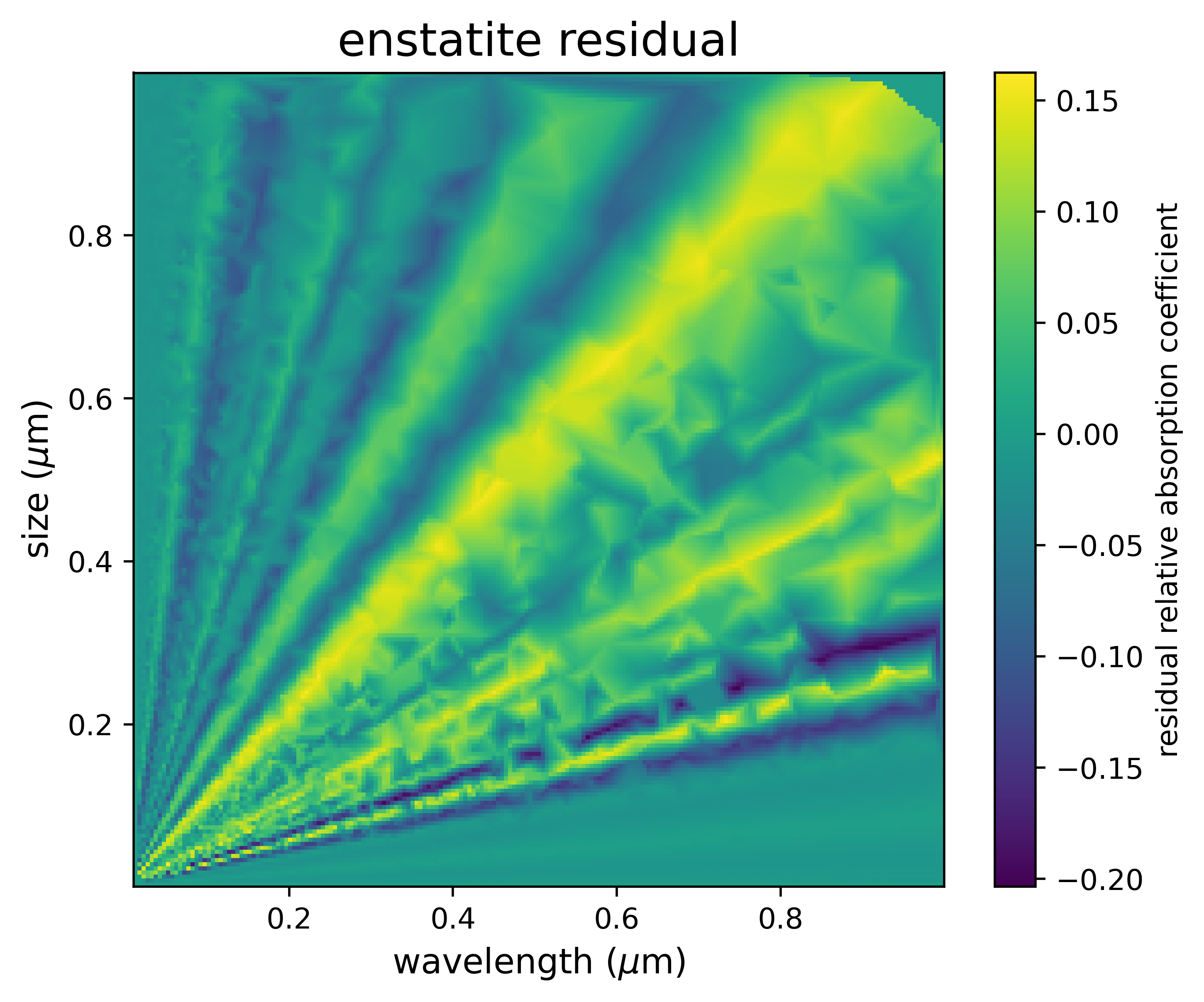
The model's performance is analyzed through various statistics of residuals when subtracting from an unseen dataset.
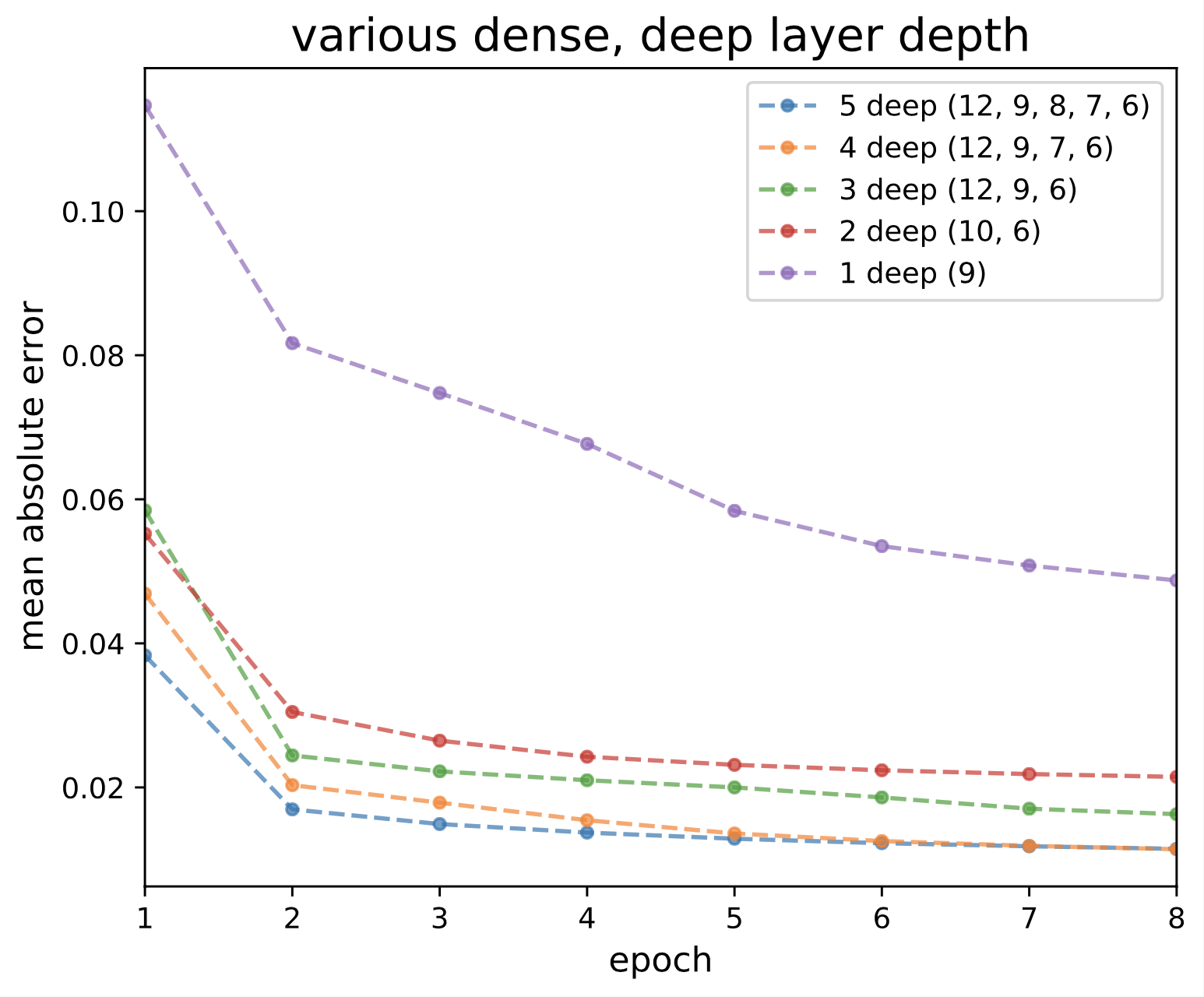
Much preprocessing and hyperparameter optimization were necessary to not only achieve these results, but also reduce the parameter count of the model while keeping the high accuracy.
Here for example we find that a particular 5th deep layer only slows down the model for no gain.