Install plugins from pyproject.toml (+config) #1461
Comments
|
In case anyone finds this between now and a proper solution, this works quite well to solve half of it. [tool.pdm.scripts]
post_install = "pdm plugin add plugins/pdm-plugin-torch" |
Relates to #56. Also see: pdm-project/pdm#1461 This adds a set of new commands to pdm: ## `pdm torch lock` which generates a common lockfile for a set of torch versions; cuda, CPU, and rocm. Each lockfile is resolved independently of the primary lockfile, as well as each other. The plugin currently has the following configuration options: ```toml [tool.pdm.plugins.torch] torch-version = "torch==1.10.2" lockfile = "torch.lock" enable-cpu = true enable-rocm = true rocm-versions = ["4.2"] enable-cuda = true cuda-versions = ["cu111", "cu113"] ``` It wouldn't be outrageously hard to just make this much more general, this is quite hardcoded. ## `pdm torch install API` Picks one of the APIs that has been configured above and installs it into the current venv. For the one above, it'd support `cpu`, `cu111`, `cu113`, and `rocm4.2`. Also has the `--check` flag to ensure everything is in sync.
|
I doubt whether it is good behavior if your globally installed PDM changes from time to time depending on what project you are working on. Maybe we can learn from lektor to install project-wide plugins in an isolated location and add that path to the PDM. |
|
Yeah; I don't think installing them globally is necessarily good. On the other hand, if you already work in multiple repos and some need plugins, that issue already exists. I don't think this'd necessarily make it worse. |
|
Also, we open-sourced the repo with the plugin yesterday here: https://github.com/EmbarkStudios/emote/tree/main/plugins/pdm-plugin-torch, in case anyone finds this while maybe searching for torch. |
|
I think this need to be splitted in 2 use-cases:
What do you think ? |
|
The first use-case is not related to this issue, and I'm not sure how it'd be relevant to plugins. I kind second is OK; but I'd prefer a virtual-environment based solution instead with automatic installs. I'd be fine with that as a temporary solution/stopgap, however. But it's not too far from hook workaround, and I can do the same with script too. However: if we can combine that with a configuration solution I think we could get something good -- my structured example in the original post lets us combine configuration + dependency in one place. I.e., let's not focus only on installing - it's only half of the good solution. :-) |
|
This is an awesome feature! by adding to my pyproject.toml, I am now able to use pdm pack from a zipapped pdm. Thanks a lot! |
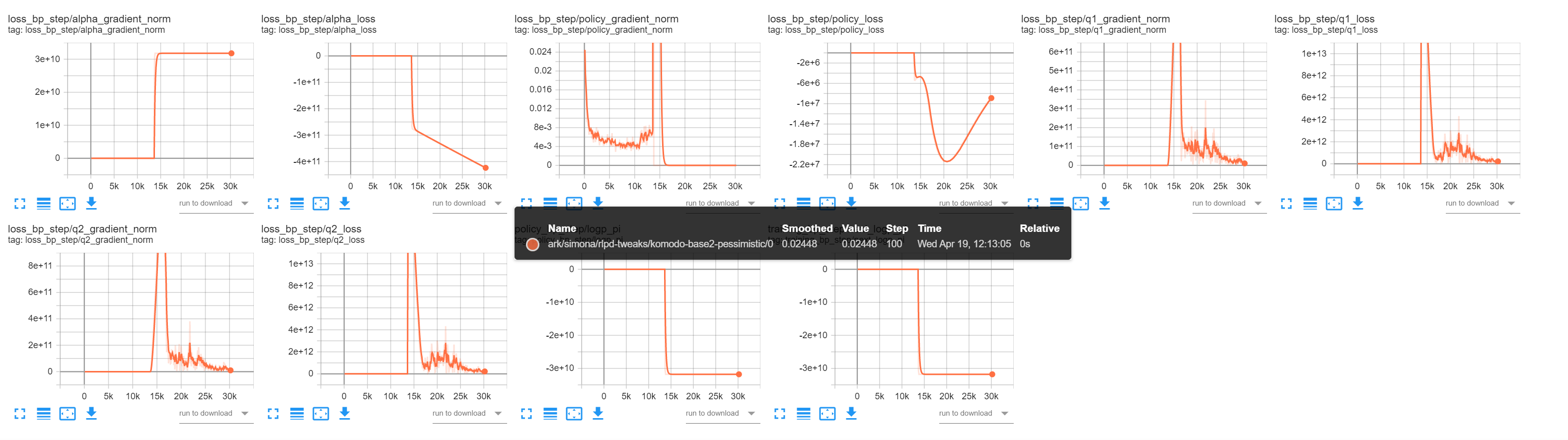
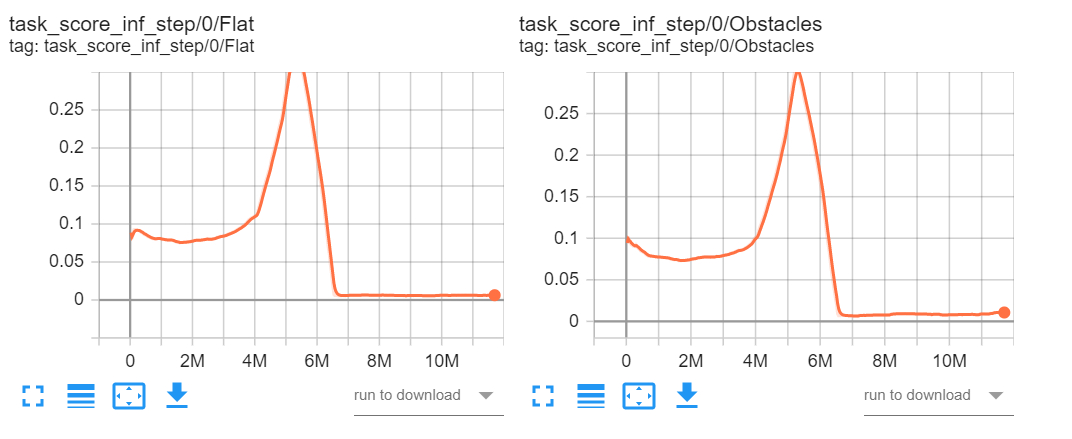
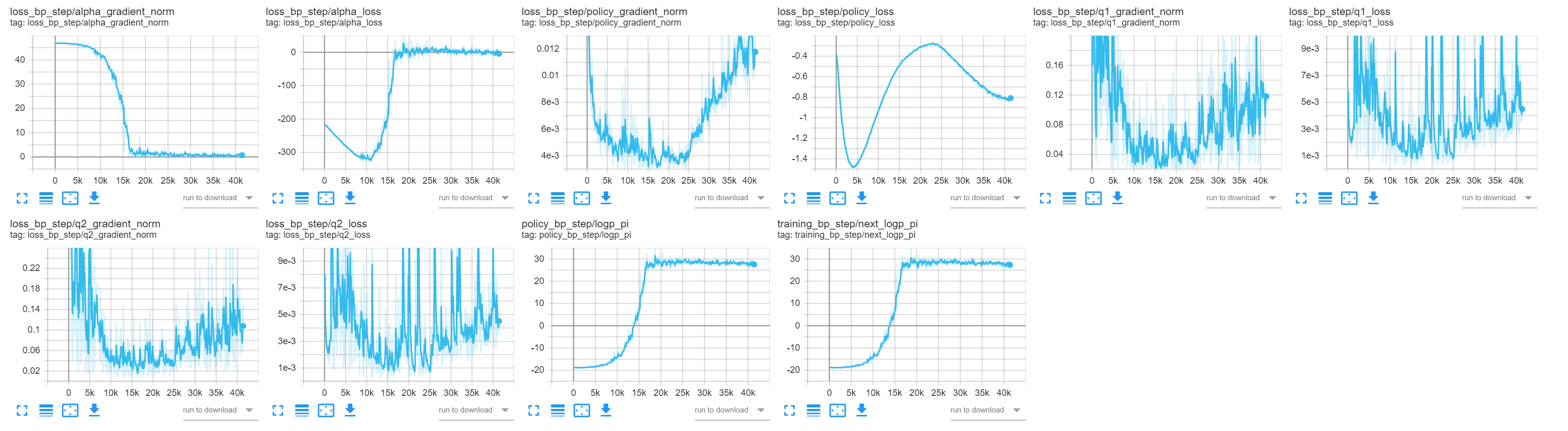
* Initial commit * Updated callback API and main loop * Added back optimizer, changed log syntax * Removed sequence builder * Added network constructors * Black lint * Updated constructors for Losses * Linted sphinx * Stubs for hit the middle * Made README md * Fixed README md. * Initial failing test added * Fixed warnings when tests run * Refactored Transition format * Work to get the agent proxy abstraction right * Updated lock file * Simplified APIs for policy, agent and memory * Fixed how obs are fed to network * Added some installation notes * Added initial translation of memory * Added dataclass foor spaces * Added in sequence builder as a memory proxy * Renamed memory to table * Renamed sequencebuilder to memory/memory * Made most of new memory work * Added MIT license * Moved License * Updated README * Updated deps * Made hit the middle train and log * Updated pyproject.toml * Cleaned up memory code a bit * More memory cleanup * Updated the documentation * Removed unnecessary SAC Network class * Added docs, made inits use parameter names, removed target q * Fix docs for alpha * Made network construction in test more explicit * Made test pass * Made memory table creation logic be in classes instead of factory functions * Removed some indirection in mem helper fns * Classified the builders and adaptors * Added feedback from code review * Made open source readme changes * Changed cycle length to be callback specific (#5) * Made checkpointing work and tested (#6) * Cleaned up checkpoint logic * Made test_htm work as a test * Checkpointing works and has tests * Rename to Emote (#7) * Search and replace in files * Renamed directory * Fixed readme and index to match new name * Moved to Conda (#8) Downgraded to python 3.8 and moved to conda for compatibility with Isaac. * Moved to conda * Updated to conda reqs, fixed typing * New nicer readme (#9) * Minor README visual tweaks (#10) Part of #2 * Removed all mentions of Hive (#11) * Ignore the runs dir where tb logs (#15) * Make train on lunar lander (#14) * Add setup file * Fix stepping bug * Add ortho weight init * Add bp_samples to state and correct bp_step to bp_samples in trainer * Add lunarlander test * Add rendering and warmup steps to collectors * Disable rendering for hit the middle * Revert bp_step to bp_sample change * Renaming * remove req file * Address comments and build network in test file * Move collecting warmup steps to GymCollector * Remove bp_samples * Fix bug * address comments * Remove unused code * Add docs publishing pipeline and switch back to poetry (#28) * n-step TD, gpu training, episodic rewards, high LR nan fix. (#30) * nstep bootstrapping * episodic reward logging * working gpu training * clamped log std * delete conda env and pypi file (#32) * Run black and isort on CI (#31) * Sanity-checks (#33) * add pre-checks for PR validity * Don't install cuda-version of torch on CI (#35) * Check line-endings in CI and remove all CRLF (#34) * add line-ending check step to CI * Fixes SAC algorithm logic. Simplifies distribution code. Fixes terminal adaptor reshaping. (#38) * Fixes SAC algorithm; we now use the ln(prob) not the -ln(prob) from the distribution code. * Simplifies distribution code. * Fixes terminal adaptor reshaping. * Performance metric logging. * Better weight initialisation. * Use a custom base image for CI runs (#36) * use a custom leaner base-image * Add learning rate schedule (#39) * Add learning rate schedule * Fix formatting * Add docs * video logging (#42) * bump poetry in CI (#45) * bump poetry in CI * update lockfile * regenerate lockfile with 1.2.2 * Add bandit CI step. * switch to PDM (#49) This is a switch to PDM; which I mentioned last week as one candidate. There's a long myriad of considerations (not all appropriate for this forum), but ultimately PDM looks to have a healthier development flow, works for the usage we have, and is a minimal step from what we have already. This isn't a permanent commitment, and we can re-evaluate it later. This will stick while we nail down publishing flows etc; unless we run into huge issues during that process. * fix doc publish (#50) PDM ends up confusing the local package with the pypi package in some situations. This changes the name of the project to `emote-rl`. We should likely change all code to use `emote_rl` too for consistency, but it's not a requirement. * Jack/vision (#48) * Adds conv encoders to allow training using vision. * Adds an example vision based training setup showing how to use a shared encoder for all SAC network columns. This also demonstrates how to prevent gradients from flowing from the policy to the conv encoder. * Adds CURL contrastive learning module (an example that uses this, and takes both high level features and images as input, can be found in Emit). * Adds image logging. * Makes LR schedules optional inputs. * Add package and test steps (#44) * ADR: Versioning and release flow (#55) * Add pre-release with auto-generated changelog and GHP docs (#51) This ended up being a bit more than intended; but essentially adds CD based on Github Actions. Github actions makes it easier to consume secrets; especially in relation to GitHub. We'll keep Buildkite for now for regular CI; but it might make sense to move later as well to avoid having two CI systems. This doesn't cover regular releases, that'll be a separate ADR so we can discuss release flows. * Add plugin to manage torch versions (#58) Relates to #56. Also see: pdm-project/pdm#1461 This adds a set of new commands to pdm: ## `pdm torch lock` which generates a common lockfile for a set of torch versions; cuda, CPU, and rocm. Each lockfile is resolved independently of the primary lockfile, as well as each other. The plugin currently has the following configuration options: ```toml [tool.pdm.plugins.torch] torch-version = "torch==1.10.2" lockfile = "torch.lock" enable-cpu = true enable-rocm = true rocm-versions = ["4.2"] enable-cuda = true cuda-versions = ["cu111", "cu113"] ``` It wouldn't be outrageously hard to just make this much more general, this is quite hardcoded. ## `pdm torch install API` Picks one of the APIs that has been configured above and installs it into the current venv. For the one above, it'd support `cpu`, `cu111`, `cu113`, and `rocm4.2`. Also has the `--check` flag to ensure everything is in sync. * Add ADRs to deployed documentation (#60) This includes all ADRs in the deployed documentation. Since they are written in Markdown, I've also added support for writing docs in Markdown. This can be used anywhere, using the syntax from myst-parser. <img width="837" alt="image" src="https://user-images.githubusercontent.com/8234817/197825447-b0c3d5ec-975d-4e72-97f4-71ec254736eb.png"> * Create release flow on-tag (#57) This should release to PyPi and GHA when tagging a release on main. * prepare changelog for release (#61) * Switch CI to PDM 2.2.0 (#62) Fixes #59 as 2.1.6 was the expected version. * use ref_name instead of ref when releasing (#63) * use large container for pytest (#64) Switches to use a larger container for pytest, which should hopefully make it slightly faster. * Update readme links and add PDM badge (#67) * Ensure `latest` tag has proper contents and commit (#66) This ensures the nightly release points to the proper tag and contents. Previously they'd keep old files and the sha wasn't getting updated. * allow specifying multiple dependencies for pdm-plugin-torch (#68) This allows emit to use the same plugin to pull in `torch` and `torchvision` together. * Optimize CI performance with preinstalls and dedicated CPU (#69) Noticied when working on $OTHER_REPO that there's some wonkiness with how we install gcloud and setup our CI tasks that leads to subpar performance. This change should have very little impact on regular running but when the builds cluster is under heavy load we'll not degrade as heavily as we have in the past. In practice we have ended up running on "any" resource available. I noticed this because we had crammed a bunch of pytest runners into a single available CPU slot, causing some 10-second checks to run for 10+ minutes. * bump pdm (#71) Bumps PDM from 2.2 -> 2.3. Haven't tested 2.4 so waiting with that upgrade. * some lints (#77) Some unused imports, spelling... * Also ask for tests to be formatted (#83) * Added some help for myself next time I install it * changed test to check reward instead of loss (#82) Created a FinalRewardTestCheck callback that checks the scaled reward. The FinalLossTestCheck in the HTM test is replaced with FinalRewardTestCheck which raises an exception if the reward is lower than -5. * make input key configurable for feature agent proxy (#79) I don't think it makes sense for this to be hard-coded. * Add memory warmup waiter (#78) * Add pipx, pdm2.4 and swig to CI (#84) * rename torch-cpu feature to torch (#76) * remove unused file (#86) This is handled with the optional group nowadays. * Add system performance logger (#81) A plugin for logging the RAM, CPU and (later GPU) usage of the process. * enable exporting ONNX policies for Gaussian MLPs (#80) First version of ONNX exporting, only for Gaussian MLPs. The need to inject the epsilon is a bit painful right now but we should iterate on that. * Use pdm-torch-plugin from PyPi (#88) * Change minimal version to Python3.9 (#87) * prepare release 23.0.0 (#89) * [x] Upon needing a release, create a PR: * [x] Update `CHANGELOG.md` to ensure it contains all relevant changes. You can base this off of the nightly changelog. * [x] Based on the above changes, set a new version in `pyproject.toml`. * [x] Replace the heading in the changelog * [x] Add diff labels at the bottom. - [ ] Pull the new main, and tag it with `git tag -a vNEW_VERSION COMMIT_HASH`. - [ ] Push the tag with `git push vNEW_VERSION` - [ ] Make a new PR that adds back the "Unreleased" heading in the changelog. * bump release script * use input_key in FeatureAgentProxy.input_names (#90) Missed connection between two of my overlapping PRs * allow None in cycle to disable (#91) I think we talked about what cycle 0 means before @singhblom but I added a bug in the OnnxExporter by default to None instead of 0. And I think that is *more* correct as a value for "don't run". * Add missing dataclass decorator on MetaData (#92) * Add documentation about writing docs (#94) Adds a documentation page about working with documentation in different formats. Also adds two short commands (both in docs and pyproject) to work with docs files. * refactor LoggingCallback to LoggingMixin (#93) This changes LoggingCallback to be a mixin class instead. This decouples it from the callback system, making it reusable as a baseclass for proxies and other objects that live on the inference side. * Gym is replaced by gymnasium (#95) Co-authored-by: Tom Solberg <me@sbg.dev> * Improve error handling in memory (#98) Stops swallowing errors if we fail to insert data; and handles KeyError if we fail sampling. * Ignore pypackages (#100) Updating with PDM caused me to have 10k new files to add in git. Ignoring __pypackages__ seems sensible. * add LoggingProxyWrapper for the memory (#96) This adds a wrapper for the memory to capture metadata from the submitted observations. Also adds a few tests and some documentation about metrics in general. I'd start by looking at the test to usage, as well as the docs. * fix tests (#103) Broken error handling fixed in #98, broken (non-rebased) test introduced in #96. * Updated a few things missed in 3.8=>3.9 (#102) Some traces of python 3.8 remained, so I removed them. * simplify lockfile error (#105) With `pdm lock --check` setting since #62 and #76 automating the pdm torch lock this wasn't giving the right or a helpful error message. * Weights&biases logging integration (#104) Created a new callback WBLogger which is based on the TensorboardLogger and logs the same things to Weights&Biases. In order to not make _wandb_ mandatory as a dependency in case someone doesn't want to use it at all, it is only imported if the flag `--use_wandb` is set to True. Usage notes: After installing wandb, you can login by running `wandb login` in the terminal and pasting the API key found in your W&B user settings. Note that the entity to be used for the wandb initialization (where to create the runs/projects) is not hardcoded. Instead, it is taken as the default setting of the user, which should be set to _embark_ for the work accounts by default. If needed it can be changed either in the W&B user settings or by passing `entity="embark"` to `wandb.init()`. * Improve CI error messages (#107) * Ali/mbrl lib (#101) The implementation of the model-based RL code. --------- Co-authored-by: Ali Ghadirzadeh <ali.ghadirzadeh@es-aghadirzadeh-mbp.local> Co-authored-by: Ali <ali.ghadirzadeh@gmail.com> * missing init file (#106) Required for publishing the package. * add final step to trigger other repo (#108) See linked PR at bottom. * Missing return statement in AlphaLoss (#111) When trying to load a state dictionary for the alpha loss (e.g. from checkpoints), there was a problem with a None value being assigned. This came from a missing return statement in the function where the state dictionary is loaded, which is added here. * add atomicwrites dependency (#113) * Simona ali/tridays (#112) This PR fixes some bugs regarding memory (replay buffer) saving and re-loading. It also contains a test to ensure that memory saving and re-loading work fine. --------- Co-authored-by: spetravic <petravic.s@gmail.com> * Ali/mbrl tests (#110) Test functions for the MBRL implementation --------- Co-authored-by: Ali Ghadirzadeh <ali.ghadirzadeh@es-aghadirzadeh-mbp.local> Co-authored-by: Ali <ali.ghadirzadeh@gmail.com> Co-authored-by: Ali <ali.ghadirzadeh@embark-studios.com> Co-authored-by: Ali Ghadirzadeh <124602311+Ali-Ghadirzadeh@users.noreply.github.com> * fixed the input_key error (#114) Currently, input_key is hard-coded to "obs" for all mbrl functionalities. The new changes enable choosing input_keys as an extra arguments to the corresponding classes. * Add PDM 2.5.0 to CI and bump minimum version to 2.4.0 (#115) As per title. Bumps us to use 2.4 by default everywhere and adds support for 2.5 * ensure memory exports are readable everywhere (#116) atomic_writes (which is also unmaintained nowadays! 😱) unfortunately has restrictive permissions. By default, it'll only allow the owner to read or write. This is overly restrictive and sometimes leads to errors during cloud training. This PR ensures we expand those permissions to `u+rw g+w o+w`. * Hyperbolic tangent instability (#118) The current implementation of the action sampling using _RobustTanhTransform_ causes some numerical instability. This leads to the log probability getting extreme values, which then completely destabilizes the training and the creature fails to learn. <img width="1579" alt="image" src="https://user-images.githubusercontent.com/72068586/236229169-10f127b7-2802-4d25-8c49-9fcedf039c46.png"> <img width="536" alt="image" src="https://user-images.githubusercontent.com/72068586/236228787-cbe1a509-a798-4ce7-9441-9f2af49104fc.png"> _TanhTransform_ with cache_size=1 caches the original action values sent to the transform and returns them instead of doing the inverse transformation, which seems to prevent the instability issue. The results are in line with Cog training runs, and the creature is able to learn the tasks. <img width="1563" alt="image" src="https://user-images.githubusercontent.com/72068586/236229701-84d9ad28-e440-4774-a7c3-e2f8019f70fb.png"> <img width="545" alt="image" src="https://user-images.githubusercontent.com/72068586/236229984-950b34f7-2378-4a5e-8458-4c6d331c1e23.png"> * Fix branch filter for docs publish (#119) * ensure pending exports are processed per batch (#120) Otherwise client-triggered exports won't be processed leading to network timeouts. * remove unused exitsignal (#124) This is always passed in from the training host, so no need to define it here. * Upgrade Memory Warmup callback to handle exports and early shutdowns (#125) We've had a shim for this exports in production, and I've noticed it can block early shutdowns since it won't check the shutdown signal. * work around memory leak in torch.jit.trace (#126) Repro'd and confirmed using the methodology here: pytorch/pytorch#82532 We leak every single tensor in the model each iteration. I validated it by inserting the code from the above issue into test_htm_onnx and running `exporter.export` in a loop at the end. This is the objgraph growth per iteration: ``` tuple 16813 +44 dict 13502 +23 ReferenceType 5569 +22 type 3021 +22 Tensor 340 +8 StorageItem 31 +1 StorageItemHandle 31 +1 ``` Changing the code in this PR makes the growth only the following: ``` dict 12921 +1 StorageItem 132 +1 StorageItemHandle 132 +1 ``` * Add `checkpointer_index` constructor argument to `Checkpointer` (#128) There currently isn't the option to pick up from a certain `checkpoint_index` in `Checkpointer`. This can come in useful when wanting to load an existing checkpoint and keep training, adding further checkpoints later on. * detach images (#127) * fix version to work around urllib breakage (#121) The gift that keeps on giving... * Add Storage Subdirectory (#130) This allows optionally specifying the name of the subdirectory for the checkpointer and checkpointloader, with the default being "checkpoints". We also create the "checkpoints" subdirectory from here. This is done in emote to avoid code duplication in downstream projects and match our existing practices, and because 99% of the time, we want the subfolder to be called "checkpoints". * split callbacks.py into a package (#109) The callbacks.py file was getting a bit too large so this breaks it down into a package with dedicated files per domain. Also adds some more docs and probably picks up some lints. Also makes the import error for wandb a bit more helpful by chaining it with some info in case it's not imported and adds a test case for it. * Add support for custom weight decay optimizer (#129) Creates a modified AdamW (that inherits from the standard AdamW) as suggested in _[Efficient deep reinforcement learning requires regulating overfitting](https://arxiv.org/pdf/2304.10466.pdf)_. ModifiedAdamW disables weight decay for the bias, additional modules (such as LayerNorm), and specific named layers (e.g. the paper suggests excluding the final layer in the Q networks, which can be done by passing `layers_to_exclude = ["final_layer"]`). The function for separating the modules was adapted from a [PyTorch minGPT implementation](https://github.com/karpathy/minGPT/blob/3ed14b2cec0dfdad3f4b2831f2b4a86d11aef150/mingpt/model.py#L136) that is MIT licensed. * Fix simple doc error (#131) Looks like `reset_training_steps` causes training to start at bp_steps=0 when True, not False * Add protocol=4 to cloudpickle.dump (#134) This should prevent crashes when saving memory * update torch to 1.12 (#133) * Enable setting `device` for ONNX exporter (#135) This is necessary for GPU training as otherwise the args will be on the wrong device during tracing. * Add more logging to ckpt/onnx/memory (#136) * always flush after writing tb events (#138) I've seen some issues in cloud training where the NFS drive is receiving blocks out of sync, leading to Tensorboard reading zeroes, spotting an error, and then ignoring the file permanently. The error is the following: ``` [2023-06-02T19:18:24Z WARN rustboard_core::run] Read error in /tmp/tensorboard-logs/ts/ml-inf/test-8h/0/events.out.tfevents.1685731159.brain-8156-wjjg5.1.1: ReadRecordError(BadLengthCrc(ChecksumError { got: MaskedCrc(0x07980329), want: MaskedCrc(0x00000000) })) [2023-06-02T19:42:22Z WARN rustboard_core::run] Read error in /tmp/tensorboard-logs/ts/ml-inf/test-8h/0/events.out.tfevents.1685731159.brain-8156-wjjg5.1.0: ReadRecordError(BadLengthCrc(ChecksumError { got: MaskedCrc(0x07980329), want: MaskedCrc(0x00000000) })) ``` It does sound like the following: https://linux-kernel.vger.kernel.narkive.com/asPTesqS/nfs-blocks-of-zeros-nulls-in-nfs-files-in-kernels-2-6-20. This might be a sufficient change, or we might need higher fidelity of flushing. This is the upstream issue, which also occurs with torch: tensorflow/tensorboard#5588. However; torch has no reported bugs for this, likely because it only occurs when using TB. It might also be some error in the shared drive setup, but I'm treating this as a the lower likelihood option right now. * check for double-init episodes (#123) @spetravic noticed an episode where we had one too few rewards; will try cloud training with this and see what shows up. * Add logging (#140) Added reporting functions that can report and log additional data and histograms. Also this fixes the logging of the cumulative values, which were not being updated before. * fix docs build (#141) This fixes a few missing classes and a missing graph in the docs. * Simona/fix logging (#144) 1. Fixes my own code added in #140 for histogram logging, as it was missing `.items()` to properly iterate through the dictionary when sending to the writer. Also, PyTorch complains about getting a deque as it expects a numpy array, torch tensor, or caffe2 blob name, so now the deque is converted to a numpy array. 2. Fixes wrong key splitting in _log_windowed_scalar_ for overriding the window size. * Agent proxy that supports multiple input keys (#143) At the moment, we have agent proxies that support only one input key. These don't support the case of multiple parts in the observation, for example both features and images. I wrote a new agent proxy that iterates through the given keys and creates a dictionary where all parts of the observation are stored with their respective keys. The policy can then handle these as needed. Is this a good way to approach this? * update pdm-plugin-torch (#145) 23.1.1 contains a bugfix for a crash in some situations. * Add Conv1d encoder and update Conv2d encoder with option to flatten (#142) I added a Conv1d encoder which takes as input _(batch size, channels, length)_, or _(batch size, length, channels)_ if `channels_last=True`, following the example of the Con2d encoder. I also added the option to directly add a `nn.Flatten()` layer, instead of having to append one later on, but the _flatten_ parameter can be set to False if needed. Also, I updated the existing CURL callback to match the changes done to the Conv2d encoder. * updating the checkpointer and checkpoint loader (#146) Made some updates to the Checkpointer and Checkpointloader as follows: * Removed the extra input arguments for loading networks and optimizers. Now, you can only load a list of callbacks. However, added an additional input to the Checkpointloader class. When set to True, this input instructs the loader to exclusively load the neural network parameters, disregarding the state_dict of other callbacks. This feature is useful in scenarios where you need to copy a network from one callback to another or when you prefer not to load other callback parameters. Both Checkpointer and Checkpointloader rely on a list of callbacks rather than a dictionary. To ensure the correct loading of callbacks, we store a corresponding list of names when saving the checkpoints. These names serve as references during the loading process. The names are loaded from the callback names. Callbacks without a name field are discarded. An error will be raised in case repetitive names are given. * Fix alpha loss load_state_dict fn signature and load bug (#147) The alpha loss did not get the updated load_state_dict fn signature, and it also had a bug where loading the alpha value would replace the python object reference, causing the other loss functions depending on it, such as the PolicyLoss, to use an invalid alpha value. This PR fixes these two issues. * Switch order of checks in log_windowed_scalar (#148) For keys that override the default window length, we are separating the original key in two parts: the first one which gives us the length, and the second one which is the actual key we want to use for logging in the _windowed_scalar_ dictionary. For example, for a given key "_windowed[100]:**score**_", we will log using the key "_score_". Next time that same value is sent to the logger, it is sent as "_windowed[100]:score_" again, but that key doesn't exist in the dictionary as we logged it using "_score_". So we enter the if-condition where we split the key, get "_score_" as the key we want to use for logging, and create a new deque with that key overwriting the data contained there previously. By switching the order of the checks, we first split the key if it contains "_windowed[_" and then check if the obtained key after splitting exists in the dictionary, which then appends the value to the existing deque. * Update windowed scalar (again) (#149) After fixing the overwriting problem in #148, I found that by logging using the split key we cause problems in other places where we request data from the dictionary. By the same logic as #148, when we want to get logged data we would request the original key, e.g. "windowed[100]:score" which doesn't exist in the dictionary, so we don't get any value back. Anything that depends on these values is then broken. Instead of splitting the key in a bunch of other places, this code uses the original key in the dictionary and then splits it only for logging to the writer. * Remove _inf_step from tb logs (#151) Why do we suffix this with inf-step? It gets very noisy and makes it much harder to compare the graphs between cog and emote. Could we remove it while we're debugging at least? * Orthogonal init for conv as well (#152) * Change check for bias initialization (#156) The current check raises RuntimeError: Boolean value of Tensor with more than one value is ambiguous * add PDM 2.6 and 2.7 to CI image (#153) Want to look at upgrading our plugins quite soon, this is a good initial step so I can start testing on CI. Also adds `--pip-args='--no-cache-dir'` which reduces image size a tiny bit. * add optional per-parameter logging for loss callbacks (#158) * setup multi-python image (#160) Updates the base CI runner image to use pyenv to provide multiple python version using pyenv. This should allow us to reuse this image for all our repositories. See `install-repo.sh` for how to initialize pyenv and select a Python version. * Simona/onnx (#161) Creates a copy of the policy for exporting to avoid the interference of the training and inference loops * Simona/add conditions (#162) - In the Q target updates, terminal masking was used by default, and now the option is added to deactivate that when needed (+ some updates to the docstring) - In the CURL loss calculation, the max was subtracted by default, as in the original paper. When used together with the temperature variant (which is different from the original paper), it led to problems with the gradients and loss not changing. A condition is added now to only remove the max if not using temperature. * Simona/inits (#163) The [Pytorch recommendation ](https://discuss.pytorch.org/t/conv-weight-data-vs-conv-weight/83047/2) is to use weight/bias itself instead of using .data when initializing, which was used in the past but it was phased out at some point. The reason they state is that it could cause problems with autograd not tracking operations correctly, which AFAIK has not caused issues for us, but it's probably worth changing to keep up with the standard. * Make MemoryProxyWrappers forward methods to wrapee if they do not exist on wrapper (#164) This PR adds a `MemoryProxyWrapper` base class that all memory proxy wrappers should inherit from. This base class takes care of forwarding method calls that do not exist on the wrapper to the inner wrapped object. This solves problems where one would like to call a method existing on some inner wrapee but not on the outermost wrapper itself. * simplify agent proxy setup (#165) This was getting a tiny bit complex and I really want to stop hardcodinginput/output names here. I've tried cloud training with MLP agents -- I'd assume the features+images is equally changed as we're just reusing more code. * cherry-pick changes to reward-test-check (#166) Picking some changes from #150 to work towards landing that ~soon. * Upgrade memory serialization workflows (#167) This upgrades our memory serialization workflows to avoid pickling. This *also* removes the identity shenanigans we do when loading memories right now. Clients have to ensure loaded memories don't overlap with fresh memories. * add `OnnxExporter.add_metadata` (#168) This lets downstream users add things like configuration and hyperparameters. We should probably ensure we can override the basic ONNX metadata as well at some point, but not sure about the API so ignoring for now. ``` model_proto.producer_name = "emote" model_proto.domain = "dev.embark.ml" model_proto.producer_version = self.version_tag model_proto.model_version = model_version model_proto.doc_string = "exported via Emote checkpointer" ``` * Ali/genrl pr (#159) This is the implementation of GenRL algorithm in Emote. * use same line-length as other repositories (#171) We had the default of 88 characters here, while we use 100 in our internal repositories. The longer lines remove a lot of unnecessary line breaks in comprehensions in function signatures. * split state restoration from begin_training (#172) This ensures there's no specific ordering required between modules in begin_training, a bug and/or footgun in our old frameworks. * run flake8 on CI (#173) Normalizes CI between our repos, and we already have a checked in .flake8. Also adds a `pdm run precommit` to run all tests and lints. * Allow temp storage to grow to fit the largest requested data (#174) Some background for this change: For some AMP code I need to sample the same memory with two different dataloaders. One loader will always request less data than the other, and if that is sampled before the larger one, the larger data no longer fits in the temp storage. This PR changes so that we grow the temp storage if the data does not fit. Assuming the requested data sizes do not change over time, this will only reallocate at the start until the largest buffersize is sampled. What do you think of this? * Fix Lunar Lander Test (#177) The lunar lander trainer for SAC required a `policy` parameter for `create_train_callbacks()`, otherwise it wouldn't run. This PR fixes that. * Implement DQN and CartPole Test (#175) Adds the DQN Algorithm, as well as a corresponding CartPole test. The reward usually goes over 200 after around 25K episodes. Also moving sac.py and dqn.py to algorithms, and refactoring accordingly. * log memory timers (#179) This broke when we started adding more wrappers. * Implement Coverage Based Sampling Strategy (#178) This PR adds a sampling strategy that prioritises samples that haven't been visited yet over samples that have. The chance of an episode being sampled is inversely proportional to the amount of times it has been sampled. This is additionally weighted by an `alpha` parameter, where a higher alpha means more weighting of less-sampled episodes. A test is also added to validate that recently added samples have a higher chance of being chosen. * Add "latest_checkpoint" path to state_dict (#169) Doesn't quite mirror [this cog PR](https://github.com/EmbarkStudios/cog/pull/731/files), but ensures we have the path, as discussed with @tgolsson. Please let me know in case I misunderstood something. * Add Documentation for Cartpole Training (#180) Basic documentation on how to run the cartpole test, what the arguments represent, and how to track metrics in tensorboard. --------- Co-authored-by: Luc Baracat <luc.baracat@ad.embark.net> * Add schedules (#185) This PR adds a few schedules that can be used for adjusting parameters during training. * Rename get_last_val (#187) Yet another reminder to self to wait for Tom's comments before merging :( * Update AlphaLoss to support entropy schedules (#186) This PR adds support for entropy schedules in the AlphaLoss callback. Also I removed the multiplication term in the default target entropy value since it defaulted to a very small value (CC @AliGhadirzadeh) and now we have the option to set the target value directly instead of scaling the number of actions by changing `entropy_eps`. * Fix wrong `onnx.load_model` arguments (#188) We called this with a second argument that got ignored in onnx 1.14.1, but with 1.15.0, this is not legal anymore. Removing the second argument should fix this. * fix bug in logging timers (#189) This PR: * Adds an overrideable name to the memory TableMemoryProxy * Exposes that name as a property * Extends the proxy base to allowed reading properties from the inner classes * Uses the above property for logging * add pdm 2.9 and 2.10 to CI image (#190) * Upgrade to Python 3.10 (#184) Upgrades emote from 3.9 to 3.10 the main changes are: - You can now combine with statements, so instead of ``` with open('file1.txt') as file1: with open('file2.txt') as file2: bla ``` You can use ``` with ( open('file1.txt') as file1, open('file2.txt') as file2 ): bla ``` - Instead of using `Union`, you can now use `|`. So `name: Union[str, bytes]` to `name: str | bytes`. - `match` statements have been added, similar to rust, for datastructures The first two points have been adjusted in this repo, grouping `with`s together where possible and using `|` instead of `Union`s. Pdm had to be version 2.5.6 to properly update the lock files, otherwise it wouldn't work. * Upgrade to PDM 2.10 (#191) This upgrades to PDM 2.10 and `pdm-plugin-torch` to 23.4. As part of this I've removed both hooks - install now happens with `pdm install --plugins` and the lock will have to be explicit. This removes some unncessary magic and makes it more explicit. Will announce on Slack once merged. * Update Github Workflows for Python3.10 (#192) Since updating to python3.10, github actions failed as specifiying the python-version in the workflow files with only 3.10 got only parsed as 3.1. Setting this to 3.10.4 makes it find a proper build. This PR also separates the build-docs and deploy jobs, and runs the former whenever a PR is opened. * Properly set workflow file (#193) * Make LoggingProxyWrapper report `inf_step` if requested (#194) * Ali/amp (#195) AMP implementation * Add a joint memory loader capable of sampling data from multiple memory loaders (#181) This PR adds a `JointMemoryLoader` object that can sample data from multiple different `MemoryLoader`s. This is needed for a lot of imitation related training. * adding JointMemoryLoader to the init (#196) JointMemoryLoader is missing in the init file. * Use the pants build system instead of pdm --------- Co-authored-by: Martin Singh-Blom <martin.singh-blom@embark-studios.com> Co-authored-by: Martin Singh-Blom <vaftrudner@gmail.com> Co-authored-by: Johan Andersson <repi@repi.se> Co-authored-by: Riley Miladi <41442181+riley-mld@users.noreply.github.com> Co-authored-by: Tom Solberg <mail@tomolsson.se> Co-authored-by: Jack harmer <jack2harmer@gmail.com> Co-authored-by: Tom Solberg <me@sbg.dev> Co-authored-by: Jack harmer <jack.harmer@embark-studios.com> Co-authored-by: Tom Solberg <tom.solberg@embark-studios.com> Co-authored-by: Simona Petravic <petravic.s@gmail.com> Co-authored-by: Ali-Ghadirzadeh <124602311+Ali-Ghadirzadeh@users.noreply.github.com> Co-authored-by: Simona Petravic <simona.petravic@embark-studios.com> Co-authored-by: Ali Ghadirzadeh <ali.ghadirzadeh@es-aghadirzadeh-mbp.local> Co-authored-by: Ali <ali.ghadirzadeh@gmail.com> Co-authored-by: Ali Ghadirzadeh <ali.ghadirzadeh@embark-studios.com> Co-authored-by: luc <59030697+jaxs-ribs@users.noreply.github.com> Co-authored-by: klashenriksson <6956114+klashenriksson@users.noreply.github.com> Co-authored-by: Luc Baracat <luc.baracat@ad.embark.net>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Is your feature request related to a problem? Please describe.
Hello!
To solve some workflow issues with torch I've developed a plugin that I'm storing in the same repository as the main project. I want all developers to have access to this tool for ease of use. However; there isn't any (documented?) way of putting a plugin into pyproject.toml, including configuration. I tried putting it in dev-dependencies, but since
pdmruns in another environment it doesn't find the entrypoint.Describe the solution you'd like
I'd to be able to specify plugins and their configuration in the project.toml. The config part is roughly how I've done it today; but I'm just digging out the key from the
Project.pyprojectdata. The first part I don't think exists at all.A potential format version that's a bit more structured:
The text was updated successfully, but these errors were encountered: