前言:本文是讲的是如何配置pytorch版本的yolov3、数据集处理、常用的命令等内容。该库的数据集格式既不是VOC2007格式也不是MS COCO的格式,而是一种新的格式,跟着文章一步一步来,很简单。另外我们公众号针对VOC2007格式数据集转化为本库所需要格式特意开发了一个简单的数据处理库。
- 将github库download下来。
git clone https://github.com/ultralytics/yolov3.git
- 建议在linux环境下使用anaconda进行搭建
conda create -n yolov3 python=3.7
- 安装需要的软件
pip install -r requirements.txt
环境要求:
- python >= 3.7
- pytorch >= 1.1
- numpy
- tqdm
- opencv-python
其中只需要注意pytorch的安装:
到https://pytorch.org/中根据操作系统,python版本,cuda版本等选择命令即可。
在Windows下使用LabelImg软件进行标注:
- 使用快捷键:
Ctrl + u 加载目录中的所有图像,鼠标点击Open dir同功能
Ctrl + r 更改默认注释目标目录(xml文件保存的地址)
Ctrl + s 保存
Ctrl + d 复制当前标签和矩形框
space 将当前图像标记为已验证
w 创建一个矩形框
d 下一张图片
a 上一张图片
del 删除选定的矩形框
Ctrl++ 放大
Ctrl-- 缩小
↑→↓← 键盘箭头移动选定的矩形框
-data
- VOCdevkit2007
- VOC2007
- Annotations (标签XML文件,用对应的图片处理工具人工生成的)
- ImageSets (生成的方法是用sh或者MATLAB语言生成)
- Main
- test.txt
- train.txt
- trainval.txt
- val.txt
- JPEGImages(原始文件)
- labels (xml文件对应的txt文件)
通过以上软件主要构造好JPEGImages和Annotations文件夹中内容,Main文件夹中的txt文件可以通过以下python脚本生成:
import os
import random
trainval_percent = 0.9
train_percent = 1
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
接下来生成labels文件夹中的txt文件,voc_label.py文件具体内容如下:
# -*- coding: utf-8 -*-
"""
Created on Tue Oct 2 11:42:13 2018
将本文件放到VOC2007目录下,然后就可以直接运行
需要修改的地方:
1. sets中替换为自己的数据集
2. classes中替换为自己的类别
3. 将本文件放到VOC2007目录下
4. 直接开始运行
"""
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')] #替换为自己的数据集
classes = ["person"] #修改为自己的类别
#进行归一化
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOC%s/Annotations/%s.xml'%(year, image_id)) #将数据集放于当前目录下
out_file = open('VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOC%s/labels/'%(year)):
os.makedirs('VOC%s/labels/'%(year))
image_ids = open('VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('VOC%s/JPEGImages/%s.jpg\n'%(year, image_id))
convert_annotation(year, image_id)
list_file.close() 到底为止,VOC格式数据集构造完毕,但是还需要继续构造符合darknet格式的数据集(coco)。
需要说明的是:如果打算使用coco评价标准,需要构造coco中json格式,如果要求不高,只需要VOC格式即可,使用作者写的mAP计算程序即可。
其中保存的是你的所有的类别,每行一个类别,如data/coco.names:
person
classes = 1 # 改成你的数据集的类别个数
train = ./data/2007_train.txt # 通过voc_label.py文件生成的txt文件
valid = ./data/2007_test.txt # 通过voc_label.py文件生成的txt文件
names = data/coco.names # 记录类别
backup = backup/ # 在本库中没有用到
eval = coco # 选择map计算方式
打开cfg文件夹下的yolov3.cfg文件,大体而言,cfg文件记录的是整个网络的结构,是核心部分,具体内容讲解请参考之前的文章:【从零开始学习YOLOv3】1. YOLOv3的cfg文件解析与总结
只需要更改每个[yolo]层前边卷积层的filter个数即可:
每一个[region/yolo]层前的最后一个卷积层中的 filters=预测框的个数(mask对应的个数,比如mask=0,1,2, 代表使用了anchors中的前三对,这里预测框个数就应该是3*(classes+5) ,5的意义是5个坐标(论文中的tx,ty,tw,th,po),3的意义就是用了3个anchor。
举个例子:假如我有三个类,n = 3, 那么filter = 3 × (n+5) = 24
[convolutional]
size=1
stride=1
pad=1
filters=255 # 改为 24
activation=linear
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=80 # 改为 3
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
- yolov3
- data
- 2007_train.txt
- 2007_test.txt
- coco.names
- coco.data
- annotations(json files)
- images(将2007_train.txt中的图片放到train2014文件夹中,test同理)
- train2014
- 0001.jpg
- 0002.jpg
- val2014
- 0003.jpg
- 0004.jpg
- labels(voc_labels.py生成的内容需要重新组织一下)
- train2014
- 0001.txt
- 0002.txt
- val2014
- 0003.txt
- 0004.txt
- samples(存放待测试图片)
2007_train.txt内容示例:
/home/dpj/yolov3-master/data/images/val2014/Cow_1192.jpg
/home/dpj/yolov3-master/data/images/val2014/Cow_1196.jpg
.....
注意images和labels文件架构一致性,因为txt是通过简单的替换得到的:
images -> labels
.jpg -> .txt
具体内容可以在datasets.py文件中找到详细的替换。
预训练模型:
- Darknet
*.weightsformat:https://pjreddie.com/media/files/yolov3.weights - PyTorch
*.ptformat:https://drive.google.com/drive/folders/1uxgUBemJVw9wZsdpboYbzUN4bcRhsuAI
开始训练:
python train.py --data data/coco.data --cfg cfg/yolov3.cfg
如果日志正常输出那证明可以运行了
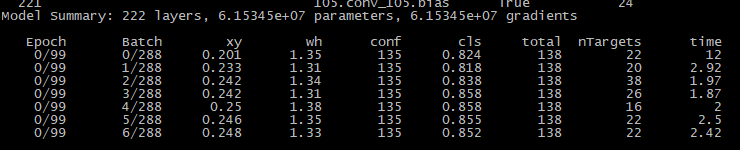
如果中断了,可以恢复训练
python train.py --data data/coco.data --cfg cfg/yolov3.cfg --resume
将待测试图片放到data/samples中,然后运行
python detect.py --cfg cfg/yolov3.cfg --weights weights/best.pt
目前该文件中也可以放入视频进行视频目标检测。

- Image:
--source file.jpg - Video:
--source file.mp4 - Directory:
--source dir/ - Webcam:
--source 0 - RTSP stream:
--source rtsp://170.93.143.139/rtplive/470011e600ef003a004ee33696235daa - HTTP stream:
--source http://wmccpinetop.axiscam.net/mjpg/video.mjpg
python test.py --weights weights/best.pt
如果使用cocoAPI使用以下命令:
$ python3 test.py --img-size 608 --iou-thr 0.6 --weights ultralytics68.pt --cfg yolov3-spp.cfg
Namespace(batch_size=32, cfg='yolov3-spp.cfg', conf_thres=0.001, data='data/coco2014.data', device='', img_size=608, iou_thres=0.6, save_json=True, task='test', weights='ultralytics68.pt')
Using CUDA device0 _CudaDeviceProperties(name='Tesla V100-SXM2-16GB', total_memory=16130MB)
Class Images Targets P R mAP@0.5 F1: 100% 157/157 [03:30<00:00, 1.16it/s]
all 5e+03 3.51e+04 0.0353 0.891 0.606 0.0673
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.409
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.615
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.437
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.242
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.448
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.519
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.337
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.557
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.612
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.438
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.658
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.746
mAP计算
- mAP@0.5 run at
--iou-thr 0.5, mAP@0.5...0.95 run at--iou-thr 0.7
可以使用python -c from utils import utils;utils.plot_results()
创建drawLog.py
def plot_results():
# Plot YOLO training results file 'results.txt'
import glob
import numpy as np
import matplotlib.pyplot as plt
#import os; os.system('rm -rf results.txt && wget https://storage.googleapis.com/ultralytics/results_v1_0.txt')
plt.figure(figsize=(16, 8))
s = ['X', 'Y', 'Width', 'Height', 'Objectness', 'Classification', 'Total Loss', 'Precision', 'Recall', 'mAP']
files = sorted(glob.glob('results.txt'))
for f in files:
results = np.loadtxt(f, usecols=[2, 3, 4, 5, 6, 7, 8, 17, 18, 16]).T # column 16 is mAP
n = results.shape[1]
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.plot(range(1, n), results[i, 1:], marker='.', label=f)
plt.title(s[i])
if i == 0:
plt.legend()
plt.savefig('./plot.png')
if __name__ == "__main__":
plot_results()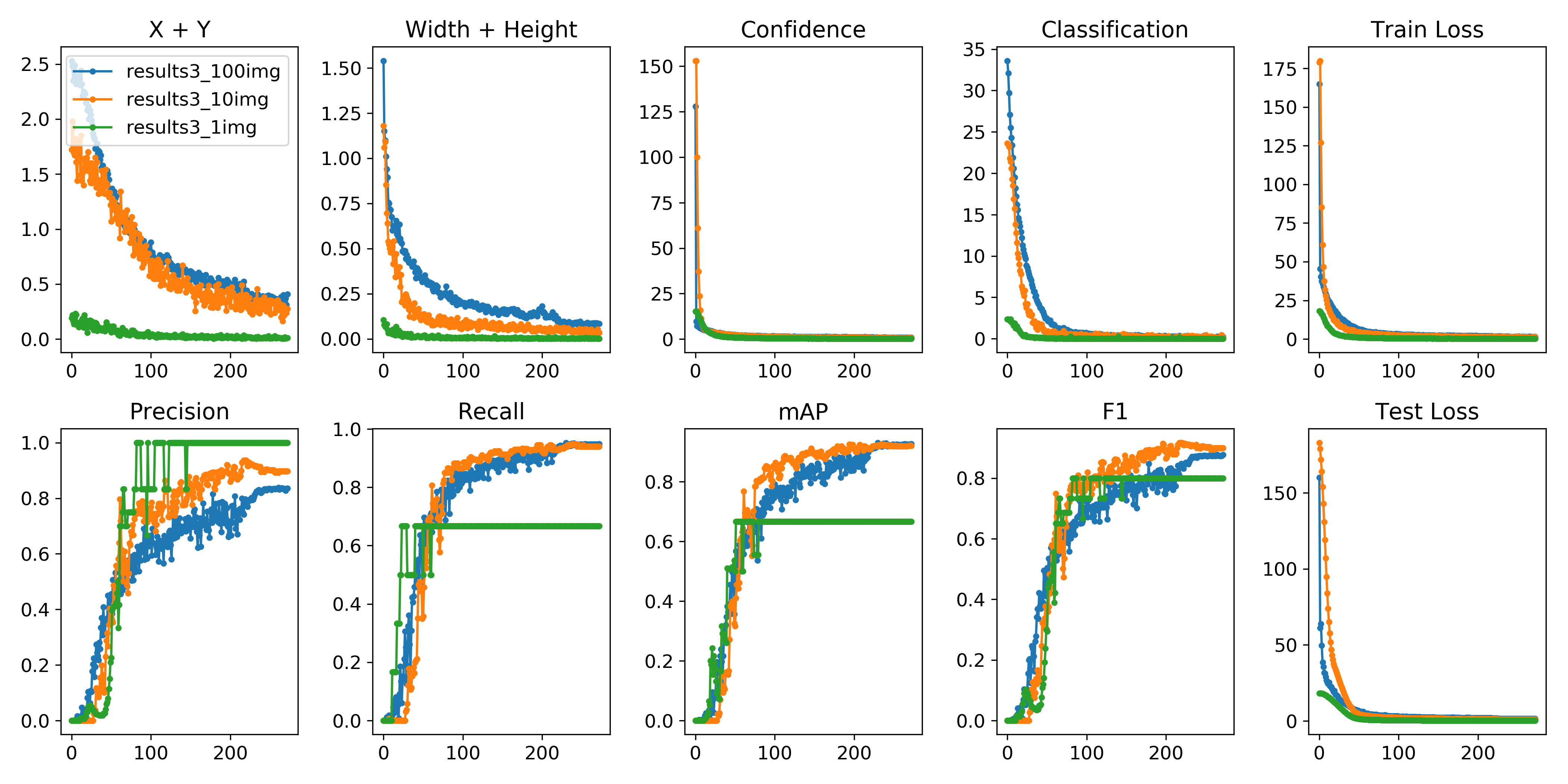
如果你看到这里了,恭喜你,你可以避开以上略显复杂的数据处理。我们提供了一套代码,集成了以上脚本,只需要你有jpg图片和对应的xml文件,就可以直接生成符合要求的数据集,然后按照要求修改一些代码即可。
代码地址:https://github.com/pprp/voc2007_for_yolo_torch
请按照readme中进行处理就可以得到数据集。
后记:这套代码一直由一个外国的团队进行维护,也添加了很多新的trick。目前已获得了3.3k个star,1k fork。不仅如此,其团队会经常回复issue,目前也有接近1k的issue。只要处理过一遍数据,就会了解到这个库的亮点,非常容易配置,不需要进行编译等操作,易用性极强。再加上提供的配套数据处理代码,在短短10多分钟就可以配置好。(✪ω✪)
这是这个系列第二篇内容,之后我们将对yolov3进行代码级别的学习,也会学习一下这个库提供的新的特性,比如说超参数进化,权重采样机制、loss计算、Giou处理等。希望各位多多关注。
参考内容:
官方代码:https://github.com/ultralytics/yolov3
官方讲解:https://github.com/ultralytics/yolov3/wiki/Train-Custom-Data