


OpenOCR makes it simple to host your own OCR REST API.
The heavy lifting OCR work is handled by Tesseract OCR.
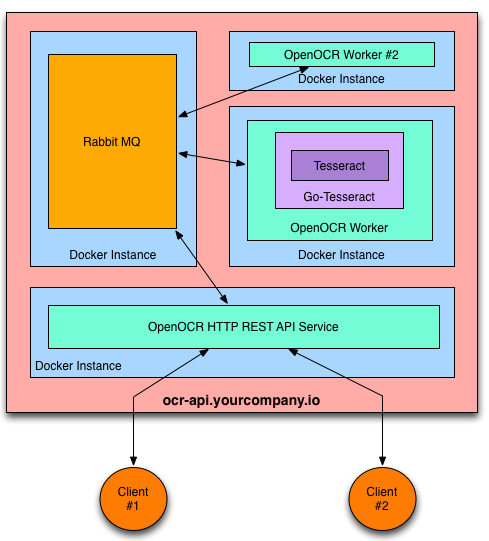
Docker is used to containerize the various components of the service.
{kind=link}
- Scalable message passing architecture via RabbitMQ.
- Platform independence via Docker containers.
- Supports 31 languages in addition to English
- Ability to use an image pre-processing chain. An example using Stroke Width Transform is provided.
- Pass arguments to Tesseract such as character whitelist and page segment mode.
- REST API docs
- A Go REST client is available.
OpenOCR can easily run on any PAAS that supports Docker containers. Here are the instructions for a few that have already been tested:
If your preferred PAAS isn't listed, please open a Github issue to request instructions.
OpenOCR can be launched on anything that supports Docker, such as Ubuntu 14.04.
Here's how to install it from scratch and verify that it's working correctly.
See Installing Docker on Ubuntu instructions.
$ ifconfig
eth0 Link encap:Ethernet HWaddr 08:00:27:43:40:c7
inet addr:10.0.2.15 Bcast:10.0.2.255 Mask:255.255.255.0
...
The ip address 10.0.2.15 will be used as the RABBITMQ_HOST env variable below.
Here's how to launch the docker images needed for OpenOCR.
$ curl -O https://raw.githubusercontent.com/tleyden/open-ocr/master/launcher/launcher.sh
$ export RABBITMQ_HOST=10.0.2.15 RABBITMQ_PASS=supersecret2 HTTP_PORT=8080
$ chmod +x launcher.sh
$ ./launcher.sh
This will start three docker instances:
You are now ready to decode images → text via your REST API.
- Install docker
- Install docker-compose
- Checkout OpenOCR repository or at least copy all files and subdirectories from OpenOCR
docker-composedirectory - cd docker-compose directory
- run
docker-compose upto see the log in console ordocker-compose up -dto run containers as daemons
Docker Compose will start four docker instances
Request
$ curl -X POST -H "Content-Type: application/json" -d '{"img_url":"http://bit.ly/ocrimage","engine":"tesseract"}' http://10.0.2.15:$HTTP_PORT/ocr
Response
It will return the decoded text for the test image:
< HTTP/1.1 200 OK
< Date: Tue, 13 May 2014 16:18:50 GMT
< Content-Length: 283
< Content-Type: text/plain; charset=utf-8
<
You can create local variables for the pipelines within the template by
prefixing the variable name with a “$" sign. Variable names have to be
composed of alphanumeric characters and the underscore. In the example
below I have used a few variations that work for variable names.
The REST API also supports:
- Uploading the image content via
multipart/related, rather than passing an image URL. (example client code provided in the Go REST client) - Tesseract config vars (eg, equivalent of -c arguments when using Tesseract via the command line) and Page Seg Mode
- Ability to use an image pre-processing chain, eg Stroke Width Transform.
- Non-English languages
See the REST API docs and the Go REST client for details.
The supplied docs/upload-local-file.sh provides an example of how to upload a local file using curl with multipart/related encoding of the json and image data:
- usage:
docs/upload-local-file.sh <urlendpoint> <file> [mimetype] - download the example ocr image
wget http://bit.ly/ocrimage - example:
docs/upload-local-file.sh http://10.0.2.15:$HTTP_PORT/ocr-file-upload ocrimage
- Follow @OpenOCR on Twitter
- Checkout the Github issue tracker
OpenOCR is Open Source and available under the Apache 2 License.