Requests memory leak #4601
Comments
|
Please provide us with the output of If that is unavailable on your version of Requests please provide some basic information about your system (Python version, operating system, etc). |
|
@sigmavirus24 Done |
|
Hey @Munroc, a couple quick questions about your threading implementation since it’s not included in the pseudo code.
We’ve had hints of memory leaks around sessions for a while now, but I’m not sure we’ve found a smoking gun or truly confirmed impact. |
|
@nateprewitt Hello, yes im creating a new session for every thread. The thread pool is 30. I have tryied with 2 - 200 threads and memory leaks anyway. Im not using a tool, i just did this changes to the function: |
|
@Munroc if we have the full code, then I think it would be easier to isolate the actual cause. But based on the code gist that was provided, I think it is very hard to conclude that there is a memory leak. As you have mentioned, if you However, let's say that you were using threads and |
|
@leoszn I think in your specific example, you're closing only the last Could you try daemonizing them using |
|
Do I need to run |
|
Ook, I was kicked from the new topic to this one, so let me join yours. I'm running Telegram bot and noticed the free memory degradation when running bot for a long time. Firstly, I suspect my code; then I suspect bot and finally I came to requests. :) Expected Resultlen(gc.get_objects()) should give the same result on every loop iteration Actual ResultThe value of len(gc.get_objects()) increases on every loop iteration. Reproduction StepsSystem InformationThe same behaviour I had on Python 3.5.3 on Windows10. |
# ..
for i in urls:
p = Process(target=main, args=(i,))
p.daemon = True # before `.start`
p.start()
# ..As a minor note, you can still Otherwise, you can store the # ..
processes = [
Process(target=main, args=(i,))
for i in urls
]
# start the process activity. |
The reason of this behaviour was found in "requests" cache mechanism. It works incorrect (suspected): it adds a cache record to every call to Telegram API URL (instead of caching it once). But it does not lead to the memory leak, because cache size is limited to 20 and cache is resetting after reaching this limit and the growing number of objects will be decreased back to initial value. |
|
Similar issue. Requests eats memory when running in thread. Code to reproduce here: import gc
from concurrent.futures import ThreadPoolExecutor, as_completed
import requests
from memory_profiler import profile
def run_thread_request(sess, run):
response = sess.get('https://www.google.com')
return
@profile
def main():
sess = requests.session()
with ThreadPoolExecutor(max_workers=1) as executor:
print('Starting!')
tasks = {executor.submit(run_thread_request, sess, run):
run for run in range(50)}
for _ in as_completed(tasks):
pass
print('Done!')
return
@profile
def calling():
main()
gc.collect()
return
if __name__ == '__main__':
calling()In the code given above I pass a session object around, but if I replace it with just running Output is: And Pipfile looks like this: |
|
FWIW I am also experiencing a similar memory leak as @jotunskij here is more info |
|
I also do have same issue where using requests.get with threading actually eats up the memory by around 0.1 - 0.9 per requests and it is not "clearing" itself after the requests but saves it. |
|
Same here, any work around? |
|
Edit Having the same issue. I have a simple script that spawns a thread, this thread calls a function that runs a while loop, this loop queries an API to check a status value and then sleeps for 10 seconds and then the loop will run again until the script is stopped. When using the But if I remove the I've watched this over a two hour period in both cases and when using Python 3.7.4 and requests 2.22.0 |
|
It seems Requests is still in beta stage having memory leaks like that. Come on, guys, patch this up! 😉👍 |
|
Any update on this? Simple POST request with a file upload also creates the similar issue of the memory leak. |
|
Same for me... leakage while on threadpool execution is on Windows python38 too. |
|
Same for me |
|
Here is my memory leaking issue, anyone can help ? https://stackoverflow.com/questions/59746125/memory-keep-growing-when-using-mutil-thread-download-file |
|
Call First I make 4 test cases:
Pseudo code: def run(url):
session = requests.session()
response = session.get(url)
while True:
for url in urls: # about 5k urls of public websites
# execute in thread pool, size=10
thread_pool.submit(run, url)
# in another thread, record memory usage every secondsMemory usage graph(y-axis: MB, x-axis: time), requests use lots of memory and memory increase very fast, while aiohttp memory usage is stable:
Then I add def run(url):
session = requests.session()
response = session.get(url)
session.close() # close session !!Memory usage significant decreased, but memory usage still increase over time:
Finally I add def run(url):
session = requests.session()
response = session.get(url)
session.close() # close session !!
response.close() # close response !!Memory usage decreased again, and not increase over time:
Compare aiohttp and requests shows memory leak is not caused by ssl, it's caused by connection resources not closed. Useful scripts: class MemoryReporter:
def __init__(self, name):
self.name = name
self.file = open(f'memoryleak/memory_{name}.txt', 'w')
self.thread = None
def _get_memory(self):
return psutil.Process().memory_info().rss
def main(self):
while True:
t = time.time()
v = self._get_memory()
self.file.write(f'{t},{v}\n')
self.file.flush()
time.sleep(1)
def start(self):
self.thread = Thread(target=self.main, name=self.name, daemon=True)
self.thread.start()
def plot_memory(name):
filepath = 'memoryleak/memory_{}.txt'.format(name)
df_mem = pd.read_csv(filepath, index_col=0, names=['t', 'v'])
df_mem.index = pd.to_datetime(df_mem.index, unit='s')
df_mem.v = df_mem.v / 1024 / 1024
df_mem.plot(figsize=(16, 8))System Information: |
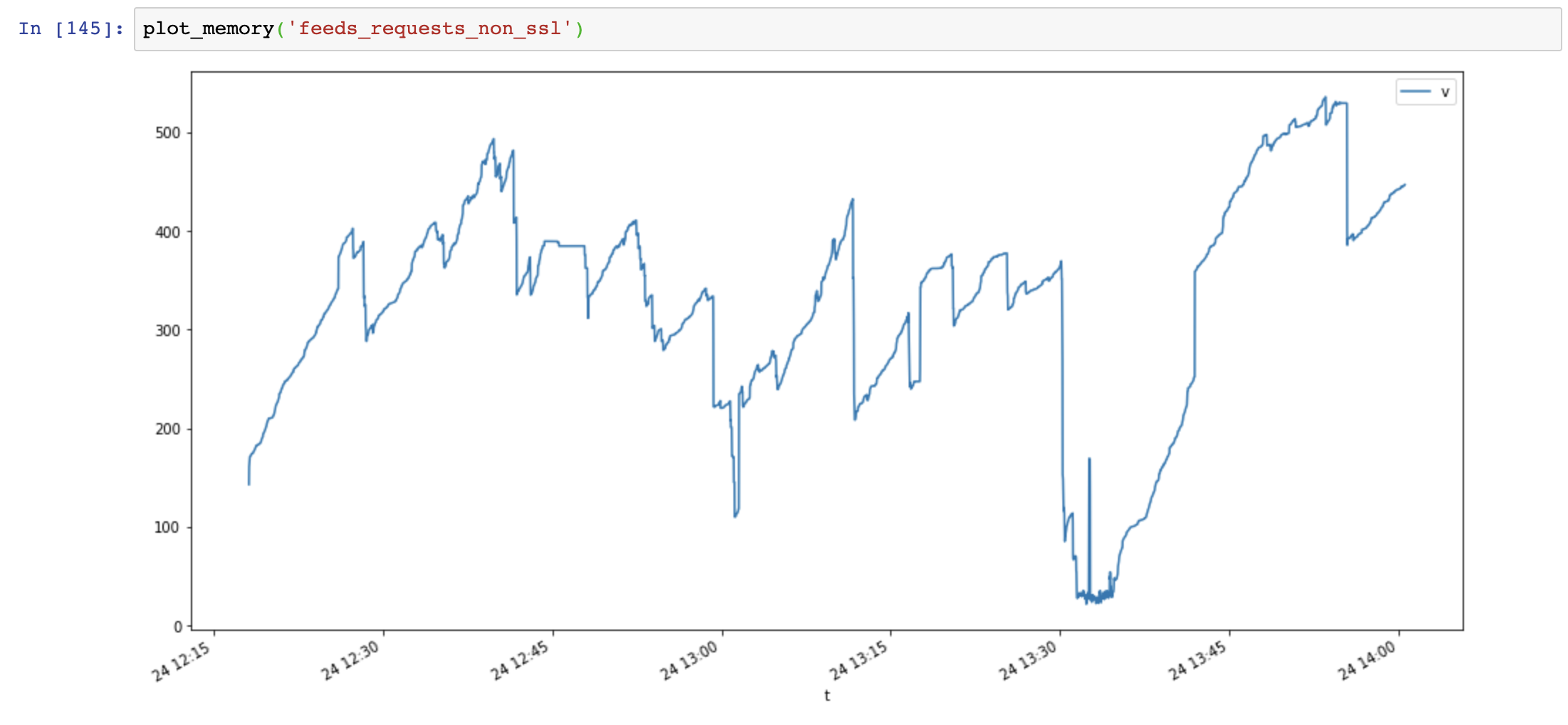





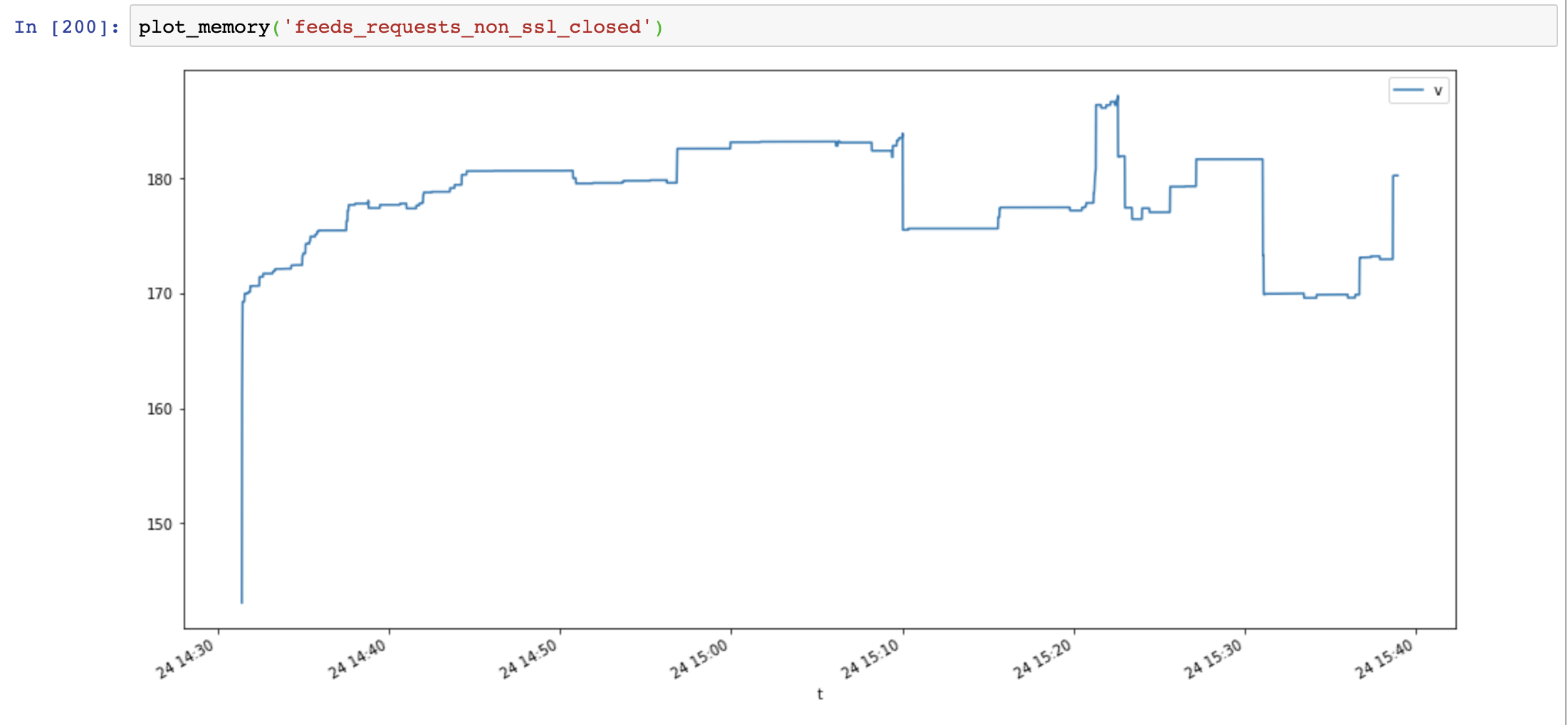

|
SSL leak problem is packaged OpenSSL <= 3.7.4 on Windows and OSX, its not releasing the memory from the context properly https://github.com/VeNoMouS/cloudscraper/issues/143#issuecomment-613092377 |
|
I have the same problem. It appears only when I use |
|
Same happens with requests 2.27.1 and urllib3 1.26.13 |
Summary.
Expected Result
Program running normally
Actual Result
Program consuming all ram till stops working
Reproduction Steps
Pseudocode:
System Information
The text was updated successfully, but these errors were encountered: