Better row unification error messages #4421
Conversation
|
Thanks for taking a crack at this! My general objection to changing error messages from to is the following: are lines A, C, D, or E ever the thing a user needs to look at? If not, the better change would be If so, then this change is not an improvement; it's just moving the confusion around. Some users get directed to the important part of the error for them, and other users get misdirected away from the important part of the error for them. In this specific instance, consider the following fragment: f :: forall r. Identity { foo :: Int | r } -> Int
f (Identity v) = v.foo
x :: Identity { foo :: String, bar :: Int }
x = Identity { foo: "hi", bar: 5 }
y :: Int
y = f xThe error currently produced says: IIUC, your PR would make this which makes the hint less helpful, as there's nothing wrong with |
|
Thanks for the feedback @rhendric! :D I agree it's not the most elegant solution. I also dislike the visual clutter this causes. But I don't agree that the information isn't helpful or moves the issue. The authors intent of this code, is unclear. It could be that the doStuff :: { a :: Int, b :: Int, c :: Int, d :: Int, e :: Int, f :: Int, h :: Int, j :: Int } -> Int
doStuff { a, b, c, d, e, f, g } = 1When i look at this code, I think it looks decently right. On my first skim I would not immediately notice the error. Gives this error: The difference in the fields is clearly given. I've had to manually match these fields where there are upwards of 70 rows and 1 row missing. This very simple tool trivializes the entire task of spotting the difference in the label names. Compare this error to: And it would already save me as a program writer brain power and thinking. Thinking that should go into the code I'm writing. I definately understand the visual clutter point. We've discussed that earlier. I think there's more we can to do to remove the clutter. I for one is for removing the entire part. But I think the compiler error messages are in a form of local optimum. They Some other ideas of getting forwards:
It might be that we should put up goals for what we want the errors to be. But |
|
My point is that for every example you come up with where this change helps the user find the problem, I can come up with an example where this same change makes it harder for the user to find the problem. That's not a global improvement. That's, at best, throwing some users under the bus to make other, hopefully more plentiful users happier—and I'm not yet convinced that the majority of cases are on your side. You don't have to solve this problem perfectly in order to make progress on it. You just have to do no harm in the process. For example, just looking at these errors: it seems likely that we could make more progress on unification, matching up the |
|
I don't know the inns and outs of the type checker perfectly. But reading @MonoidMusician s comment:
I figured that is very hard to unify more things in the type checker. This lead me to not investigate those solutions. I'm not sure it would be possible. I don't know if it's possible to get better error messages without "doing harm", much less so in increments. (relevant XKCD) I believe adding more information is doing the least harm. It sounds a lot like you want a complete revolution of the error messages or for them to be left alone. Something that unfortunately won't come out of making low hanging fruit changes in places where users are complaining. My reasoning went something like this:
The goal was to be as un-intrusive as possible with We could add another section to the error saying which labels differ there, if any. Is that a better solution? |
The thing being highlighted as difficult in that comment is telling the difference between a missing label that's needed or an extraneous label being provided. Simply proceeding with unification to eliminate more unknowns shouldn't run up against any intractable problems, though it might not resolve everything.
That's not as relevant as you think it is. I'm not talking about ‘breaking workflows’; we've done plenty of major releases where we've changed quite a lot about how users' workflows work, and when we're working towards a better world that is a decision we're comfortable making. That isn't this. We're talking about an error message that, conceptually, is saying, ‘Hey user, you might have problem A or you might have problem B.’ You're proposing adding information that biases the user toward looking at problem A. That disadvantages the users who have problem B. That's not a better world to be worked toward, unless you're myopically focused on the users with problem A.
No idea where you're getting that but that's definitely not what I want. A complete revolution is neither necessary nor desirable here. Leaving things alone is tolerable but not ideal either. I'm glad you're stepping up to work on the problem; I want things to improve, and I want to help you contribute! Working on the problem, however, involves considering the full space of cases that might trigger this error message, and making sure that in improving parts of the space you aren't making the message less helpful in others. It can be a difficult balancing act, and that's probably the biggest reason why nobody has fixed this yet.
In this case I'm not concerned about how noisy the indicator is. I'm concerned that the indicator in the error message makes it read as if that's the thing the user needs to look at to solve their problem. If you can figure out a way to format the diff so that it's obvious that you're just highlighting some rows that are different and that this isn't necessarily what the user needs to focus on, I could be okay with that. Maybe a second section would work. Just keep in mind that when open rows are involved, frequently extra or missing labels are totally fine and users—particularly beginners—shouldn't be misled by the error message into adding properties to their objects that they don't need, for example. For this reason, I'm not very optimistic about this approach, but you're welcome to take a stab at it and see if your creativity exceeds my imagination. Edit: Actually, maybe a side-by-side diff of rows (without any additional highlighting or indicators) would do the trick here? |
That's what I was thinking after reading through the above comments. The issue isn't the error per say but that jumping back and forth between really long rows makes it hard to see what is different about them. Consider the following examples of the same error shown in the comment, #4421 (comment): Side-by-SideDownsides:
Row comparisonDownsides:
|
|
Great to have more input! I've been thinking about this quite a bit for the last days. I you're both right that a more diff like approach is better. Particularly the second example that Jordan pointed out. I'm gonna look at implementing that. But I see some perils on the road to better error messages still. Switching to more of a "diff approach", might make it hard for new users to read the error message. Maybe some extra indentation could help, or maybe color coding the types differently might help. A more spread out type error might cause confusion of which row is part of which type. Spreading the type out might make it hard to see what belongs to what. Changing the shape of the error so drastically might also make it harder for people more used to reading the old errors. I'm gonna try to implement the more diff-like approach and we'll see how that turns out. I'm sure we're missing something there as well. :) |
This reverts commit 4975df0.
|
I've rewritten the errors to now display a diff. Should be easier to see typos. This is what it looks like one commit back: I made some alterations to what Jordan suggested, it is a different solution but maybe it has something in it that is relevant or interesting. But after the last change it's more inline with what Jordan wrote. I'm not entirely sure about the unified view of the error. It makes it kinda hard to know which type is which. I think the indentation helped a bit but it also added a bit of noise. I don't think either of these are perfect and I do prefer the formatting that Jordan suggested. And this solution is not complete. Tails aren't handled and the record/row open and closing brace aren't correct. Just to name a few. I'll let this sit for a few days and see what people feel about it before I do more work on it. |
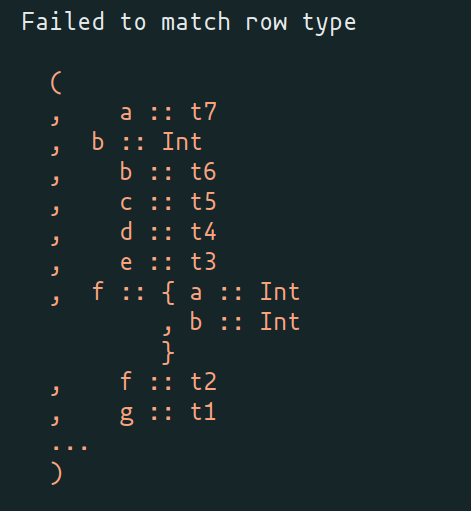

Could you clarify what those alterations were?
There's another issue open for better indicating what was the 'expected' type and what was the 'actual type'. But, I do think this error is overall better than what we currently have. Also, I think there should be a few golden tests:
You can look at Writing tests if you need clarification on how to do that. |
|
TL;DR: I'll gladly implement this more thoroughly. But is this likely to get merged?
I might be overly sceptic of the changes, but I'm not sure this change will go over well with everyone. Some of the things I've noted:
There are of course some pros to this new way of showing.
This doesn't convince me that we:
Maybe my list of cons is too long. I'm all for digging deeper. I'm personally almost at the point where I consider doing a survey in the Discord. I'd love to see changes and I'll happily do them, but I want them to be changes that are to the benefit of everyone. I'll add as many tests as we can think of, but is there value in me working more on this? |
|
Can't speak for Jordan, but in my opinion work on design is less likely to be wasted than work on tests at this stage. Though I still think the most straightforwardly beneficial approach would be allowing row unification to continue past the first mismatch, and then seeing whether work on changing error rendering is still needed. |
|
In fact, doing nothing more than changing purescript/src/Language/PureScript/TypeChecker/Unify.hs Lines 179 to 180 in df5fcff to the following: unifyTails r1' r2' =
throwError . errorMessage $ TypesDoNotUnify (rowFromList r1') (rowFromList r2')makes the error generated in #4421 (comment) become the following: I suspect that doesn't cover 100% of the cases you're concerned about, but I recommend investigating that sort of improvement first (you may need to make a few other similarly-sized tweaks in that area; there's a |
Hmm... those are all good points, and it further highlights why resolving issues like this are hard.
I agree with this. My comment above was more mentioning tests that should be added at some point / cases to consider when designing the final error. However, @rhendric is right in that writing tests shouldn't be done until this design is better flushed out. |
cd79ba0
to
a533829
Compare
|
I have now made the changes that @rhendric suggested. The tests noted a change in one place, and I would say it's equally good or an improvement. This change doesn't solve my entire problem, but it goes part of the way there. I would propose merging this change (I can make a new PR if that's easier) and then look into potential changes to error messages given the better unification. I also looked through all other |
|
At this point you need tests. What cases were you looking at that you wanted to see improvements on? In particular, did you have a case that didn't look good without the Also, are there any downsides to making this change? Can you explain what they are or why they don't exist? |
a533829
to
2849fe4
Compare
This reverts commit 7b4c4d6.
Changes to tests after typecheck changes
2849fe4
to
8f75585
Compare
8f75585
to
3cb3074
Compare
TL;DR: These changes improve the error messages somewhat. From how I understand the code - which is probably faulty - I see this as a safe change. Sending out other type information than the original types should not change the correctness of the compiler. The error messages I've seen, given all the unit tests in this code and from all programs I've run I've never found a "worse error message". That said, there are differences. Now the compiler exposes less type information displayed in certain errors. The more focused errors makes it easier for me to understand the type error at a glance, but someone else might prefer the verbosity. We should also consider Changing the returned error Changing the
Yes, see tests.
I'm well aware. I see this as a learning opportunity. Not every day you get to poke around in a compiler. Thanks for all the help, hope I haven't been too frustrating. <3 To finish this in a truly scientific manner, I still think more work needs to be done in this area. But it's hard to see these changes in isolation. So I'm not going to open another PR until #4421 and #4411 are merged. 🍡 |
|
Hm.... I would have expected the recent changelog entry edit to not trigger CI. Looks like #4502 didn't work...? Edit: seems like this behavior is expected and we'd have to move to |
|
Yeah, I would not have expected #4502 to do what you wanted but you guys merged it before I took a look and then I figured it wouldn't be worth a fuss. I don't think |
|
I think this could use some eyeballs belonging to someone who regularly bumps up against errors involving large rows, but pending their approval I'm happy with where we've landed. I don't think it's perfect but I think it's better in every way on the cases we've touched. |
|
Given that no one has responded in the past few days and that this was a highly-desired PR on the survey, there's three ways we could move forward:
What do you consider to still be imperfect about it? |
|
Probably not everyone who indicated interest in this PR on the survey is subscribed to it. We could maybe stir up some interest on Discourse. I think it's important for requests like this one to have at least one ‘customer’ verifying that the change meets the objective before it's merged; I apply this policy to things like ‘better error messages’ and ‘make go faster’, as opposed to ‘here is a bug where the documentation or common sense says one thing should happen but another thing happens instead’. If this is such an in-demand feature, finding one single user who has this problem and can build the compiler shouldn't be hard. And conversely, we don't need to rush it out if we can't.
I think there are some inconsistencies in what errors we present as rows versus records, and I think there are many more places where the expected/found distinction could be drawn but where the current code shrugs (in fact, I somewhat suspect that, given that we highlight a particular subexpression, we can always draw an expected/found distinction from the perspective of the highlighted subexpression, and the greatest barrier to doing so is that there are still places where highlighting is off because source spans aren't being applied in one or two spots). I'm pretty comfortable with all that being worked out later as needed, though. |
Would you mind typing up such a Discourse post then? Edit: Ryan's corresponding post is here: https://discourse.purescript.org/t/upcoming-changes-to-error-messages-for-large-records-rows/3696/1
Makes sense. Thanks for clarifying. |
There was a problem hiding this comment.
I had a look at the patch and it seems good!
I am approving this so that we can get it merged and test it more widely through the prerelease - we could keep this waiting and ask people to try it out, but I think that's asking for unrealistic conditions: I do certainly see terrible row mismatch errors, but not at predictable times, and when that happens I'm usually in the middle of something complex so I want to just go past it rather than compile a custom build of the compiler.
While it might not be perfect, the improvements to error messages seem good enough to warrant getting this mainlined and iterating on it.
|
Based on the current state of the Discourse thread, I actually think this PR misses the mark wide. The test cases we were focused on all along are not relevant to what seems to be the primary way these error messages come up in the wild—namely, through Please let's have a little more time to consider whether anything in this PR is relevant to handling that use case before we run ahead and merge it. |
I somewhat disagree with this interpretation of people's responses so far. While |
I guess it depends on your definition of ‘issue’. I would take the perspective that an issue is something that a user encounters that makes their day worse. I think this PR makes some changes, I think it makes some of our error messages better, but I have yet to see any evidence that it resolves any issues. All we have is evidence that when users poke the thing we changed, it responds with the error messages we designed for that type of poking. We could have the best error messages imaginable for some scenario that users never naturally encounter in the wild, and it wouldn't improve things at all. In exchange for that no-benefit, the PR adds several confusingly-named functions (we did our best, but we should also acknowledge that where we ended up isn't great) to the project and possibly impacts the performance of the type checker. It removes three constructors from our Most PRs are written by people who are invested in the particular issue that they resolve. This PR, at this point, is mostly written by you and me; and speaking for myself, I have never had problems with the error messages I get related to rows. But I also don't use The |
|
Huge reply from the author on discourse https://discourse.purescript.org/t/upcoming-changes-to-error-messages-for-large-records-rows/3696/19 says he's available on discord but rarely checks github issues or discourse. Lots of input on this problem too, which I definitely second. |
@rhendric I would quote the rest of what you said above, but that's a lot of text 😆. Fair points! From my perspective, this does make things better, but I don't think I can provide evidence proving that, at least not enough to convince you. I'm also finding it difficult to come up with a logical response to your arguments above. However, part of the difficulty of this issue is coming across reproducible errors that can be collected into a publicly-visible place that would inform us on how to best improve errors. There's a lot of upfront cost to do that. Given the responses on the Discourse thread, what do you propose is the way to move forward? Given both my initial response and @f-f's response to merge this, it may be worthwhile to close this PR and refocus on the original problem. So long as the branch isn't deleted, none of the work done so far is lost. |
It matters to me what hat you're wearing when you say this makes things better. If it's your user hat—if you encounter the previous iteration of these messages in your own PureScript work and would prefer the new ones—that's all the convincing I need. If it's your maintainer hat—if you think the code is better with these changes than without them, independent of what users experience—then I disagree but there's no reason for my opinion to be weighed above yours; let's keep talking and see if we can agree or get a third maintainer's opinion. If it's your business analyst hat—if you have reason to believe users would want to see these changes merged—that's the tougher hill to climb, unless you can produce the users who want this. Otherwise it's your imaginary users against my imaginary users and that's hard to discuss logically, as you say.
From a process-management perspective, we could close; maybe it'd be better to mark as draft, since I don't think we're giving up on the concept, but I don't feel strongly either way. From a getting-things-done perspective, whichever one of us gets cycles first should make a test case that mimics the |
Description of the change
Related to #4413, and part of a potential solution.
The idea was to show which record labels are different. Sometimes, you have typos or a bunch of fields that mostly unify. This could help with that.
I'm hesitant to make more work on this unless there's interest. So let me know if this is a change people want to see. I know this or something that's feature adjacent.
This simple program:
Now compiles with the error:

This is a toy example. But it makes it very clear that the
barlabel is what is causing the unification to fail.I think it's an improvement which changes the errors for the better.
🔥 Roast me! 🔥
Checklist: