We implement RCNN algorithm for object detection from an Images.
- R-CNN was proposed by Ross Girshick et al. in 2014 to deal with the problem of efficient object localization in object detection.
- It changed the object detection field fundamentally. By leveraging selective search, CNN and SVM.
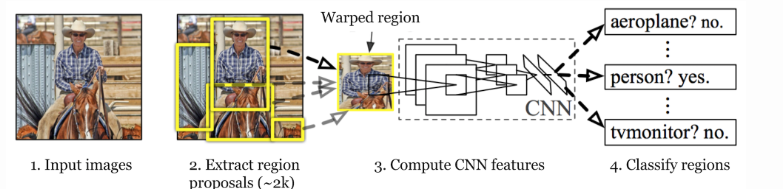
- First of all selective search algorithm is applied to images and give us around 2000 region which might containing an object.
- Wraped region is feed into CNN model(in paper, Alexnet is used) which return (1,4096) size feature vector.
- This region feed into SVM classifier which give object class and confidence score.
- Than after we have to train one bounding box regression model for generating tight rectangle boxes for object in images.
It Seems easy Right? Now i will explain what things i did for train my own custom RCNN model.
I used my Crop and Weed detection dataset which i collected and labeled it myself. I also uploaded it in kaggle. This datset contains total 1300 images. I used 1000 images for training and 300 images for testing
-
First I apply selective search algorithm and generated ~2000 region per images.
-
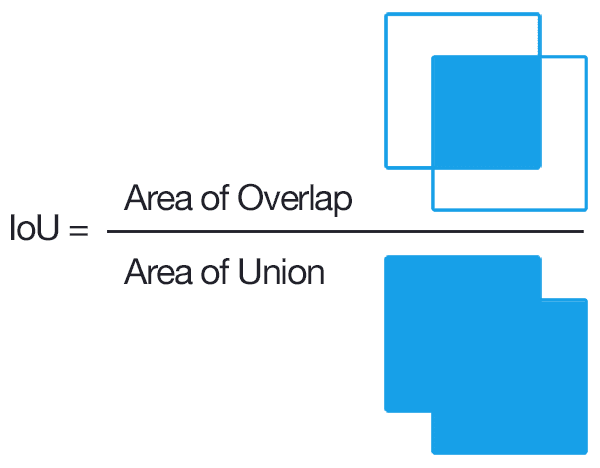
Than I compare generated region with ground truth labels by mean of Intersection over union(iou).
-
Which ever region has iou>0.5 is saved as positive example(it might object) and region which has iou<0.2 is saved as negative example.
-
In RCNN paper it had take iou<0.3 for negative example but by this i get worst result for my dataset so i changed it to 0.2.
-
NOTE: I didn't included all negative examples which has iou<0.2, i only selected random images and double of number of postive examples.check this code for better understanding.
-
I saved just cordinnates of bounding boxes by using data_processing_part_1.ipynb.
-
Saved all images using rcnn-data-preprocessing-part-2 notebook on kaggle.
-
RCNN Model training is divided in three parts
- CNN finetuning
- CNN + SVM training
- Bounding Box regression
- I finetuned VGG16 model with my generated region proposals. But in paper they used Alexnet.
- Input size of model is 224x224x3 and Output 3 classes (Crop, Weed and Background).
- Model perform very well and give 95.88% accuracy on test images.
- I used kaggle platform to train my models for take advantge of free GPU.
- Finetuning training notebook is here.
- I removed last two fully connected layers from finetuned model and used CNN model as feature extractor.
- CNN model will returns (1,4096) size feature vector.
- Than I trained SVM model using feature vectors.
- SVM improves overall prediction of model.
- SVM training is here on kaggle.
- I didn't train bounding box regression model yet. but i will upload it whenever i train it.
-
I did't train BB regressor but i still perform detection and result are look nicer. take look in notebook.







