WIFA量化组,2019年春。
依据多因子模型,尝试对沪深300指数构建纯因子组合。
如果一个投资组合,对模型中某因子暴露度为1,对其他风险因子暴露度为0,则称该组合为这个因子的纯因子组合。
——《多因子模型系列报告之一:模型理论随想和纯因子组合构建》
因子数据分为风格因子和风险因子。
其中风格因子又分为大类因子和细分类因子,最终的风格因子会由细分类因子合成。
风格因子共选取以下7个大类中的19个因子:
- VALUE:EPS_TTM/P、BPS_LR/P、CFPS_TTM/P、SP_TTM/P
- GROWTH:NetProfit_SQ_YOY、Sales_SQ_YOY、ROE_SQ_YOY
- PROFIT:ROE_TTM、ROA_TTM
- QUALITY:Debt2Asset、AssetTurnover、InvTurnover
- MOMENTUM:Ret1M、Ret3M、Ret6M
- VOLATILITY:RealizedVol_3M、RealizedVol_6M
- LIQUIDITY:Turnover_ave_1M、Turnover_ave_3M
风险因子选取以下2个大类中的2个因子:
- INDUSTRY:中信一级行业
- SIZE:Ln_MarketValue
由于数据限制和平台选择,最终确定的因子和最初选取的因子比较如下:
| 最初选取因子 | 最终确定因子 | 因子解释 |
|---|---|---|
| EPS_TTM/P | PE_TTM | 市盈率 |
| BPS_LR/P | PB_LYR | 市净率 |
| CFPS_TTM/P | PCF_NCF_TTM | 市现率(现金净流量) |
| SP_TTM/P | PS_TTM | 市销率 |
| NetProfit_SQ_YOY | YOYPROFIT | 净利润同比增长率 |
| Sales_SQ_YOY | YOY_OR | 营业收入同比增长率 |
| ROE_SQ_YOY | YOYROE | 净资产收益率同比增长率 |
| ROE_TTM | ROE_TTM2 | 净资产收益率 |
| ROA_TTM | ROA_TTM2 | 总资产净利率 |
| Debt2Asset | DEBTTOASSETS | 资产负债率 |
| AssetTurnover | ASSETSTURN | 总资产周转率 |
| InvTurnover | INVTURN | 存货周转率 |
| Ret1M | PCT_CHG | 涨跌幅 |
| Ret3M | PCT_CHG | 涨跌幅 |
| Ret6M | PCT_CHG | 涨跌幅 |
| RealizedVol_3M | UNDERLYINGHISVOL_90D | 90日历史波动率 |
| RealizedVol_6M | UNDERLYINGHISVOL_90D | 90日历史波动率 |
| Turnover_ave_1M | TECH_TURNOVERRATE20 | 20日平均换手率 |
| Turnover_ave_3M | TECH_TURNOVERRATE60 | 60日平均换手率 |
| 中信一级行业列表 | INDUSTRY_SW | 申万行业名称 |
| Ln_MarketValue | VAL_LNMV | 对数市值 |
(注:
- Ret1M, Ret3M, Ret6M 皆由 PCT_CHG合成;
- RealizedVol_3M, RealizedVol_6M 皆由 UNDERLYINGHISVOL_90D代替。)
数据来源为万德金融数据库,通过WindPy API获取。
其中“最终确定因子”列即为因子的万德指标字段名。
(数据保存在“H3 Data” ("HS300 Data" 的缩写) 文件夹中,格式为CSV,直接用全小写的万德指标名命名。 即 "<万德指标名>.csv",如 "pe_ttm.csv")
获取的原始数据储存在"H3 Data/Raw Data"文件夹里。
数据格式如下:
| 行/列 | 股票代号(000001.SZ) |
|---|---|
| 交易日期(YYYYMMDD) | 相应因子暴露 |
对因子数据进行处理。
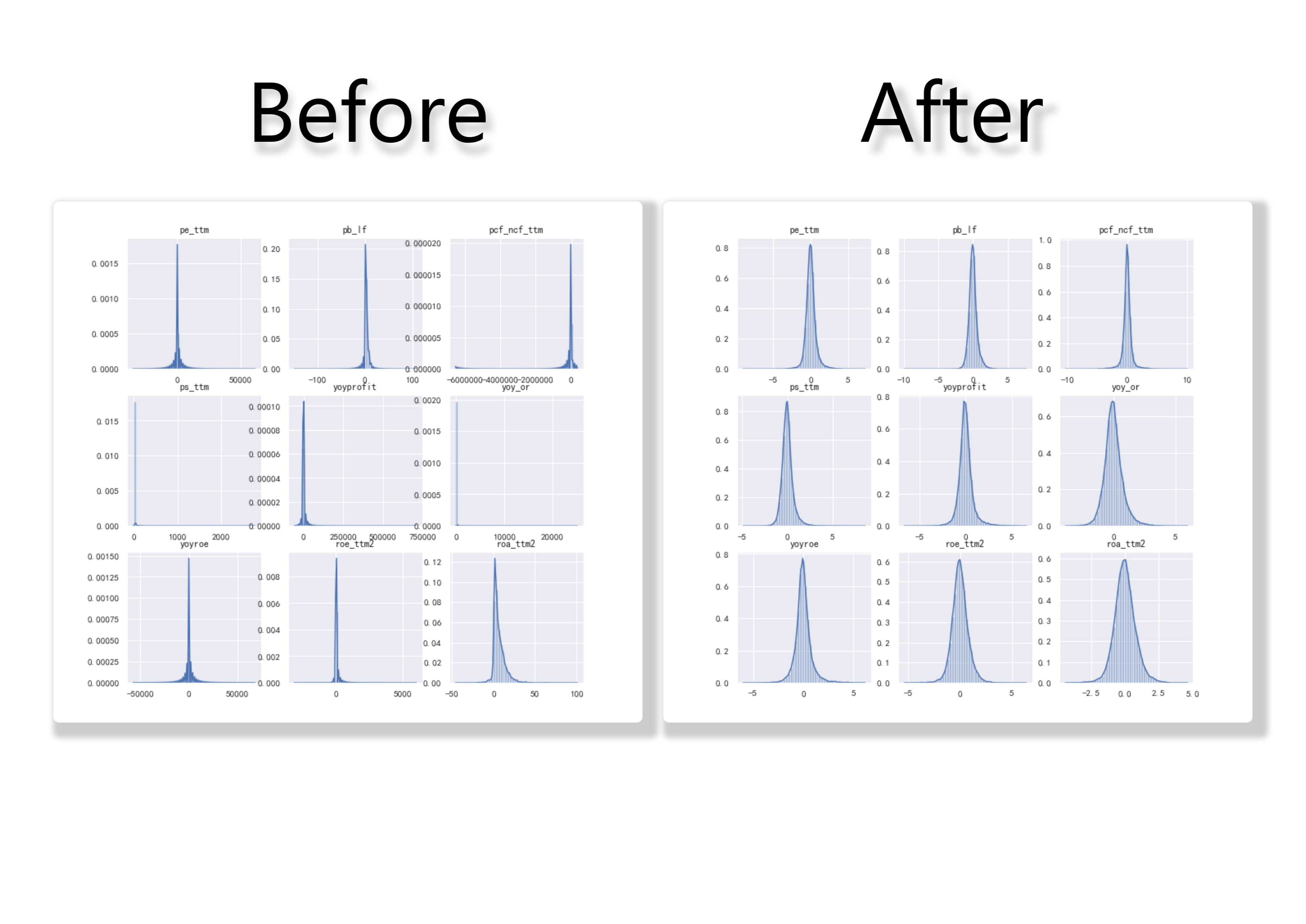
如图为作为例子选取的沪深300的9个因子暴露数据在2005~2018年的分布统计图。👇
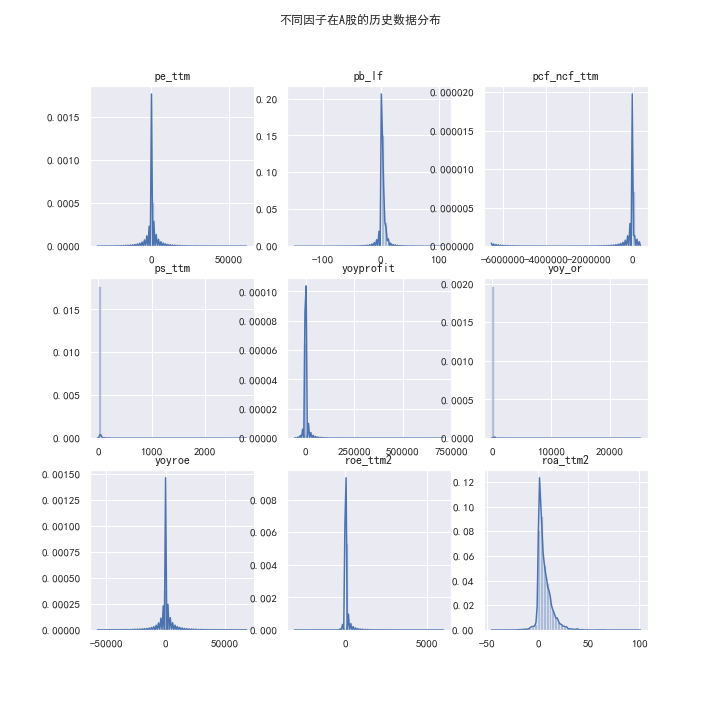
从图中可以看出绝大多数因子都存在极差过大、分布不均的现象。 而这样的数据会影响到统计分析的结果,所以需要对数据进行处理。
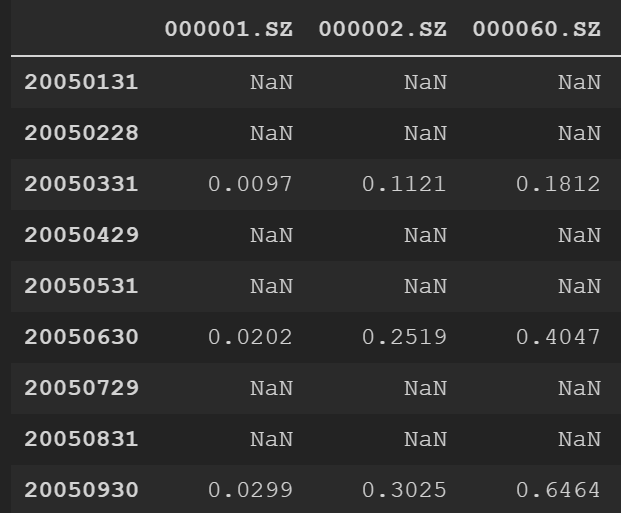
由于万德输出的当季度财务数据只在报告期有数据,而在该季度的其他月份没有数据,所以针对这个现象采用“向前填充”来填补缺失值。
data.fillna(method = 'ffill', inplace = True)填补前:
填补后:
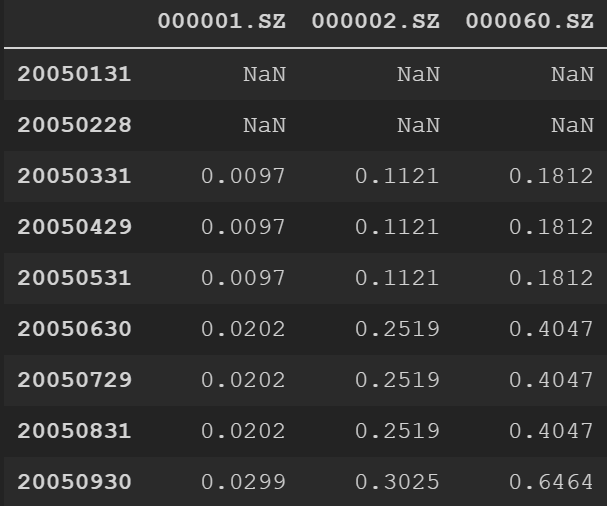
去极值的方法采用调整因子值中的离群值至指定阈值的上下限,从而减小离群值和极值对统计的偏差。
离群值的阈值上下限定义的方法主要有三种:
- MAD法
- 3σ法
- 百分位法
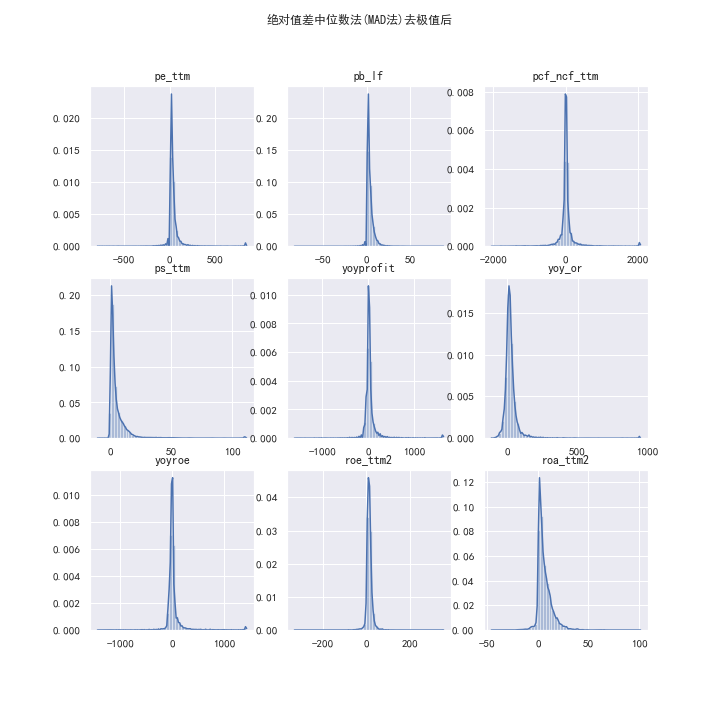
取因子的中位数,加减每个因子与该中位数的绝对偏差值的中位数乘上给定参数(此处经过调参设定默认为60倍)得到上下阈值。
经过MAD法去极值后的因子数据概览如下:
取所有因子数据的标准差(即σ),偏离平均值给定参数(此处默认为三倍)标准差处设为上下阈值。
经过3σ法去极值后的因子数据概览如下:
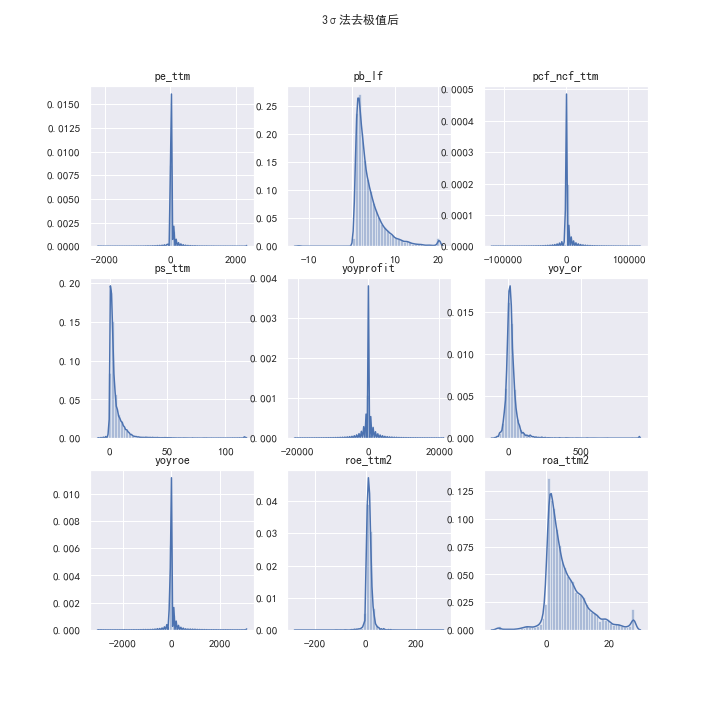
取给定百分位作为上下阈值。(此处经过调参设定为下限1.5%,上限98.5%分位点)
经过百分位法去极值后的因子数据概览如下:
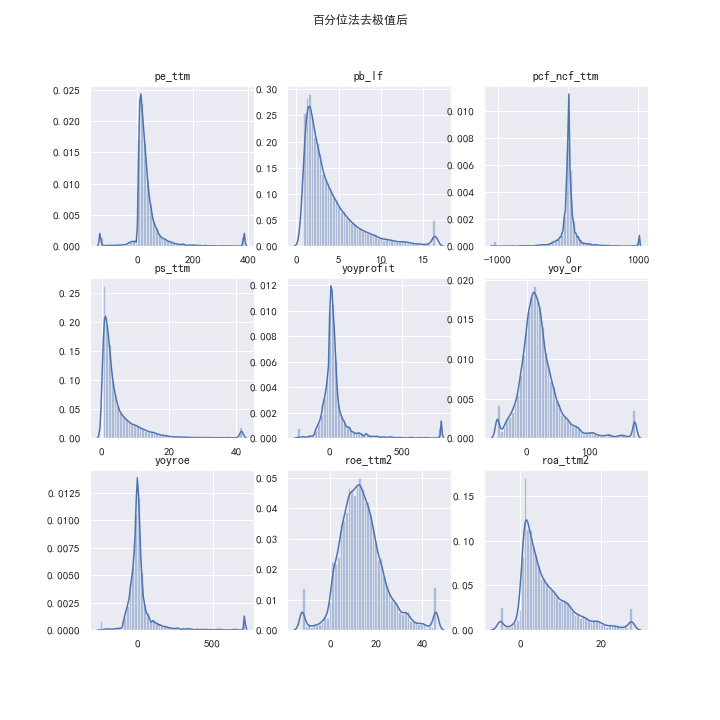
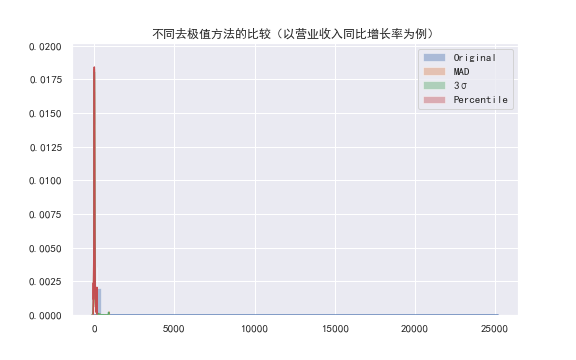
实际上,即使经过调参尽可能地使三种主流的去极值方法的结果互相接近,并不至于出现过于集中的阈值,仍然有可能出现非常显著不同的效果。
以营业收入同比增长率为例,将原始数据和三种去极值的方法处理后的因子数据放在同一张图里,由于值域相差太大,甚至根本无法从图中找到不同的方法对应的图表。(如下图:分别采用三种去极值方法处理后的每股现金流数据与其原始数据图👇)
究其原因,是其原始数据的集中度就非常高,以至于不同方法去极值计算出相差甚远的阈值。(如下图:全部A股样本期内营业收入同比增长率的密度分布图👇)
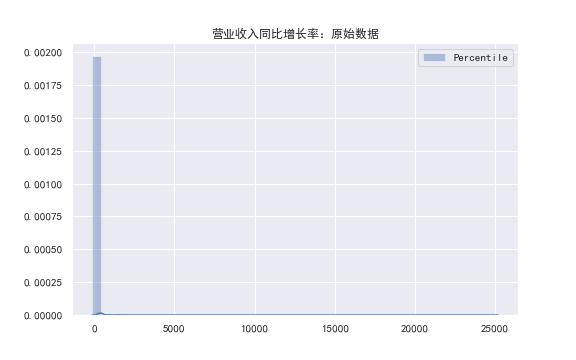
所以经过百分位去极值后,尽管值域缩小了近100倍,但仍然非常集中。
(如下图:营业收入同比增长率经过约束最严格的百分位去极值处理后的分布图👇)
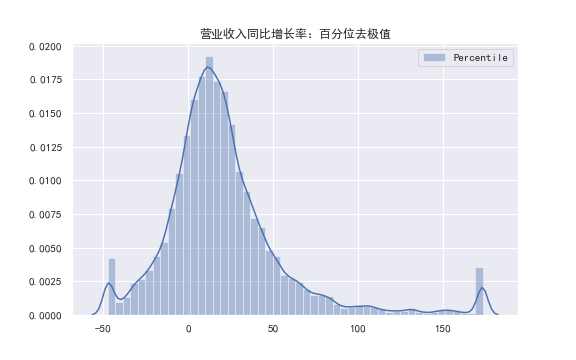
另外,这种离差过大的数据去极值的时候还会出现一个问题:造成阈值部分出现异常高的“虚假”数据,而这也是我们不愿意看到的。
注意图中 [-50, 150] 处异常的“突起”。👆
这是由于过多超出上下阈值的数据被迫调整为上下阈值,导致阈值处的数据分布特别密集。
但在大多数情况下(数据分布相对均匀时,此处以ROE为例),各种方法以及原始数据相差不大。(如下图:资产周转率数据的原始数据及分别经过三种去极值方法处理后的分布图👇)
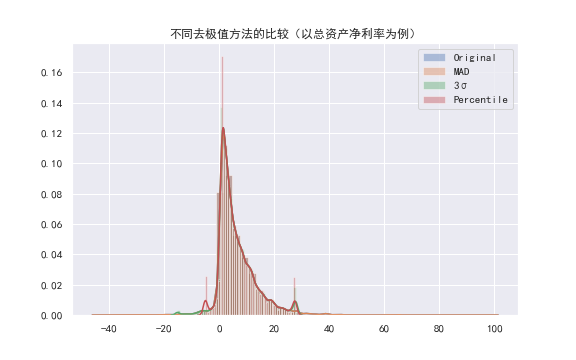
经过比较研究,我们最终选取阈值选取相对最为合理,较少阈值异常“突起”,同时保留较宽值域的参数值为60的MAD法进行去极值处理。
标准化处理数据的目的就是去除其量纲。
这样做可以使得:
- 数据更加集中
- 不同数据之间可以互相比较和进行回归等
主流的标准化的方法有两种:
| 标准化方法 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 对原始因子值标准化 | 减去均值后,除以标准差 | 保留更多信息 | 对数据分布有要求 |
| 对因子排序值标准化 | 因子排序值进行上述处理 | 适用性更广泛 | 非参数统计法 |
它们都能使得数据的:
- 均值为0
- 标准差为1
由于已经对数据进行去极值处理,我们最终选取对原始因子值进行标准化(z-score)的方法进行标准化。
经过
- 2.1填补缺失值
- 2.2去极值
- 2.3标准化
的数据处理后的数据保存在"H3 Data/Processed Data"文件夹里。
中性化的目的是剔除数据中多余的风险暴露。
根据某些因子(指标)选股的时候,由于某些因子之间具有较强的相关性,故时常会有我们不希望看到的“偏向”,导致投资组合不够分散。
中性化的主要做法就是通过回归得到一个与风险因子(行业因子、市值因子)线性无关的因子。如此一来,中性化处理后的因子与风险因子之间的相关性就严格为零。
不过这样做中性化并不一定总能彻底地剔除因子的多余信息。因为线性回归要求两个前提假设:
- 因子之间线性相关
- 残差正态独立同分布
而在因子数据中这两个假设都不一定成立。
(例如在2.2去极值步骤中密度过高的阈值就对数据的分布造成了破坏)
但直观的说,根据Brinson资产配置分析超额收益理论来看,如果投资组合中风险因子配置资产权重等于基准资产中其之权重,则做到了中性化。
此处简便起见,我们依然采用线性回归作为中性化的处理方法。
回归方式如下:
- 被解释变量:前述数据处理后的因子数据
- 解释变量:
- 市值因子
- 行业因子
最终回归方程的残差项即为中性化后新的因子暴露。
我们可以通过观察因子暴露度(或IC值)与行业的分布结果(或其相关度)来判断是否需要进行行业中性化。
沪深300股票指数中共包含17个行业(根据申万一级行业分类),分别统计沪深300指数中各行业四个指标的平均值,结果如下图所示👇。
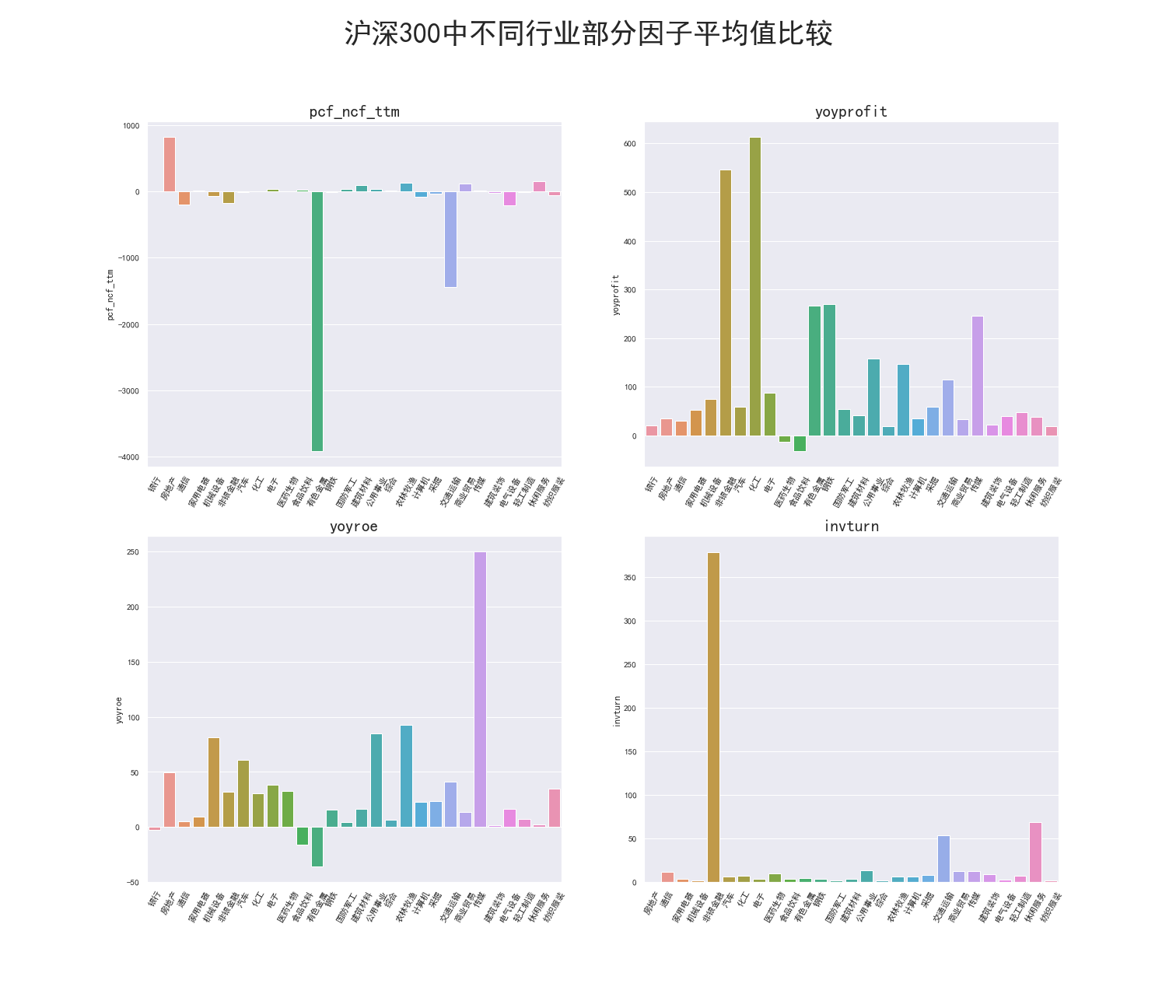
本例中选取的四个指标:
- 市现率
- 净利润同比增长率
- 净资产收益率同比增长率
- 存货周转率
从图中可以看到,不同行业的不同指标相差十倍、千倍乃至万倍都有。
有色金属行业的平均市现率是银行业的近负四十万倍。
那么,依据市现率因子选取出的股票必然对平均市现率高的行业有偏向,而我们希望投资组合中的行业尽可能分散,以避免特定行业的风险,故我们希望对行业进行中性化。
实际进行行业中性化的时候,行业因子作为被解释变量以哑变量(即指示变量,为一只包含0和1的矩阵)的形式进行回归。
(如下图,为选取四个因子指标进行行业中性化前后的结果,以展示行业中性化的一般结果👇,可以看出行业中性化之后,数据的分布更均匀、更接近均值)

与行业中性化类似,我们通过观察因子暴露数据在不同市值区间的分布判断是否需要对市值进行中性化,以避免特定市值区间的风险。
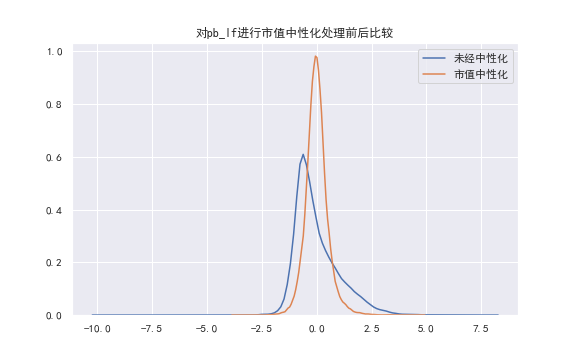
实际进行市值中性化的时候,直接使用对数市值 ("val_lnmv") 进行回归。
对市值进行中性化也有与行业中性化类似的效果。(如下图为对"pb_lf"因子进行市值中性化的结果👇)
同样是"pb_lf"因子,同时对市值和行业进行中性化👇,效果也是相近的。
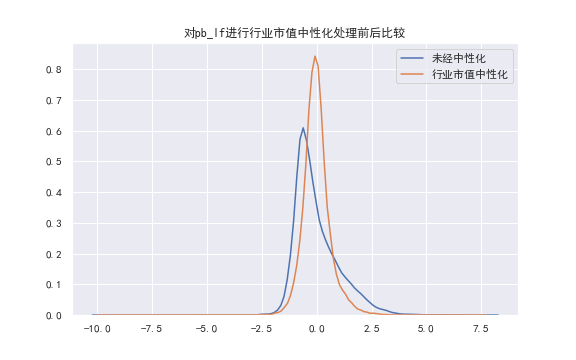
经过中性化处理后的数据保存在"H3 Data/Neutralized Data"文件夹里。
最终经过所有因子数据处理步骤之后,原来的因子数据分布图变为了这样。
(经过所有数据处理步骤后的因子数据密度分布图一览👇)
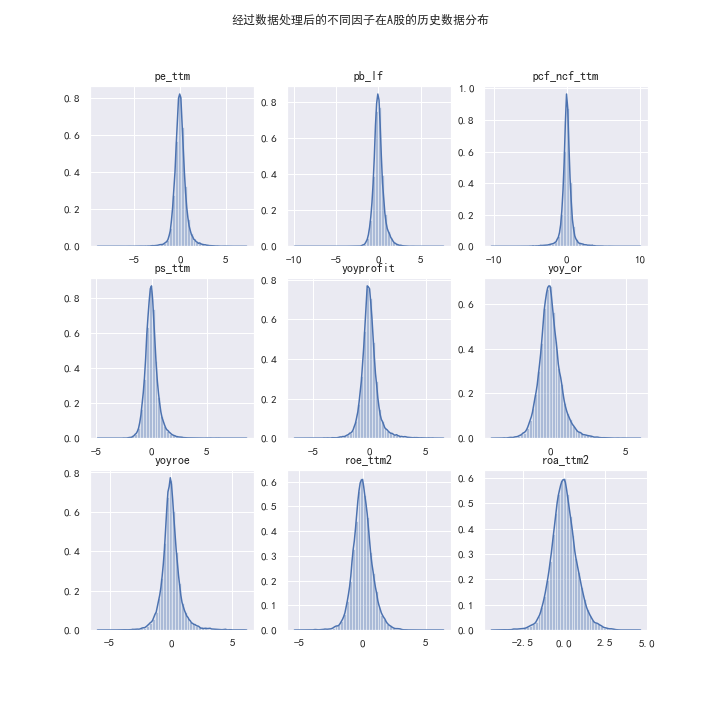
可以看出数据经过处理后分布变得更加接近标准正态分布了一些。
前面两个步骤已经把风格因子的细分类因子数据经过数据处理并保存了下来, 这一步把细分类因子合成为大类因子。使得最终合成后只剩下:
- VALUE
- GROWTH
- PROFIT
- QUALITY
- VOLATILITY
- MOMENTUM
- LIQUIDITY
这七个因子,我们的目标就是构建这七个因子的纯因子组合。
虽然我们已经选出了在主观上与收益率有显著关系的因子池,但因子彼此之间(尤其是同一大类下所属的因子)有可能存在很强的相关性。如果不做处理,投资组合会在同种因子类型上暴露过多风险,由此导致的多重共线性会导致多元线性回归的结果偏差。
换言之,合成后的大类因子之间不应该具有明显相关性。
从这一步开始为方便提取数据,将数据从"pandas.DataFrame" 转换为"pandas.PanelData"。
数据格式为:
- index: stock codes
- factor names
可以用以下方法提取特定时间的所有因子的所有股票数据:
Large_factor.major_xs("20050131")
我们通过(动态或静态的)IC_IR加权方法来合成大类因子,根据收益-风险原则,考虑因子的有效性和稳定性。
- IC(信息系数):每个时间截点上因子在各个股票暴露度和股票下期收益的相关系数(Spearman或Pearson)。意味着因子暴露度与未来收益率之间的相关关系。
- IR(信息比率):残差收益率的年化预测值与其年化波动率(此处取年化标准差)之比。衡量因子每承担一单位风险能创造的超额收益
大类因子合成部分的数据保存位置:
- 动态权重:在"H3 Data/Large Factor Dynamic Data"文件夹里
- 静态权重:在"H3 Data/Large Factor Static Data"文件夹里
通过股票收益率数据,对合成好的大类因子数据(因子暴露)进行回归,利用回归系数(因子收益),采取一定方式来预测下一期的因子收益,从而进行股票收益率预测。
由于核心在于因子收益的预测,此处简便起见直接采用过去一年月度因子收益的均值,作为下一期因子收益的预测值,最后来构建股票收益预测模型。
进行多元线性回归。(具体数学公式在 HS300.ipynb 的 Jupyter Notebook里。)
为解决异方差性,使用了WLS加权最小二乘法进行回归。 每次回归的R2如下,可以看出模型的解释性较好。
| R2 | 静态权重 | 动态权重 |
|---|---|---|
| 平均值 | 29.52% | 29.61% |
| 最大值 | 50.72% | 50.87% |
| 最小值 | 9.24% | 11.03% |
由多元线性回归可以得到所有因子的历史收益率序列,使用历史数据估计T+1期因子预期收益率的方法有很多种。
此处采取历史均值法,N=12。(即采取前12个月的因子历史收益率均值作为T+1期因子的预期收益率)
根据因子预期收益估计值与T期因子载荷矩阵得到股票预期收益:
即可计算出T+1期个股的预期收益率。
由4.1~4.3得到的预期收益模型,我们可以计算出300个股票T+1期(2019年2月)的预期收益率.
同时,通过万德数据库获取300个股票T+1期的真实收益率。
回归预测报告:
| 指标 | 数值 |
|---|---|
| MSE值(均方差) | 0.067 |
| RMSE值(均方根) | 0.259. |
预测值与真实值对比如图:
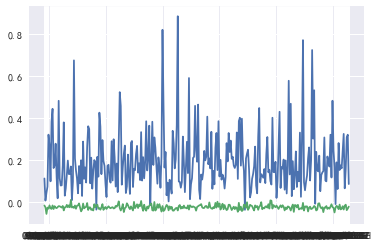
预测值与真实值之比如图:

我们发现问题在于使用历史因子收益平均值作为预测值时,正负值进行平均后估计值接近0,如图为最近一月的因子收益与最近12月因子收益平均值对比图:
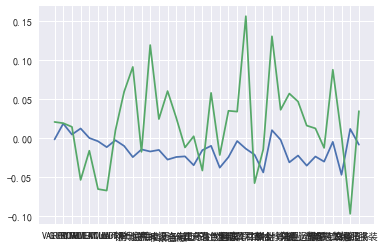
因此我们采取单独的预测模型对其进行预测,此处采用ARIMA模型。
如图为前三个因子的趋势图以及ACF和PACF
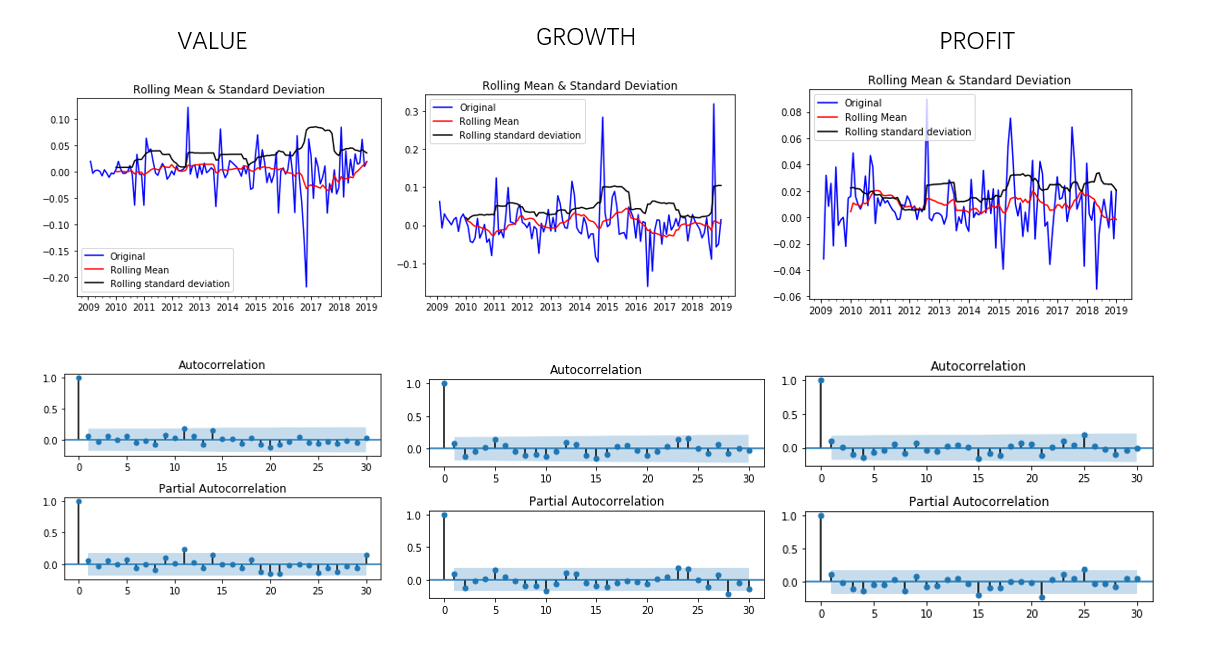
各因子ADF test如下表
| Test Statistic | p-value | #Lags Used | Number of Observations Used | Critical Value(1%) | Critical Value(10%) | Critical Value(5%) | 是否平稳 | |
|---|---|---|---|---|---|---|---|---|
| VALUE | -9.874532 | 3.91429E-17 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | Y |
| GROWTH | -10.18399 | 6.58177E-18 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | N |
| PROFIT | -9.972023 | 2.2274E-17 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | Y |
| QUALITY | -10.18471 | 6.55473E-18 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | N |
| MOMENTUM | -9.692955 | 1.12372E-16 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | Y |
| VOLATILITY | -10.63178 | 5.1921E-19 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | N |
| LIQUIDITY | -8.65308 | 5.05345E-14 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | Y |
| market | -2.415998 | 0.137272 | 8 | 111 | -3.490683 | -2.580857 | -2.887952 | N |
| 银行 | -10.04036 | 1.5019E-17 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | N |
| 房地产 | -9.56141 | 2.42033E-16 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | Y |
| 通信 | -9.681588 | 1.20062E-16 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | Y |
| 家用电器 | -3.265178 | 0.016509 | 6 | 113 | -3.48959 | -2.580604 | -2.887477 | Y |
| 机械设备 | -9.06844 | 4.36792E-15 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | Y |
| 非银金融 | -9.079048 | 4.10344E-15 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | Y |
| 汽车 | -8.724267 | 3.32121E-14 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | Y |
| 化工 | -8.639735 | 5.46713E-14 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | Y |
| 电子 | -6.65975 | 4.88094E-09 | 1 | 118 | -3.487022 | -2.580009 | -2.886363 | Y |
| 医药生物 | -9.549655 | 2.5924E-16 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | Y |
| 食品饮料 | -10.96015 | 8.36622E-20 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | N |
| 有色金属 | -8.636485 | 5.57291E-14 | 1 | 118 | -3.487022 | -2.580009 | -2.886363 | Y |
| 钢铁 | -5.012623 | 0.000021 | 2 | 117 | -3.487517 | -2.580124 | -2.886578 | Y |
| 国防军工 | -9.011876 | 6.09479E-15 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | Y |
| 建筑材料 | -10.55267 | 8.10001E-19 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | N |
| 公用事业 | -3.181954 | 0.021053 | 3 | 116 | -3.488022 | -2.580241 | -2.886797 | N |
| 综合 | -9.271716 | 1.32136E-15 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | Y |
| 农林牧渔 | -5.929155 | 2.40355E-07 | 2 | 117 | -3.487517 | -2.580124 | -2.886578 | Y |
| 计算机 | -10.10187 | 1.05428E-17 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | N |
| 采掘 | -9.692568 | 1.12625E-16 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | Y |
| 交通运输 | -8.889708 | 1.25211E-14 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | Y |
| 商业贸易 | -5.925572 | 2.44833E-07 | 1 | 118 | -3.487022 | -2.580009 | -2.886363 | Y |
| 传媒 | -1.820965 | 0.370104 | 7 | 112 | -3.490131 | -2.58073 | -2.887712 | N |
| 建筑装饰 | -8.592502 | 7.22246E-14 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | Y |
| 电气设备 | -9.520093 | 3.08141E-16 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | Y |
| 轻工制造 | -9.731649 | 8.97137E-17 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | Y |
| 休闲服务 | -10.94894 | 8.89899E-20 | 0 | 119 | -3.486535 | -2.579896 | -2.886151 | N |
| 纺织服装 | -3.741765 | 0.003563 | 3 | 116 | -3.488022 | -2.580241 | -2.886797 | Y |
本身平稳的因子有:
- VALUE
- PROFIT
- MOMENTUM
- LIQUIDITY
- 行业因子:
- 房地产
- 通信
- 家用电器
- 机械设备
- 非银金融
- 汽车
- 化工
- 电子
- 医药生物
- 有色金属
- 钢铁
- 国防军工
- 综合
- 农林牧渔
- 采掘
- 交通运输
- 商业贸易
- 建筑装饰
- 电气设备
- 轻工制造
- 纺织服装
将本身不平稳的因子通过不同滞后期的差方项ADF检验进行平稳化。
根据ACF和PACF找出ARIMA(p,d,q)的参数,对每个因子进行预测。
- 优化目标:组合预期收益率最大化
- 约束条件:
- 对目标纯因子不做约束
- 对非目标纯因子偏离要求不超过 0.03
- 风险因子行业和市值
- 偏离不超过 0.03
根据上一个步骤构造的收益预测模型,以最大化预期收益率为优化目标,构建纯因子模型。
我们通过对因子进行约束来构造对某一个因子具有高暴露度,而对其他因子保持中性的投资组合。
我们通过动态规划的方式优化模型以在约束条件内达到目标,最终构建沪深300指数纯因子组合。
- 《The Barra US Equity Model (USE4)》
- 《华泰多因子模型系列初探,华泰证券》
- 《单因子有效性检验——多因子选股模型的基石,东方证券》
- 《低特质波动,高超额收益(因子选股系列之二),东方证券》
- 《因子研究专题二——估值因子解析,民生证券》