Welcome to the Human Active Navigation Dataset (HumANav), a codebase for photorealistic simulations of humans in indoor office environments! We are a team of researchers from UC Berkeley and Google Brain.
This codebase is a part of our work in "Visual Navigation Among Humans with Optimal Control as a Supervisor". In this work we show that HumANav enables zero-shot transfer of learning based navigation algorithms directly from simulation to reality. We hope that HumANav can be a useful tool for the broader visual navigation, computer vision, and robotics communities.
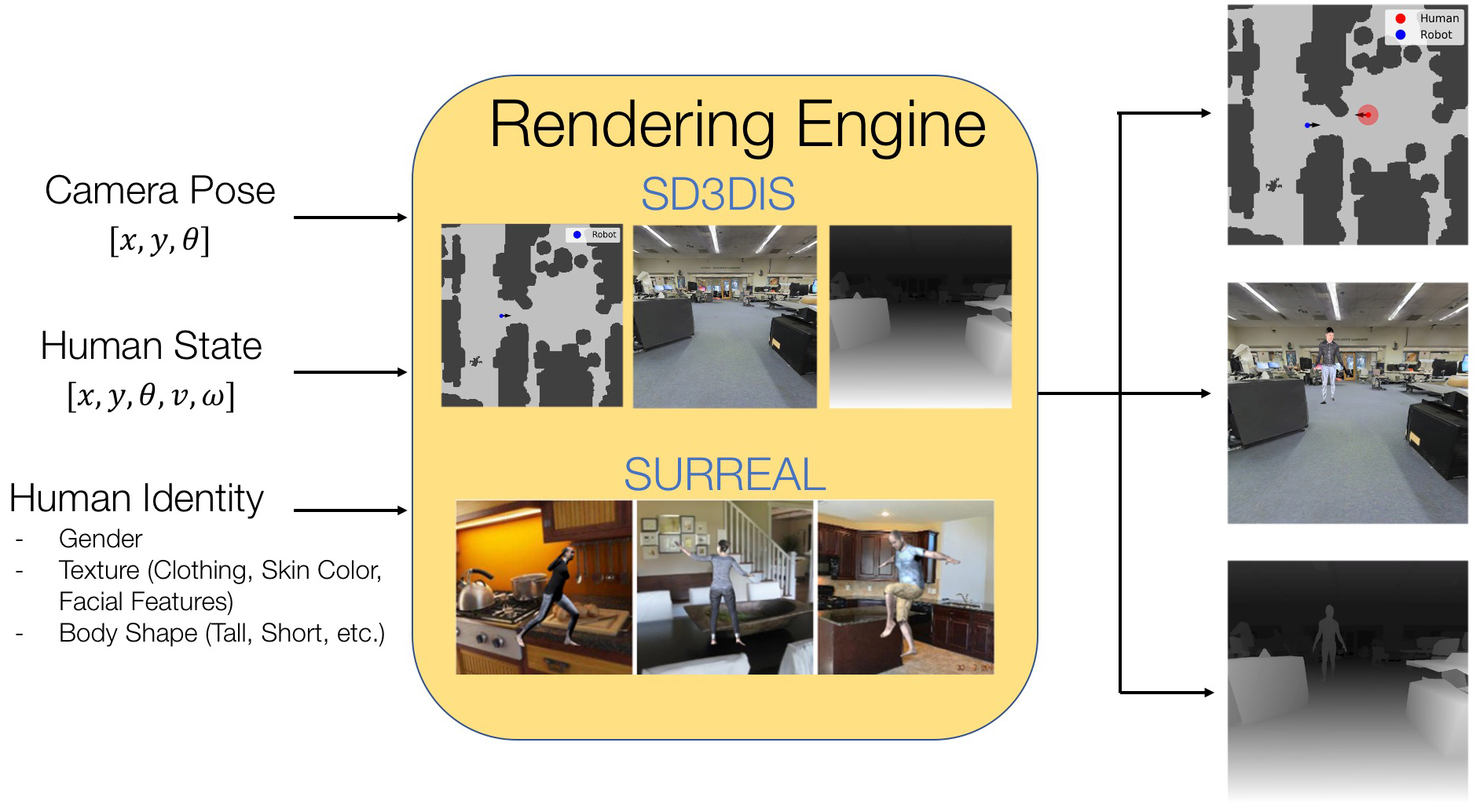
More information & a live demo of the HumANav Dataset is available on the project website.
Follow the instructions in surreal/README.md.
Follow the instructions in sd3dis/README.md
In ./humanav/renderer_params.py change the following line
def get_path_to_humanav():
return '/PATH/TO/HumANav'
Note: HumANav is independent of the actual indoor office environment and human meshes used. In this work we use human meshes exported from the SURREAL dataset and scans of indoor office environments from the S3DIS dataset. However, if you would like to use other meshes, please download and configure them yourself and update the parameters in renderer_params.py to point to your data installation.
# Install Anaconda
wget https://repo.anaconda.com/archive/Anaconda3-2019.07-Linux-x86_64.sh
bash Anaconda3-2019.07-Linux-x86_64.sh
# Install gcc and g++ if you don't already have them
sudo apt-get install gcc
sudo apt-get install g++
conda env create -f environment.yml
conda activate humanav
In the terminal run the following commands.
1. /PATH/TO/HumANav/humanav
2. bash patches/apply_patches_3.sh
If the script fails there are instructions in apply_patches_3.sh describing how to manually apply the patch.
In the terminal run:
sudo apt-get install libassimp-dev
Follow the steps below to install HumANav as a pip package, so it can be easily integrated with any other codebase.
cd /PATH/TO/HumANav
pip install -e .
To get you started we've included examples.py, which contains 2 code examples for rendering different image modalities (topview, RGB, Depth) from HumANav.
cd /PATH/TO/HumANav/examples
PYOPENGL_PLATFORM=egl PYTHONPATH='.' python examples.py
The output of examples.py is example1.png and example2.png, both of which are expected to match the image below. If the images match, you have successfully installed & configured HumANav!

If you find the HumANav dataset useful in your research please cite:
@article{tolani2020visual,
title={Visual Navigation Among Humans with Optimal Control as a Supervisor},
author={Tolani, Varun and Bansal, Somil and Faust, Aleksandra and Tomlin, Claire},
journal={arXiv preprint arXiv:2003.09354},
year={2020}
}