![]()
This is a project from a team of 5 students from the ESILV school in France in partnership with the MIT Media Lab. The goal of the project is to replace the way the wildlife on the Tidmarsh site is currently recognized. More informations about Tidmarch can be found at http://www.livingobservatory.org/ and http://tidmarsh.media.mit.edu/
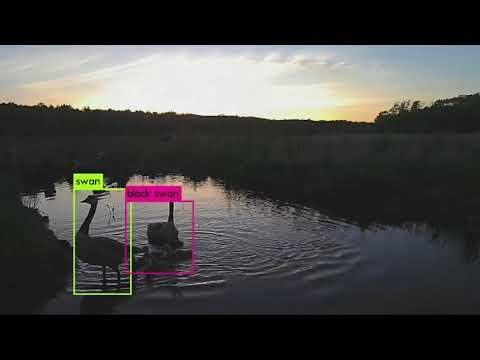
This project's aim is to create an environement to process real time video and video from folders (archives videos) to be processed The processing part consists in identifying accuraltely the spicies in the given frame The resultst are then sent to a web server for streaming or to the chain API
Click on the image below
- Python 3.5+
- Numpy
- PIL
- django for webserver
- ffmpeg and ffprobe
- matplotlib for debugging (showing images)
- CUDA and cudNN are optional but will trigger errors in Darknet Job installation if not present
For python dependencies, run
./install_python_packages.sh
For ffmpeg
sudo apt-get install ffmpeg
If you plan on using the processing part you will have to install the darknet job, see below
Run the installation script from project root:
sudo ./install_boxer_job.sh
NOTE: If CUDA or CUDNN are not installed properly you will notice errors when building. To use CPU computation (hence no cuda or cudnn) use the following header in
src/supervisor/jobs/boxer/MakefileDarknet
before running the install_boxer_job.sh script
Change header to:
GPU=0
CUDNN=0
OPENCV=0
NNPACK=0
ARM_NEON=0
OPENMP=1
DEBUG=0
this will disable gpu usage
- Clone this repo
- Install dependencies (check Dependencies Installation)
- Run
scripts/start_web_server.shto start the django web server - Run
scripts/start_supervisor.shto start the supervisor on this pc - Run
scripts/start_local.shto start the local instance (everything on this pc) Tid'Zam video is now running
Config files are in src/supervisor/cfg
To Tid'Zam main config file for a local deployment is alone_cluster.json
The default is:
{
"units": [
{
"name":"mypc",
"address":"127.0.0.1"
}
],
"workers": {
"mypc": [
{
"workername" : "django",
"port": 25224,
"jobname": "djangotransfer",
"jobdata":"none",
"debuglevel": 3
},
{
"workername" : "dl",
"port": 25225,
"jobname": "boxer.darknet.boxerjob",
"jobdata":"none",
"debuglevel": 3,
"output": ["django"]
},
{
"workername" : "streamer",
"port": 25223,
"jobname": "multistreamer",
"debuglevel": 3,
"jobdata":"cfg/multi_stream_test.json",
"outputmethod":"distribute",
"output": ["dl"]
}
]
}
}
The config file is divided in two main parts
First, you may set the units hosting a supervisor Here, we only use the local unit but of course more can be added
"units": [
{
"name":"mypc",
"address":"127.0.0.1"
}
],
Then, for each unit, you may define the worker that will be running on it
Each worker is assigned a single job,
The jobs are defined in src/supervisor/jobs
- djangotransfer: transfers a input image data to the django server given in input
- multistreamer: reads from several video sources at the same time and outputs an image cycling through each source
- boxer/darknet/boxerjob: given an input image, returns a list of animals in the image
- identityjob: outputs its input
- printjob: prints a string representation of in put to the console
- showjob: shows a given inout image using matplotlib
- failsafejob: will raise an exception in its loop
A worker config chunk is as follows:
{
"workername" : The name of the worker,
"port": The port of this worker,
"jobname": The job running on this worker,
"debuglevel": The requested loglevel,
"jobdata":The setup data, depends of the job,
"outputmethod":"distribute" or "duplicate",
"output": [list of output worker name]
}
A worker can either distribute or duplicate its output If distribute is used the output will go to the first available worker if duplicate is used the output will go to all of the listed output workers
{
"options": {
"default_img_rate":60,
"defaut_resolution":"800x600",
"max_streamers":5,
"video_extensions": ".mp4;.avi",
"realtime": 1
},
"stream": [
{
"name": "camera1",
"url":"http://fakepath.truc/pathtocamera1"
}
],
"folders": [
{
"name":"tidzam-video",
"path":"data",
"recursive":1
}
]
}
This is the multistreamer job configuration. The file path is given as jobdata to the multistreamer The frst part are the default options:
"options": {
"default_img_rate":default rate,
"defaut_resolution":default resolution set it to 'auto' to use the resolution from the input
"max_streamers":max number of streamers working at the same time
"video_extensions":Extensions to recognize videos when exploring folders
"realtime": Skip frames to keep real time video ?
},
Then you can set the streamer path, the streamers will be opened first at startup
{
"name": name of this stream,
"url":"http://fakepath.truc/pathtocamera1",
"resolution"; "auto" to keep the original resolution
"realtime": 1 to have a realtime stream
}
You can specifically define the resolution for each stream
Finally, you can give some folders you would like to analyse, Use the recursive tag to explore sub-folders and set realtime to 0 to miss 0 frames
{
"name":"tidzam-video",
"path":"/mnt/fakepath",
"realtime":0 to get each frame
"recursive": 1 to explore sub folders
}
- Fix logging level changing
- Use multiple GPU in darknet
- Write log to files
- Worker can be started with command line, without supervisor
- Multistreamer must support on the fly video changes
- Ensure frame order in djangotranfer
- Connect to Chain API