[libsleef] Add modified Payne Hanek argument reduction #197
Conversation
|
I haven't taken a benchmark, but it depends on how fast gather instructions are. On Skylake, the latency and throughput of a gather instruction is 20 and 4, so executing 4 gather instructions take (at least) 20 + 4 * 3 = 32 clocks, which is already pretty slow. The execution time should not matter in practice, since the old reduction algorithms are still enabled. I would say there is something wrong if someone is calling a trig function with a very large argument. The point is that when adopting SLEEF to some project, that person wants to feel safe to replace the existing calls to the standard math functions with SLEEF functions. |
But isn't this patch using gather instructions? If that's the case, it seems to be not a good idea given that they are slow.
I think that execution time is a very important constraint.
You are probably right, but penalizing those users that compute trigonometric functions on proper values with en extra vector test instruction doesn't seem fair.
I agree. But I think that we should provide them via separate functions, not merging them in the same function with that if statement on the "test all one" function (this would of course add another degree of freedom for the run-time system, if we ever come up with it). |
Payne-Henek algorithm is a slow algorithm, compared to Cody-Waite.
CPUs with out-of-order execution and branch prediction should have only small performance impact with this. We have to think the critical path to estimate the execution time, rather than simply summing up the execution time of all the instructions. Since the extra vector test instructions are not in the critical path, they don't affect the overall execution time so much. |
|
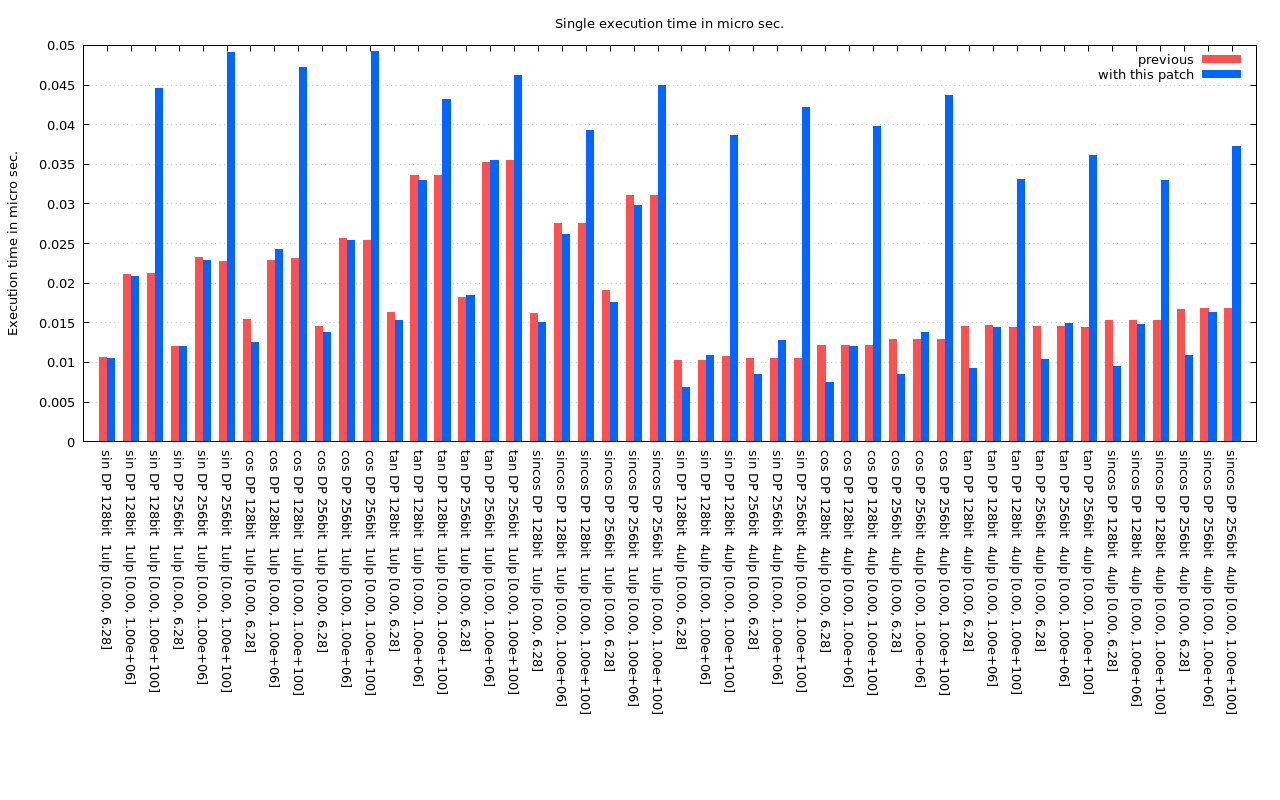
Here is the benchmark.
|

|
As a workaround of the bug in armclang, I changed the definition of INLINE macro and it does not insert always_inline attribute when SLEEF is compiled for SVE target. armclang still aggressively inlines functions, so I think this is not a problem. Please check the assembly output from the compiler. https://github.com/shibatch/sleef/wiki/197/sleefsimddp.s Testing for SVE target is now enabled. |
|
I moved the fixup code to the reduction part, and now most of the functions are slightly faster than before, if the argument is small. The graphs are updated. |
|
Hi @shibatch, a couple of questions before I dig into the code review:
|
Sure. I will post the results.
Reduction algorithms for trig functions is not easy, and there are basically two algorithms. Cody-Waite algorithm has been used since the first version of SLEEF, and Payne-Hanek is the one introduced in this PR. The versions used in SLEEF are both modified versions of these algorithms, but basically it is not easy to further improve the algorithms.
For the DP versions of the functions, there is actually almost no slowdown, since the that large input domain was not supported. For the 1 ulp SP version, the situation is same, and there is almost no slowdown. There is some slowdown in 3.5 ulp SP version of the functions, between 125 to 39000, but I don't know if people care about this. For the input domain less that 125, it should be a little faster than before.
For DP functions, the fastest algorithm is used up to 15, and the second algorithm is used up to 1e+9. For SP functions, the faster algorithm is used up to 125. The effect is not only __builtin_expect. It is a combination of __builtin_expect and moving fixup code to the slow reduction routine, and adjusting the polynomial for reduction.
They are a little slower than SVML for very large arguments. I will post the graph. |
|
These are comparison between SVML and SLEEF with this patch on Core i7-6700. These graphs are comparison on RK3399. |




* Benchmarking tool now compiles for aarch64
|
I put back the reduction routine for [125, 39000] range to 3.5 ulp SP functions. |
src/arch/helperavx.h
Outdated
| @@ -290,6 +290,12 @@ static INLINE vdouble vloadu_vd_p(const double *ptr) { return _mm256_loadu_pd(pt | |||
| static INLINE void vstore_v_p_vd(double *ptr, vdouble v) { _mm256_store_pd(ptr, v); } | |||
| static INLINE void vstoreu_v_p_vd(double *ptr, vdouble v) { _mm256_storeu_pd(ptr, v); } | |||
|
|
|||
| static INLINE vdouble vgather_vd_p_vi(const double *ptr, vint vi) { | |||
| int a[4]; | |||
There was a problem hiding this comment.
Shouldn't this beint a[VECLENSP]?
src/arch/helperavx.h
Outdated
| @@ -477,6 +483,13 @@ static INLINE vfloat vloadu_vf_p(const float *ptr) { return _mm256_loadu_ps(ptr) | |||
| static INLINE void vstore_v_p_vf(float *ptr, vfloat v) { _mm256_store_ps(ptr, v); } | |||
| static INLINE void vstoreu_v_p_vf(float *ptr, vfloat v) { _mm256_storeu_ps(ptr, v); } | |||
|
|
|||
| static INLINE vfloat vgather_vf_p_vi2(const float *ptr, vint2 vi2) { | |||
| int a[8]; | |||
There was a problem hiding this comment.
Same here, shouldn't it be int a[VECLENSP]?
src/arch/helperpower_128.h
Outdated
| @@ -74,6 +74,18 @@ static INLINE void vstoreu_v_p_vf(float *ptr, vfloat v) { ptr[0] = v[0]; ptr[1] | |||
|
|
|||
| static INLINE void vscatter2_v_p_i_i_vd(double *ptr, int offset, int step, vdouble v) { vstore_v_p_vd((double *)(&ptr[2*offset]), v); } | |||
|
|
|||
| static INLINE vdouble vgather_vd_p_vi(const double *ptr, vint vi) { | |||
| int a[4]; | |||
There was a problem hiding this comment.
Shouldn't this also be int[VECLENDP]?
src/arch/helperpower_128.h
Outdated
| } | ||
|
|
||
| static INLINE vfloat vgather_vf_p_vi2(const float *ptr, vint2 vi2) { | ||
| int a[4]; |
There was a problem hiding this comment.
Shouldn't this also be int[VECLENSP]?
src/arch/helpersse2.h
Outdated
| @@ -267,6 +267,12 @@ static INLINE vdouble vloadu_vd_p(const double *ptr) { return _mm_loadu_pd(ptr); | |||
| static INLINE void vstore_v_p_vd(double *ptr, vdouble v) { _mm_store_pd(ptr, v); } | |||
| static INLINE void vstoreu_v_p_vd(double *ptr, vdouble v) { _mm_storeu_pd(ptr, v); } | |||
|
|
|||
| static INLINE vdouble vgather_vd_p_vi(const double *ptr, vint vi) { | |||
| int a[4]; | |||
src/arch/helpersve.h
Outdated
| } | ||
|
|
||
| static float vcast_f_vf(vfloat v) { | ||
| float a[64]; |
src/arch/helpersve.h
Outdated
| } | ||
|
|
||
| static int vcast_i_vi(vint v) { | ||
| int a[64]; |
src/arch/helpersve.h
Outdated
| } | ||
|
|
||
| static int vcast_i_vi2(vint2 v) { | ||
| int a[64]; |
| #ifdef ENABLE_SVE | ||
| typedef __sizeless_struct { | ||
| vfloat d; | ||
| vint2 i; |
There was a problem hiding this comment.
Shouldn't this be vint i; and not vint2 i;?
| #else | ||
| typedef struct { | ||
| vfloat d; | ||
| vint2 i; |
There was a problem hiding this comment.
Same here, shouldn't this be vint i;?
This patch adds a modified Payne Hanek argument reduction that can be used for very large arguments.
Payne Hanek reduction algorithm can handle very large arguments by table look-ups. In this patch, a vectorized version of the algorithm is implemented. The argument range for DP and SP trig functions will become [-1e+299, 1e+299] and [-1e+28, 1e+28], respectively. In order to avoid using 64 bit or 128 bit multiplication, the algorithm is modified to use DD computation. Gather instructions are used for table look-ups. The reduction subroutine is tested to confirm that it correctly handle the worst case with 6381956970095103.0 * 2.0^797.
The traditional implementation can be seen in the following gist.
https://gist.github.com/simonbyrne/d640ac1c1db3e1774cf2d405049beef3