Building and training autoregressive language models from scratch, following Andrej Karpathy's Neural Networks: Zero to Hero series.
Word2vec is a technique in natural language processing (NLP) for obtaining vector representations of words. These vectors capture information about the meaning of the word based on the surrounding(context) words.
Word2Vec SkipGram with Negative Sampling
Tokenization is splitting text into smaller units called tokens that can be fed into the language model.
- character level (too small)
- word level (too big)
- subword level (balanced)
- BPE (Algorithm which merges on argmax P(A,B), good for whitespaced languages)
- WordPiece (Algorithm which merges on argmax P(A,B)/[P(A)*P(B)], good for whitespaced languages)
- SentencePiece (Library containing optimized BPE, WordPiece, Unigram, good for non - whitespaced languages)
- Unigram (All combinations of substrings, then reduce if least impact to maximising likelihood)
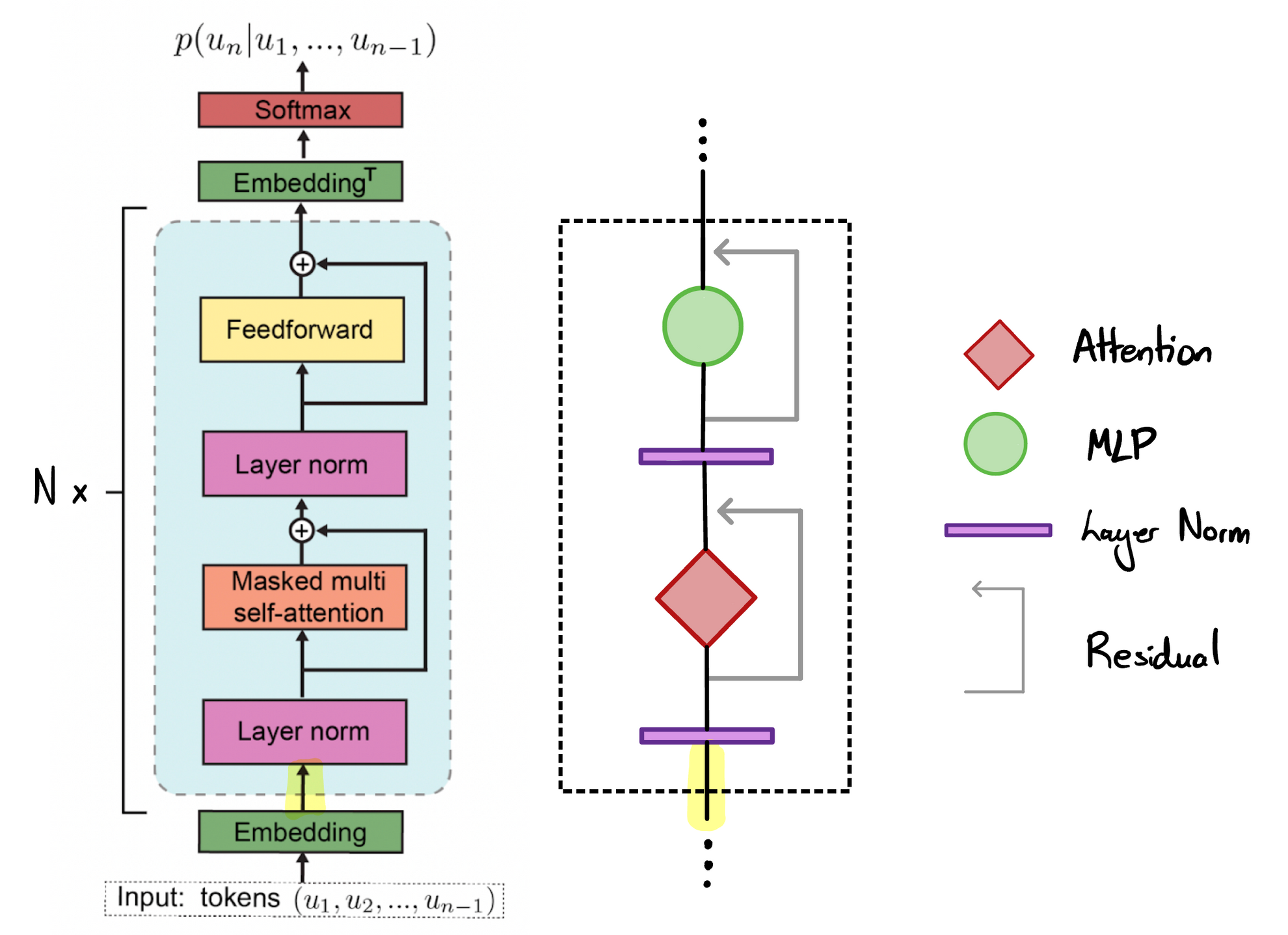
Transformer Decoder for autoregressive sequence to sequence modelling.
- LeNet
- AlexNet
- ResNet

DCGAN, or Deep Convolutional GAN, is a generative adversarial network architecture.