| 软件工程 | https://edu.cnblogs.com/campus/gdgy/CSGrade21-12 |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/gdgy/CSGrade21-12/homework/13014 |
| 作业目标 | 学习使用Java建立工程项目,学会论文查重的具体实现步骤 |
| github链接 | https://github.com/stopyc/3121005018 |
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| -Estimate | -估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 430 | 370 |
| -Analysis | -需求分析 (包括学习新技术) | 150 | 90 |
| -Design Spec | -生成设计文档 | 60 | 0 |
| -Design Review | -设计复审 | 20 | 20 |
| -Coding Standard | -代码规范 (为目前的开发制定合适的规范) | 30 | 10 |
| -Design | -具体设计 | 30 | 30 |
| -Coding | -具体编码 | 120 | 180 |
| -Code Review | -代码复审 | 20 | 40 |
| Test | 测试(自我测试,修改代码,提交修改) | 220 | 260 |
| -Reporting | -报告 | 100 | 120 |
| -Test Report | -测试报告 | 60 | 60 |
| -Size Measurement | -计算工作量 | 40 | 40 |
| -Postmortem & Process Improvement Plan | -事后总结, 并提出过程改进计划 | 20 | 40 |
| 合计 | 560 | 660 |
| 类 | 方法 | 描述 |
|---|---|---|
| Main | main() | 主程序入口 |
| 类 | 方法 | 描述 |
|---|---|---|
| interface CheckAlgorithm | double check() double check(List v1, List v2) |
算法接口,计算相似度 |
| CosAlgorithm | ~ | 实现算法接口,使用余弦定理计算相似度 |
| 类 | 方法 | 描述 |
|---|---|---|
| interface TermsSegment | void openFilter(boolean b) String parseToString(String str, String...splits) List parseToList(String str) |
分词接口 打开过滤器 将文本分词后以splits分隔转为字符串 将文本分词后转为字符串数组 |
| AnsjSeg | ~ | 实现分词接口,使用AnsjSeg第三方依赖进行分词。 |
| 类 | 方法 | 描述 |
|---|---|---|
| PaperFileUtil | String getStringFromFile(String path) void write(String path, List str) |
文件处理工具 从文件中读内容 写入答案 |
| TfIdf | static double countTf(String word, List words) static List countTfs(List words) static double countIdf(String word, List<List> papers) static List countIdfs(List words, List<List> papers) static double countTfIdf(double tf, double idf) static List countTfIdfs(List words, List<List> papers) |
TfIdf计算工具 计算文本中词集的Tf(词频),Idf(逆文本频率指数),及Tf-Idf 并以数组形式返回 |
- 1. 主程序根据传入的路径参数调用文件读写工具对文本路径中的文件进行读取。
- 2. 文件读写工具读取txt文件中的内容,转换为对应的字符串。
- 3. 使用分词模块将字符串分词。
- 4. 计算词集的Tf-Idf值。
- 5. 调用算法模块(余弦定理)计算文本相似度。
- 6. 将答案写入目标地址。
- 7. 退出程序。

传入两个文本分词后得到的词集,计算所有词的Tf-Idf,放入数组中构成n维向量
tf-Term Frequency-词频 idf-Inverse Document Frequency-逆文本频率指数
TF-IDF = TF * IDF 其中,TF可以采用以下公式计算: TF = (该单词在文章中出现的次数) / (文章中所有单词的总数) 而IDF可以采用以下公式计算: IDF = log(文集中的文章总数 / 含有该单词的文章数)
使用两个以Tf-Idf为项的n维向量代入余弦定理,计算两个文本的相似度。
由于两篇文章长度不一定相同,所得向量维数亦不同,故需要先对词集过滤、去重、选出关键词、排序,最后以两向量中维数更小的作为n计算。
注意:对词集的操作对计算结果影响十分显著。
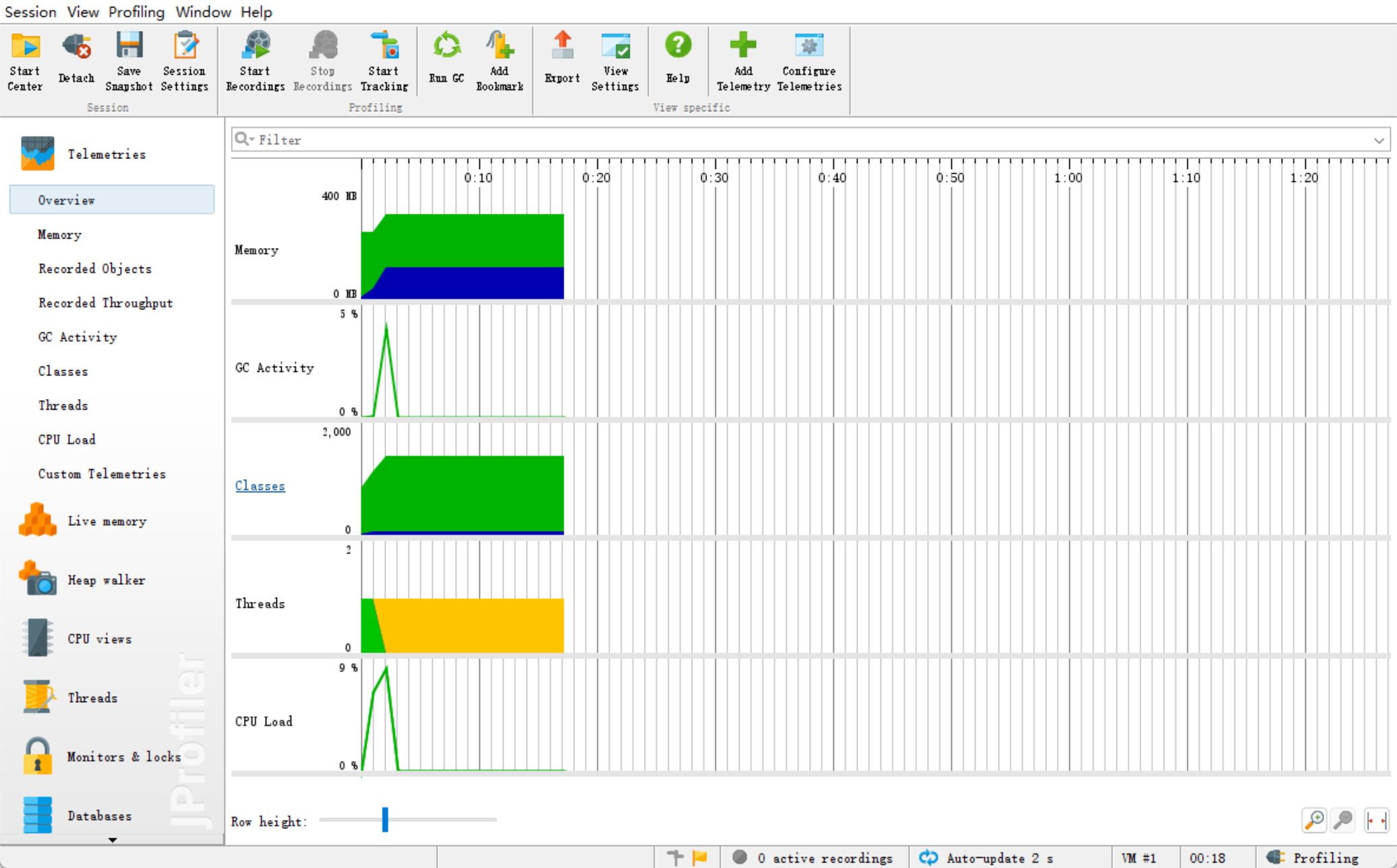
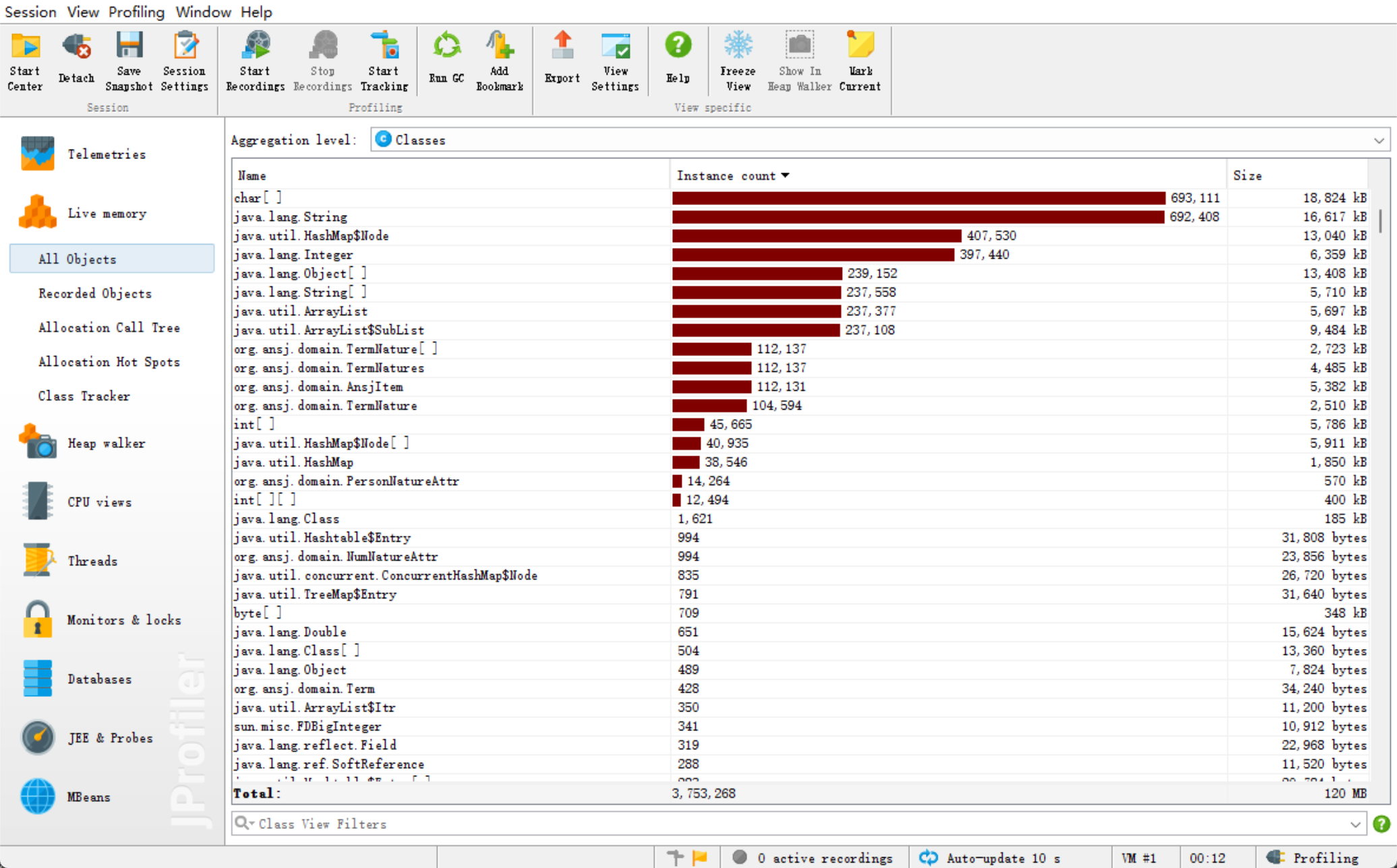
由分析图可以看出: 调用最多的是char[]和String,前者应是分词依赖相关,后者则是分词后的处理,由此看出提取出关键词、精简词集很重要
代码示例
public class CosAlgorithmTest {
Random r;
CheckAlgorithm checkAlgorithm;
@Before
public void start(){
r = new Random(1000L);
checkAlgorithm = new CosAlgorithm();
}
@Test
public void check1() {
checkAlgorithm.check();
}
@Test
public void check2() {
for(int o=0;o<10;o++) {
List<Double> v1 = new ArrayList<>();
List<Double> v2 = new ArrayList<>();
for (int i = 0; i < 100; i++) {
v1.add(r.nextDouble());
v2.add(r.nextDouble());
}
System.out.println(checkAlgorithm.check(v1, v2));
}
}
}测试思路:生成随机n维数组,代入余弦定理进行相似度计算
代码示例
public class AnsjSegTest {
ArrayList<String> str;
TermsSegment seg;
@Before
public void start(){
seg = new AnsjSeg();
seg.openFilter(false);
seg.openFilter(true);
str = new ArrayList<String>();
str.add("i don't know what to say");
str.add("Python需要将入口文件名设置成main.py,C/C++需要提供可执行文件main.exe,Java需要提供编译好的jar包main.jar");
str.add("君问归期未有期,巴山夜雨涨秋池");
try {
str.add(PaperFileUtil.getStringFromFile("D:\\Code\\PaperCheck\\src\\main\\resources\\origin_cn.txt"));
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Test
public void parseToString() {
for (String toParse:str) {
System.out.println(seg.parseToString(toParse," "));
}
}
@Test
public void parseToList() {
for (String toParse:str) {
seg.parseToList(toParse).forEach(System.out::println);
}
}
@Test
public void test(){
ToAnalysis.parse("测试一下Term").getTerms().forEach(term -> {
System.out.println(term.getRealName());
});
}
}测试思路:使用中英文本测试分词效果
代码示例
public class PaperFileUtilTest {
String originPath;
String copyPath;
String targetPath;
@Before
public void start(){
originPath = "D:\\Code\\PaperCheck\\src\\main\\resources\\origin_cn.txt";
copyPath = "D:\\Code\\PaperCheck\\src\\main\\resources\\copy_cn.txt";
targetPath = "D:\\Code\\PaperCheck\\src\\main\\resources\\target_cn.txt";
}
@Test
public void getStringFromFile() {
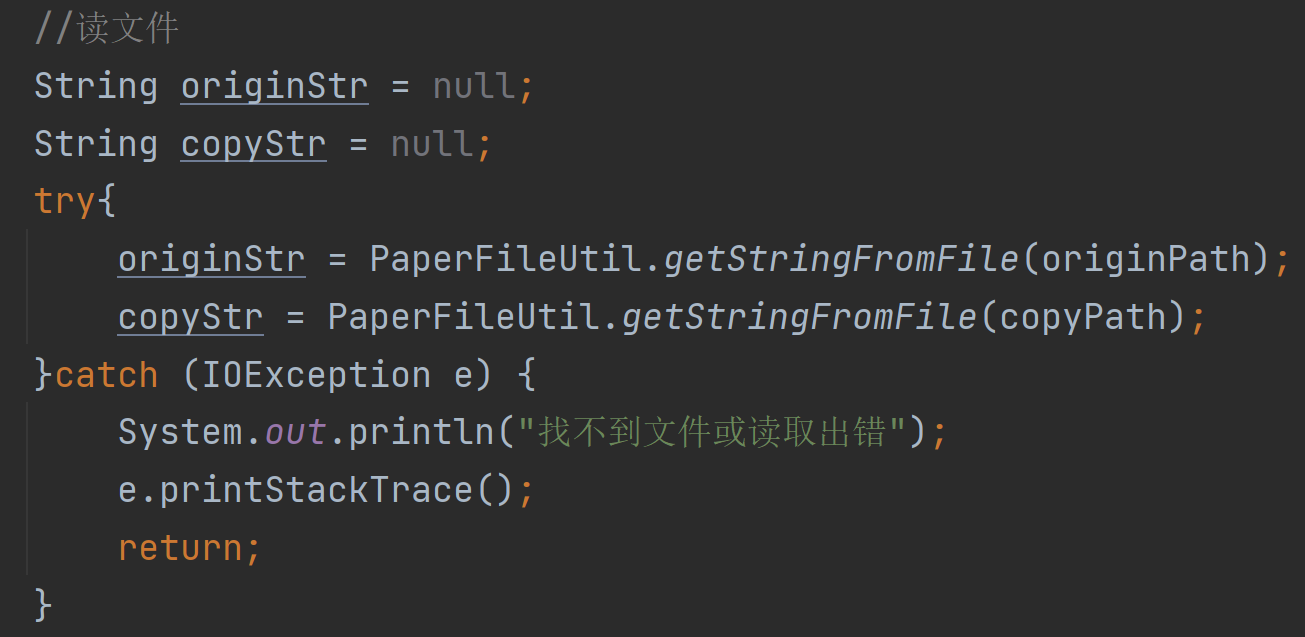
//读文件
String originStr = null;
String copyStr = null;
try{
originStr = PaperFileUtil.getStringFromFile(originPath);
copyStr = PaperFileUtil.getStringFromFile(copyPath);
}catch (IOException e) {
System.out.println("找不到文件或读取出错");
e.printStackTrace();
return;
}
System.out.println(originStr);
System.out.println(copyStr);
}
@Test
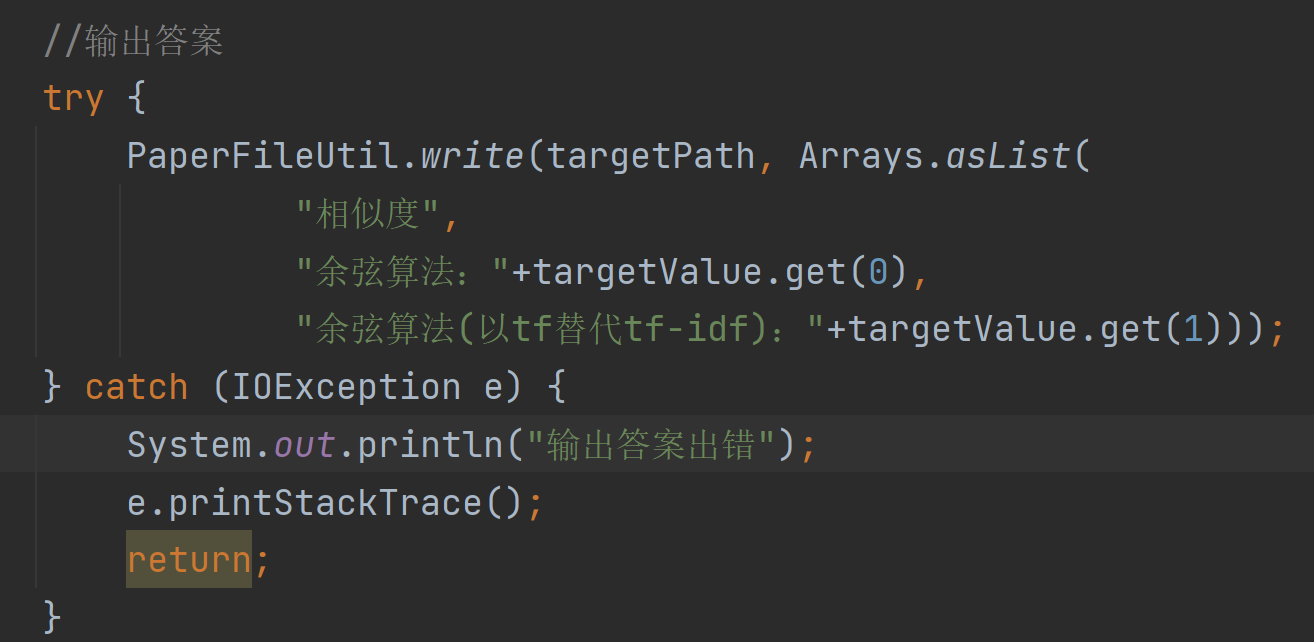
public void write() {
//输出答案
try {
PaperFileUtil.write(targetPath, Arrays.asList("答案"));
} catch (IOException e) {
System.out.println("输出答案出错");
e.printStackTrace();
return;
}
}
}代码示例
public class TfIdfTest {
Random r;
List<List<String>> papers;
List<String> originWords;
List<String> copyWords;
@Before
public void start(){
r = new Random(1000L);
String originStr = "# 模拟原文文件(中文)\n" +
"\n" +
"“\n" +
"有人住高楼,有人在深沟,有人光万丈,有人一身锈,世人万千种,浮云莫去求,斯人若彩虹,遇上方知有。\n" +
"”\n" +
"\n" +
"“\n" +
"有些人沦为平庸浅薄,金玉其外,而败絮其中。\n" +
"可不经意间,有一天你会遇到一个彩虹般绚丽的人,从此以后,其他人就不过是匆匆浮云。\n" +
"”\n" +
"\n" +
"“\n" +
"大多数人都生活在平静的绝望中,所谓听天由命,不过是习以为常的绝望。\n" +
"在人类的所谓游戏与消遣底下,甚至都隐藏着一种凝固的、不知又不觉的绝望。\n" +
"两者中都没有娱乐可言,因为工作之后才能娱乐。可是不做绝望的事,才是智慧的一种表征。\n" +
"”";
String copyStr = "# 模拟抄袭文件(中文)\n" +
"\n" +
"“\n" +
"有的人住在高楼,也有的人住在深沟,有的人光万丈,有的人一身锈,有万千种世人,浮云不要去求,这人像彩虹,遇上方就知道有。\n" +
"”\n" +
"\n" +
"“\n" +
"有些人沦为平庸浅薄,有金玉在其外,但是有败絮在其中。\n" +
"可不经意间,有一天你会遇上一个像彩虹绚丽的人,从此以后,其他人就只是匆匆浮云。\n" +
"”\n" +
"\n" +
"“\n" +
"绝大部分人都生活在平静的绝望中,所谓的听天由命,其实是一种习以为常的绝望。\n" +
"在人类的所谓消遣与游戏之下,甚至还隐藏着一种不知又不觉的、凝固的绝望。\n" +
"两者中都没有娱乐可言,因为工作之后才能娱乐。可是不做绝望的事,乃智慧之表征。\n" +
"”";
//分词
//开启过滤器
TermsSegment seg = new AnsjSeg();
seg.openFilter(true);
originWords = seg.parseToList(originStr);
copyWords = seg.parseToList(copyStr);
papers = Arrays.asList(originWords, copyWords);
}
@Test
public void countTf() {
originWords.forEach(word -> {
TfIdf.countTf(word, originWords);
});
copyWords.forEach(word -> {
TfIdf.countTf(word, copyWords);
});
}
@Test
public void countTfs() {
TfIdf.countTfs(originWords);
TfIdf.countTfs(copyWords);
}
@Test
public void countIdf() {
originWords.forEach(word -> {
TfIdf.countIdf(word, papers);
});
copyWords.forEach(word -> {
TfIdf.countIdf(word, papers);
});
}
@Test
public void countIdfs() {
TfIdf.countIdfs(originWords, papers);
TfIdf.countIdfs(copyWords, papers);
}
@Test
public void countTfIdf() {
for(int i=0;i<100;i++) {
TfIdf.countTfIdf(r.nextDouble(), r.nextDouble());
}
}
@Test
public void countTfIdfs() {
TfIdf.countTfIdfs(originWords, papers);
TfIdf.countTfIdfs(copyWords, papers);
}
}测试思路:为词集计算Tf,Idf,Tf-Idf
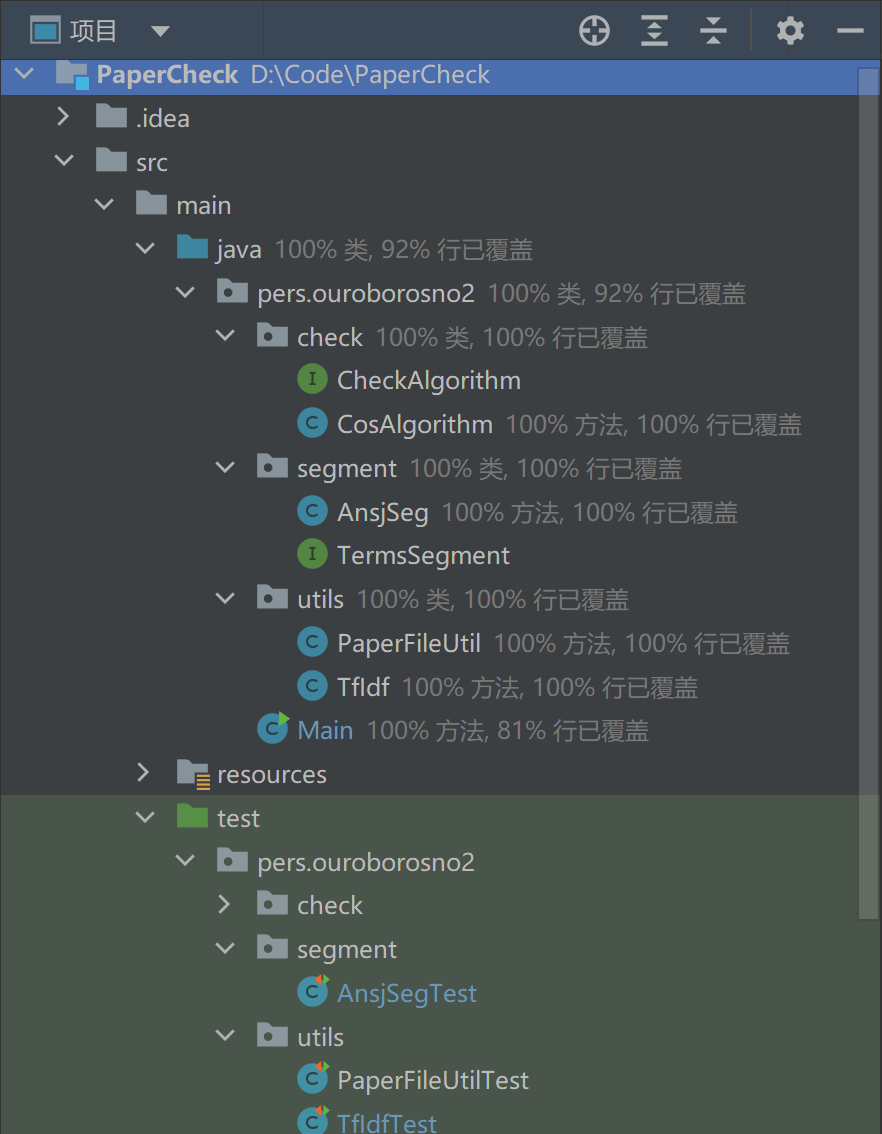
所有类均达100%覆盖
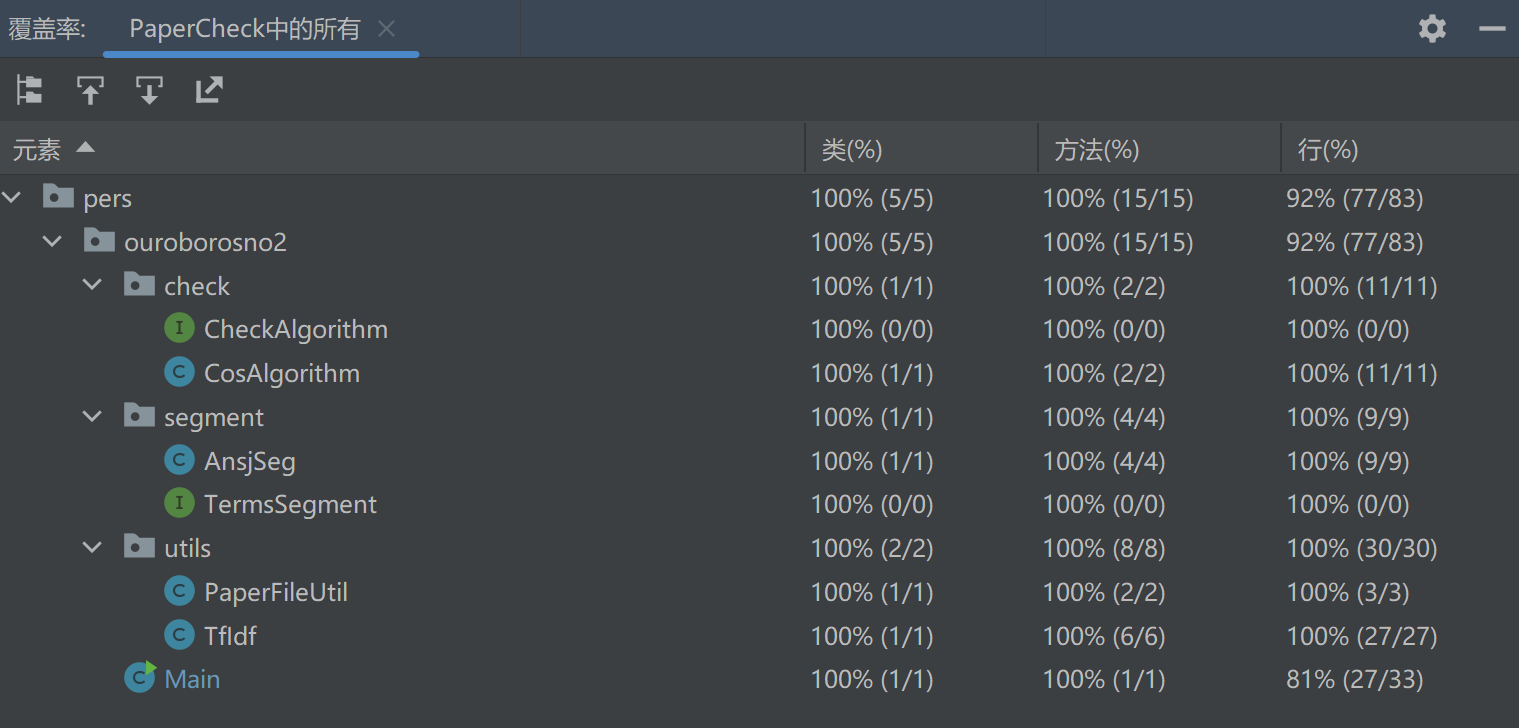
项目仅在读写文件时可能出现异常