CrawlerCommon is the Html Parser library.
CrawlerHpathUI is a sample UI of how to extract data using it.
CrawlerCommonVisualDiagnostic is a tool used to diagnose any bugs encountered in parsing a HTML document.
CrawlerCommonTest is a unit test project that is showing a lot of errors.
I obviously didn't complete every feature as planned.
It worked enough for my use case, and I stopped working on it. This has been what it does for me
IT ISN'T PERFECT b/c I just fix enough bugs, for it to serve my needs.
I THINK IT IS AN EXCELLENT PLACE TO START, if you want to figure out how to parse HTML yourself.
It has parsed Fantasy Football stats
It has parsed Football schedules
It has parsed Google Searches.
It is actually intended as a C# .NET CLR dll, for you to use to parse HTML for your project. The CrawlerHPathUI is actually intended to as a front end to test some extraction code.
Here are some screenshots
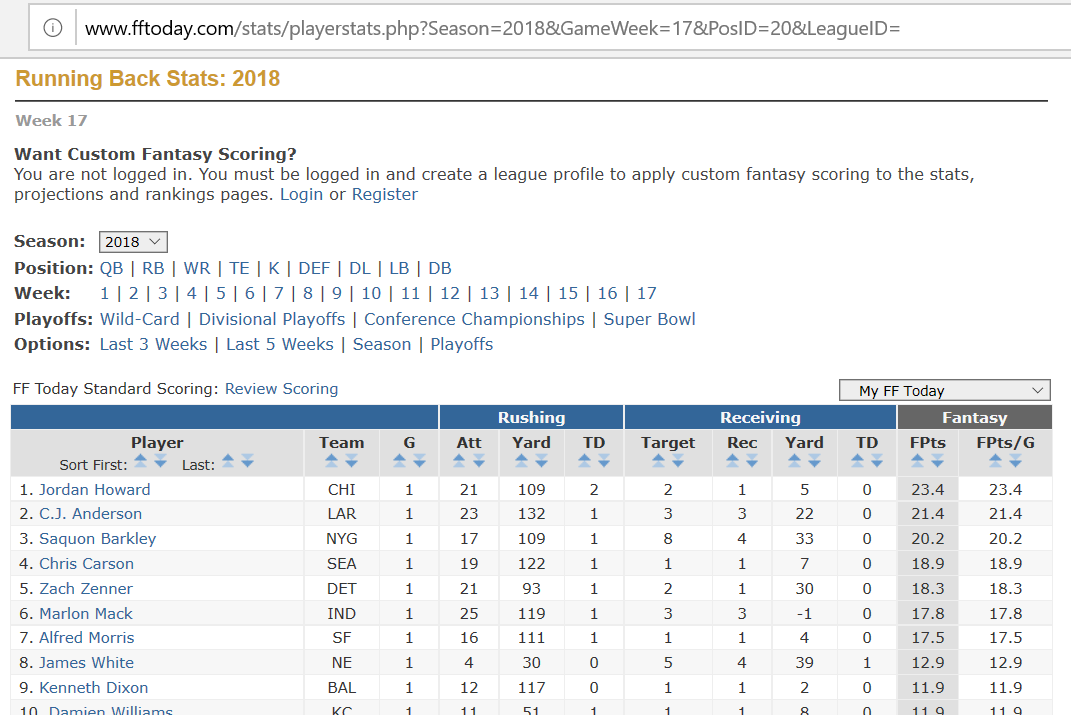



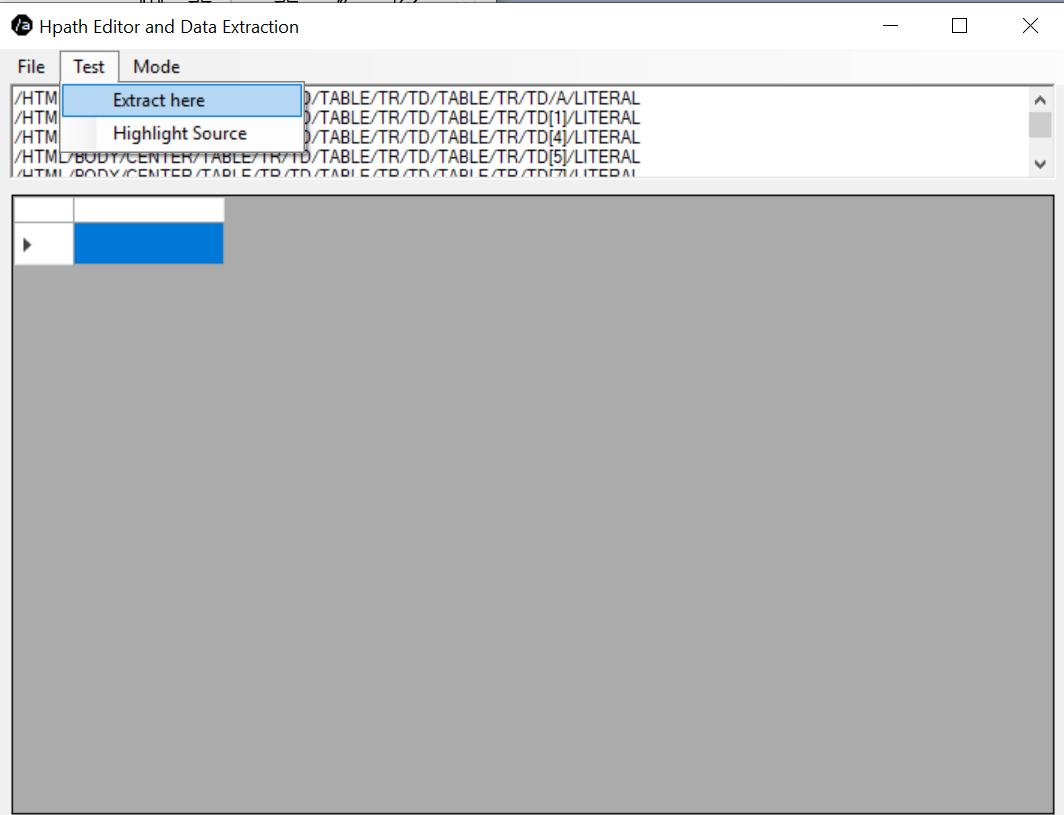

Reference the CrawlerCommon library in your own project that you extract data with, add "uses CrawlerCommon.HPath" and take those paths that extracted successfully, and paste them in HPath.Parse():
HtmlPath col1 = new CrawlerCommon.HtmlPath;
col1.Parse("DIV[@id=\"col1\"]");
HtmlPath col2 = new CrawlerCommon.HtmlPath;
col2.Parse("DIV[@id=\"col2\"]");
HtmlPath col3 = new CrawlerCommon.HtmlPath;
col3.Parse("DIV[@id=\"col3\"]");
HtmlPath col4 = new CrawlerCommon.HtmlPath;
col4.Parse("DIV[@id=\"col4\"]");
List<string[]> lst = new List<string[]>();
var row = new string[4];
var tokenizer = new CrawlerCommon.HtmlTokenizer() {TrimWhitespace=true, DebugMode=false, ShowWorkMode=false };
var builder = new CrawlerCommon.BuilderStats(new CrawlerCommon.IndexedBuilder()) { StatsOn=true };
foreach(var node in CrawlerCommon.HtmlBuilder.BuildTree(tokenizer.Tokens,builder))
{
if(col1.isMatch(node)) {
row[0]=node.ActualSymbol;
}
if(col2.isMatch(node)) {
row[1]=node.ActualSymbol;
}
if(col3.isMatch(node)) {
row[2]=node.ActualSymbol;
}
if(col4.isMatch(node)) {
row[3]=node.ActualSymbol;
lst.add(row);
row = new string[4];
}
}
Please leave a comment on how you liked it http://www.tictawf.com/blog/category/htmlparser/ http://www.tictawf.com/blog/crawlerhpathui/