Conceptual: Substrate Storage #255
Conversation
|
Notes from @cheme
|
docs/conceptual/core/storage.md
Outdated
|
|
||
| ## Trie Abstraction | ||
|
|
||
| One advantage of using a simple key-value store is that you are able to easily abstract other storage structures on top. |
There was a problem hiding this comment.
Can we put a bit more content on how a Trie is abstracting on top of a K-V store? I have worked with storage from highest level (SRML), to the lowest (raw RPC to to encoded key) and from the looks of it, honestly, I never really felt like I am working with a Trie here. It always looked more like a bare bone KV store to me.
There was a problem hiding this comment.
Would need to know what that information would look like...
Implementation details like this could be above the level of "conceptual" docs, but I agree we would want this information in the reference docs.
There was a problem hiding this comment.
I would say it is interesting to keep in mind as a runtime developper that the trie is way more costy than a standard k-v store.
General idea being that you should rather store a serialized struct with two field at a storage location rather than both field at different location, except if you want to reduce the size of the proof.
That is something that can get quite clear when you apply storage cost (if you have a base cost and variable cost for size to store).
|
@cheme Can you give a final approval when you are happy? |
There was a problem hiding this comment.
A lot of confusing paragraphs and not always clear what the point is. The "Trie Abstraction" part starts out with a few paragraphs on how tries can be used to verify state agreement, but then suddenly starts talking about performance and pruning.
Still a lot of English to be cleaned up,
- The Substrate uses a simple a key-value data store
- Tries are important tool for
- it is still easy to verify of the complete node state
docs/conceptual/core/storage.md
Outdated
|
|
||
| Substrate has a single main trie, called the state trie, whose changing root | ||
| hash is placed in each block header. This is used to easily verify the state of | ||
| the blockchain and provide a basis for light clients to verify proofs. |
There was a problem hiding this comment.
I would be interested to know more about the light clients and what exactly is proved to them. I know they only read block headers (not full blocks) so they get to see the state root before and after each block, but how do they actually know that the transactions in the block were executed correctly and lead to the resulting state root?
There was a problem hiding this comment.
what is proved to the light client is validity of an operation over a state of the chain. Say the light client does not have the full state, he get the info he need with a proof that it comes from a valid full state.
simplier example should be:
Querying keys from state trie, the request will be (from cone/network/src/protocol/message.rs):
#[derive(Debug, PartialEq, Eq, Clone, Encode, Decode)]
/// Remote storage read request.
pub struct RemoteReadRequest<H> {
/// Unique request id.
pub id: RequestId,
/// Block at which to perform call.
pub block: H,
/// Storage key.
pub keys: Vec<Vec<u8>>,
}
then the reply will be
#[derive(Debug, PartialEq, Eq, Clone, Encode, Decode)]
/// Remote read response.
pub struct RemoteReadResponse {
/// Id of a request this response was made for.
pub id: RequestId,
/// Read proof.
pub proof: Vec<Vec<u8>>,
}
To make sense out of this reply we fetch request by id and the state trie root of the requested block hash, then we query keys over the proof.
The proof is here a subset of the memorydb the state trie is build upon.
This subset contains only the trie nodes the full client does record when running the query on its side (for every keys from the request).
Then the light client run the same keys query over a trie build from the block state root (he know it from the cht) and the trie nodes he just received (field proof of response). From this incomplete state trie he can get the resulting values of every keys in input (and since every node of trie refers to each over through a crypto hash it is proof it is in the chain state).
but this way of recording some operation on a full client and re-executing over this record on a light client can apply to many thing (if you look in message.rs there is a few query, call for instance uses executor on light blockchain).
Possible future design for substrate light client seems to be allowing evaluation of some wasm code which could be a better solution than chaining queries result like it was done in eth. (better solution to reducing the number of queries roundtrip).
Not 100% sure on the following point, but proving the transition between two consecutive blocks is not something we do (I think), we just rely on the fact that the blocks got validated and we know they are chained. Surely a full client can execute the transition by running a full block on its state, so it should be possible for him to send to a light client all accessed db keys during the full block execution and next root calculation, and the light client will be able to execute the block on those keys and produce next root. But I guess the proof will be really massive, so relying on network having validating those state may be enough in the light client usecase.
But you can run any call already (see RemoteCallRequest) or query the deltas between block through RemoteChangesRequest.
There was a problem hiding this comment.
I think a slightly simpler, but hopefully still fully accurate explanation of light client proofs come from merkle proof in general.
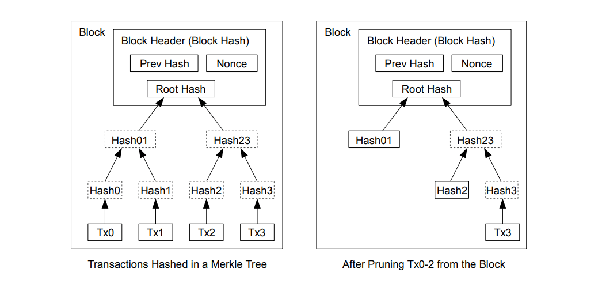
from here: https://www.quora.com/Cryptography-How-does-a-Merkle-proof-actually-work
The image hopefully shows that if you want to prove TX3 is in the trie, you dont need ALL the nodes, just the full branch will leads to TX3 and all the nodes next to the nodes on that full branch. Obviously WAYWAY less data on big tries like the ones on blockchains.
Full nodes act as the provider to light clients of the proof it needs. They do so pretty selflessly, but there are thoughts to have light clients start micro-payments to full nodes for their services.
|
I read the whole thing and learned while reading. I would really like to see an example of how and why to use a child tree. I guess how doesn't go in conceptual docs, but it should go somewhere. why probably does go here. |
That makes sense. The why, afaik, is that you want your own trie with it's own root hash that you can use the verify the state of that child trie. A trie only has a single "root hash" which describes the whole trie. Subsections of the trie do not have some hash which represents their "sub-content". But maybe you want that, only for a subsection of data.... so you make a child trie. |
Co-Authored-By: cheme <emericchevalier.pro@gmail.com>
Co-Authored-By: joe petrowski <25483142+joepetrowski@users.noreply.github.com>
Co-Authored-By: joe petrowski <25483142+joepetrowski@users.noreply.github.com>
Co-Authored-By: joe petrowski <25483142+joepetrowski@users.noreply.github.com>
…brizi/substrate-developer-hub.github.io into shawntabrizi-storage-doc
|
@joepetrowski I would like to merge this in having addressed every issue except:
I think the best option is to just remove this section:
Which is entirely implementation details. But would want to hear from engineering that this data is not important to be taught. |
Co-Authored-By: joe petrowski <25483142+joepetrowski@users.noreply.github.com>
Co-Authored-By: joe petrowski <25483142+joepetrowski@users.noreply.github.com>
Co-Authored-By: joe petrowski <25483142+joepetrowski@users.noreply.github.com>
Co-Authored-By: joe petrowski <25483142+joepetrowski@users.noreply.github.com>
Co-Authored-By: joe petrowski <25483142+joepetrowski@users.noreply.github.com>
Co-Authored-By: joe petrowski <25483142+joepetrowski@users.noreply.github.com>
Co-Authored-By: joe petrowski <25483142+joepetrowski@users.noreply.github.com>
Co-Authored-By: joe petrowski <25483142+joepetrowski@users.noreply.github.com>
Co-Authored-By: joe petrowski <25483142+joepetrowski@users.noreply.github.com>
Co-Authored-By: joe petrowski <25483142+joepetrowski@users.noreply.github.com>
Should this be in node or core?
Maybe needs a lot more content if there are relevant topics to touch on. Need storage expert to chime in.
More references
Diagram