{kind=link}
- News
- Introduction
- Citing
- Getting Started
- ESC-50 Recipe
- Speechcommands Recipe
- AudioSet Recipe
- Pretrained Models
- Use Pretrained Model For Downstream Tasks
- Contact
November, 2022: We decoupe dataset and hyper-parameters by moving hyper-parameters from src/run.py and src/traintest.py to egs/{audioset,esc50,speechcommands}/run.sh, so that it is easier to adapt the scripts to new datasets. This might cause a bug, please report if you have any issue running any recipe.
October, 2022: We add an one-click, self-contained Google Colab script for (pretrained) AST inference with attention visualization. Please test the model with your own audio at by one click (no GPU needed).
May, 2022: It was found that newer torchaudio package has different behavior with older ones in SpecAugment and will cause a bug. We find a workaround and fixed it. If you are interested, see here.
March, 2022: We released a new preprint CMKD: CNN/Transformer-Based Cross-Model Knowledge Distillation for Audio Classification, where we proposed a knowledge distillation based method to further improve the AST model performance without changing its architecture.
Feb, 2022: The Self-Supervised AST (SSAST) code is released [here]. SSAST use self-supervised pretraining instead of supervised ImageNet pretraining, so it supports arbitrary patch shape and size (e.g., a temperal frame and a square patch) with a good performance.
Nov, 2021: The PSLA training pipeline used to train AST and baseline efficientnet model code is released [here]. It is a strong audio classification training pipeline that can be used for most deep learning models. Also, it has a one-click FSD50K recipe that achieves SOTA 0.567 mAP.
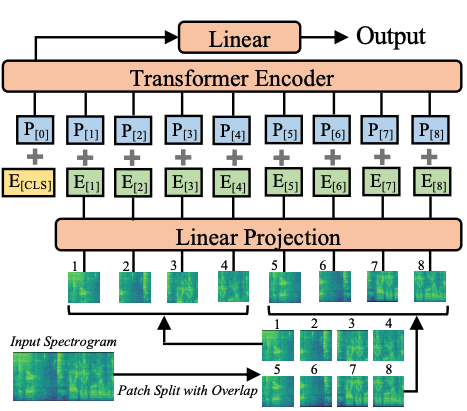
This repository contains the official implementation (in PyTorch) of the Audio Spectrogram Transformer (AST) proposed in the Interspeech 2021 paper AST: Audio Spectrogram Transformer (Yuan Gong, Yu-An Chung, James Glass).
AST is the first convolution-free, purely attention-based model for audio classification which supports variable length input and can be applied to various tasks. We evaluate AST on various audio classification benchmarks, where it achieves new state-of-the-art results of 0.485 mAP on AudioSet, 95.6% accuracy on ESC-50, and 98.1% accuracy on Speech Commands V2. For details, please refer to the paper and the ISCA SIGML talk.
Please have a try! AST can be used with a few lines of code, and we also provide recipes to reproduce the SOTA results on AudioSet, ESC-50, and Speechcommands with almost one click.
The AST model file is in src/models/ast_models.py, the recipes are in egs/[audioset,esc50,speechcommands]/run.sh, when you run run.sh, it will call /src/run.py, which will then call /src/dataloader.py and /src/traintest.py, which will then call /src/models/ast_models.py.
We have an one-click, self-contained Google Colab script for (pretrained) AST inference and attention visualization. Please test the model with your own audio at by one click (no GPU needed).
Please cite our paper(s) if you find this repository useful. The first paper proposes the Audio Spectrogram Transformer while the second paper describes the training pipeline that we applied on AST to achieve the new state-of-the-art on AudioSet.
@inproceedings{gong21b_interspeech,
author={Yuan Gong and Yu-An Chung and James Glass},
title={{AST: Audio Spectrogram Transformer}},
year=2021,
booktitle={Proc. Interspeech 2021},
pages={571--575},
doi={10.21437/Interspeech.2021-698}
}
@ARTICLE{gong_psla,
author={Gong, Yuan and Chung, Yu-An and Glass, James},
journal={IEEE/ACM Transactions on Audio, Speech, and Language Processing},
title={PSLA: Improving Audio Tagging with Pretraining, Sampling, Labeling, and Aggregation},
year={2021},
doi={10.1109/TASLP.2021.3120633}
}
Step 1. Clone or download this repository and set it as the working directory, create a virtual environment and install the dependencies.
For imaple server, we use different GPU and GPU driver from the original papers, so please check the version accordingly with the following command:
nvidia-smi
June 2023, the GPU driver is sm86 and req_sm86.txt includes library version appropriate for the driver version
cd ast/
python3 -m venv venvast
source venvast/bin/activate
pip install -r requirements.txt
Step 2. Test the AST model.
ASTModel(label_dim=527, \
fstride=10, tstride=10, \
input_fdim=128, input_tdim=1024, \
imagenet_pretrain=True, audioset_pretrain=False, \
model_size='base384')Parameters:
label_dim : The number of classes (default:527).
fstride: The stride of patch spliting on the frequency dimension, for 16*16 patchs, fstride=16 means no overlap, fstride=10 means overlap of 6 (used in the paper). (default:10)
tstride: The stride of patch spliting on the time dimension, for 16*16 patchs, tstride=16 means no overlap, tstride=10 means overlap of 6 (used in the paper). (default:10)
input_fdim: The number of frequency bins of the input spectrogram. (default:128)
input_tdim: The number of time frames of the input spectrogram. (default:1024, i.e., 10.24s)
imagenet_pretrain: If True, use ImageNet pretrained model. (default: True, we recommend to set it as True for all tasks.)
audioset_pretrain: IfTrue, use full AudioSet And ImageNet pretrained model. Currently only support base384 model with fstride=tstride=10. (default: False, we recommend to set it as True for all tasks except AudioSet.)
model_size: The model size of AST, should be in [tiny224, small224, base224, base384] (default: base384).
Input: Tensor in shape [batch_size, temporal_frame_num, frequency_bin_num]. Note: the input spectrogram should be normalized with dataset mean and std, see here.
Output: Tensor of raw logits (i.e., without Sigmoid) in shape [batch_size, label_dim].
cd ast/src
python
import os
import torch
from models import ASTModel
# download pretrained model in this directory
os.environ['TORCH_HOME'] = '../pretrained_models'
# assume each input spectrogram has 100 time frames
input_tdim = 100
# assume the task has 527 classes
label_dim = 527
# create a pseudo input: a batch of 10 spectrogram, each with 100 time frames and 128 frequency bins
test_input = torch.rand([10, input_tdim, 128])
# create an AST model
ast_mdl = ASTModel(label_dim=label_dim, input_tdim=input_tdim, imagenet_pretrain=True)
test_output = ast_mdl(test_input)
# output should be in shape [10, 527], i.e., 10 samples, each with prediction of 527 classes.
print(test_output.shape) We have an one-click, self-contained Google Colab script for (pretrained) AST inference and attention visualization. Please test the model with your own audio at by one click (no GPU needed).
The ESC-50 recipe is in ast/egs/esc50/run_esc.sh, the script will automatically download the ESC-50 dataset and resample it to 16kHz, then run standard 5-cross validation and report the result.
The recipe was tested on 4 GTX TITAN GPUs with 12GB memory.
The result is saved in ast/egs/esc50/exp/yourexpname/acc_fold.csv (the accuracy of fold 1-5 and the averaged accuracy), you can also check details in result.csv and best_result.csv (accuracy, AUC, loss, etc of each epoch / best epoch).
We attached our log file in ast/egs/esc50/test-esc50-f10-t10-p-b48-lr1e-5, the model achieves 95.75% accuracy.
To run the recipe, simply comment out . /data/sls/scratch/share-201907/slstoolchainrc in ast/egs/esc50/run_esc.sh, adjust the path if needed, and run:
cd ast/egs/esc50
(slurm user) sbatch run_esc50.sh
(local user) ./run_esc50.sh
The Speechcommands recipe is in ast/egs/speechcommands/run_sc.sh, the script will automatically download the Speechcommands V2 dataset, train an AST model on the training set, validate it on the validation set, and evaluate it on the test set.
The recipe was tested on 4 GTX TITAN GPUs with 12GB memory.
The result is saved in ast/egs/speechcommands/exp/yourexpname/eval_result.csv in format [val_acc, val_AUC, eval_acc, eval_AUC], you can also check details in result.csv (accuracy, AUC, loss, etc of each epoch).
We attached our log file in ast/egs/speechcommends/test-speechcommands-f10-t10-p-b128-lr2.5e-4-0.5-false, the model achieves 98.12% accuracy.
To run the recipe, simply comment out . /data/sls/scratch/share-201907/slstoolchainrc in ast/egs/esc50/run_sc.sh, adjust the path if needed, and run:
cd ast/egs/speechcommands
(slurm user) sbatch run_sc.sh
(local user) ./run_sc.sh
Audioset is a little bit more complex, you will need to prepare your data json files (i.e., train_data.json and eval_data.json) by your self.
The reason is that the raw wavefiles of Audioset is not released and you need to download them by yourself. We have put a sample json file in ast/egs/audioset/data/datafiles, please generate files in the same format (You can also refer to ast/egs/esc50/prep_esc50.py and ast/egs/speechcommands/prep_sc.py.). Please keep the label code consistent with ast/egs/audioset/data/class_labels_indices.csv.
Once you have the json files, you will need to generate the sampling weight file of your training data (please check our PSLA paper to see why it is needed).
cd ast/egs/audioset
python gen_weight_file.py ./data/datafiles/train_data.json
Then you just need to change the tr_data and te_data in /ast/egs/audioset/run.sh and then
cd ast/egs/audioset
(slurm user) sbatch run.sh
(local user) ./run.sh
You should get a model achieves 0.448 mAP (without weight averaging) and 0.459 (with weight averaging). This is the best single model reported in the paper.
The result of each epoch is saved in ast/egs/audioset/exp/yourexpname/result.csv in format [mAP, mAUC, precision, recall, d_prime, train_loss, valid_loss, cum_mAP, cum_mAUC, lr]
, where cum_ results are the checkpoint ensemble results (i.e., averaging the prediction of checkpoint models of each epoch, please check our PSLA paper for details). The result of weighted averaged model is saved in wa_result.csv in format [mAP, AUC, precision, recall, d-prime]. We attached our log file in ast/egs/audioset/test-full-f10-t10-pTrue-b12-lr1e-5/, the model achieves 0.459 mAP.
In order to reproduce ensembe results of 0.475 mAP and 0.485 mAP, please train 3 models use the same setting (i.e., repeat above three times) and train 6 models with different tstride and fstride, and average the output of the models. Please refer to ast/egs/audioset/ensemble.py. We attached our ensemble log in /ast/egs/audioset/exp/ensemble-s.log and ensemble-m.log. You can use our pretrained models (see below) to test ensemble result.
We use 16kHz for our experiments. Note that you might get a slightly different result with us due to the YouTube videos are being removed with the time and your downloaded version might be different with us. We provide our evaluation audio ids in ast/egs/audioset/data/sanity_check/our_as_eval_id.csv. And please note that in order to compre with the PSLA paper, for the balanced training set experiments (with results of 0.347 mAP and 0.378 mAP), we use the enhanced label set (i.e., a label set that is modified by an algorithm, please see the PSLA paper for detail). So if you train with the original label set for the balanced training set, you will get a slightly worse result. However, we do not use enhanced label set for full AudioSet experiments, i.e., for the 0.459 mAP (single) and 0.485 mAP (ensemble) results, we use exactly same data and label with the official release, so you should be able to reproduce that.
We provide full AudioSet pretrained models and Speechcommands-V2-35 pretrained model.
-
Full AudioSet, 10 tstride, 10 fstride, with Weight Averaging (0.459 mAP)
-
Full AudioSet, 10 tstride, 10 fstride, without Weight Averaging, Model 1 (0.450 mAP)
-
Full AudioSet, 10 tstride, 10 fstride, without Weight Averaging, Model 2 (0.448 mAP)
-
Full AudioSet, 10 tstride, 10 fstride, without Weight Averaging, Model 3 (0.448 mAP)
-
Full AudioSet, 12 tstride, 12 fstride, without Weight Averaging, Model (0.447 mAP)
-
Full AudioSet, 14 tstride, 14 fstride, without Weight Averaging, Model (0.443 mAP)
-
Full AudioSet, 16 tstride, 16 fstride, without Weight Averaging, Model (0.442 mAP)
If you want to finetune AudioSet-pretrained AST model on your task, you can simply set the audioset_pretrain=True when you create the AST model, it will automatically download model 1 (0.459 mAP). In our ESC-50 recipe, AudioSet pretraining is used.
If you want to reproduce ensemble experiments, you can download these models at one click using ast/egs/audioset/download_models.sh. Ensemble model 2-4 achieves 0.475 mAP, Ensemble model 2-7 achieves and 0.485 mAP. Once you download the model, you can try ast/egs/audioset/ensemble.py, you need to change the eval_data_path and mdl_list to run it. We attached our ensemble log in /ast/egs/audioset/exp/ensemble-s.log and ensemble-m.log.
Please note that we use 16kHz audios for training and test (for all AudioSet, SpeechCommands, and ESC-50), so if you want to use the pretrained model, please prepare your data in 16kHz.
(Note: the above links are Dropbox direct links (i.e., can be downloaded by wget) and should work for most users. For users having issue downloading with the above Dropbox links, it is recommended to use a VPN or use the OneDrive links or 腾讯微云链接们, however, OneDrive and 腾讯微云 links are not direct link, please manually download the audioset_10_10_0.4593.pth[OneDrive] [腾讯微云] and place it in ast/pretrained_models if you want to set audioset_pretrain=True because the wget link in the ast/src/models/ast_models.py would fail if you cannot connect to Dropbox.)
You can use the pretrained AST model for your own dataset. There are two ways to doing so.
You can of course only take ast/src/models/ast_models.py, set audioset_pretrain=True, and use it with your training pipeline, the only thing need to take care of is the input normalization, we normalize our input to 0 mean and 0.5 std. To use the pretrained model, you should roughly normalize the input to this range. You can check ast/src/get_norm_stats.py to see how we compute the stats, or you can try using our AudioSet normalization input_spec = (input_spec + 4.26) / (4.57 * 2). Using your own training pipeline might be easier if you already have a good one.
Please note that AST needs smaller learning rate (we use 10 times smaller learning rate than our CNN model proposed in the PSLA paper) and converges faster, so please search the learning rate and learning rate scheduler for your task.
If you want to use our training pipeline, you would need to modify below for your new dataset.
- You need to create a json file, and a label index for your dataset, see
ast/egs/audioset/data/for an example. - In
/your_dataset/run.sh, you need to specify the data json file path. You need to setdataset_meananddataset_std, if don't know, you can use our AudioSet stats (mean=-4.27, std=4.57); You need to setaudio_length, which should be the number of frames (e.g., with a 10ms hop, 10-second audio=1000 frames); You need to set themetricsin [acc,mAP] andlossin [CE,BCE]; You need to set the inital learning ratelrand learning rate schedulerlrscheduler_{start,step,decay}; You also need to set the SpecAug parameters (freqmandtimem, we recommend to mask 48 frequency bins out of 128, and 20% of your time frames), the mixup rate (i.e., how many samples are mixup samples), batch size, etc. While it seems a lot, it is easy if you start with one of our recipe:ast/egs/[audioset,esc50,speechcommands]/run.sh].
To summarize, to use our training pipeline, you need to creat data files and modify the shell script. You can refer to our ESC-50 and Speechcommands recipes.
Also, please note that we use 16kHz audios for the pretrained model, so if you want to use the pretrained model, please prepare your data in 16kHz.
If you have a question, please bring up an issue (preferred) or send me an email thp29@drexel.edu.