-
Small game to demonstrate basic machine learning concepts using a simple linear regression model.
-
The objective of the game is to balance the stick in the cart while keeping the cart inside of the lines as long as possible.
-
The game ends if the stick falls off the cart or if the cart hits the side walls. To control the cart the player can press left or right to accelerate the cart.
-
Might seem a fairly simple task but takes a while even for a human player to master it. Try it out here for yourself. Or just watch me trying to play it bellow.
-
While the game is running a score is calculated based on the amount of time that the player was able to hold the pendulum without hitting the wall.
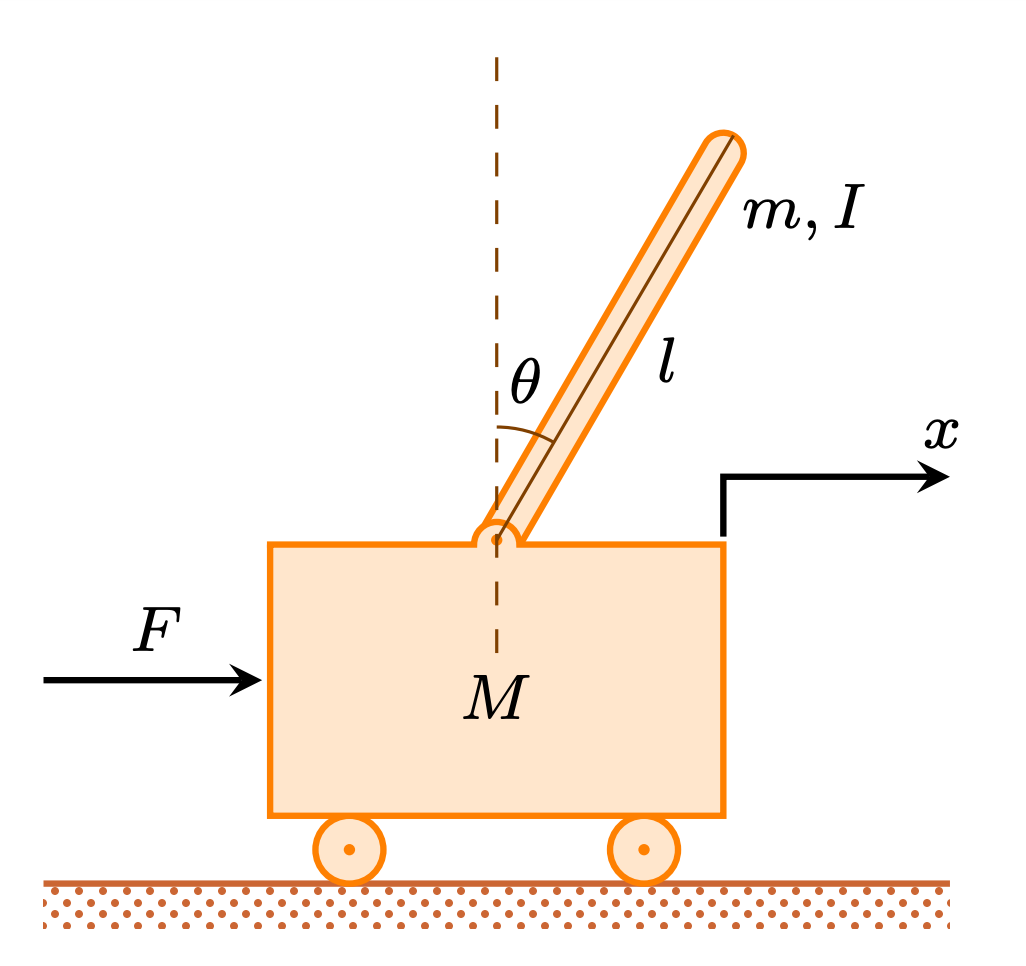
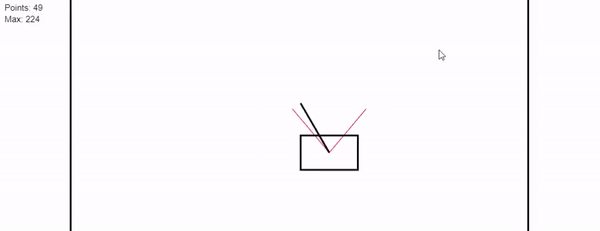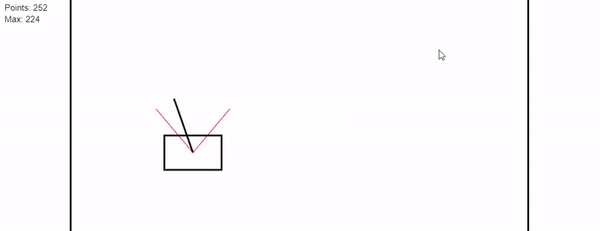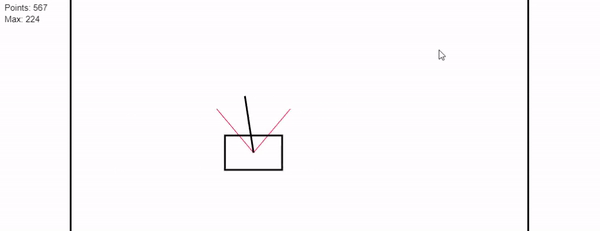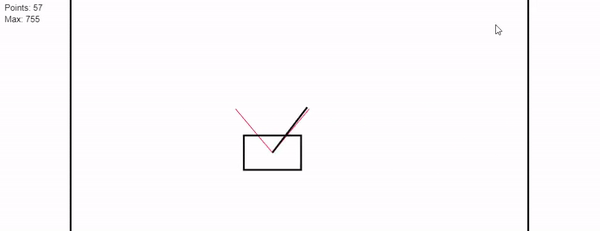
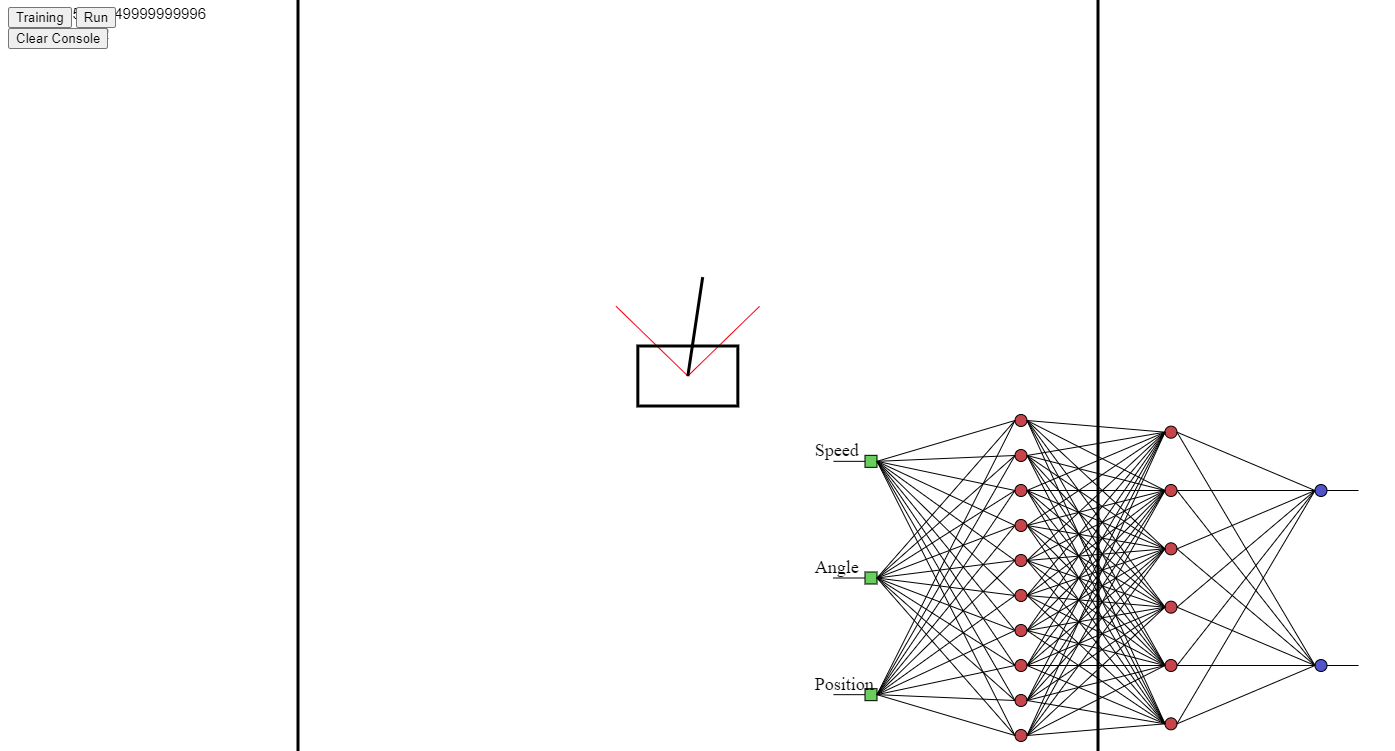
- A live demo of the linear model is available with two training approaches for the linear model. Training parameters can be changed in the GUI.
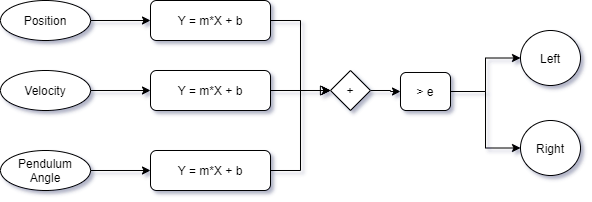
- The model has three inputs: the
positionandvelocityof the cart and theangleof pendulum. - The model has two outputs:
leftbutton pressed andrightbutton pressed. - For each input parameter a linear weight (m) and offset (b) are be applied.
- The final decision is the sum of all weights that is then compared with a threshold to decide the action.
- The challenge with training is to determine the ideal
mandbfor each input variable and theevalue. - In other words training will consist in experimenting different values until we reach a value that is successful.
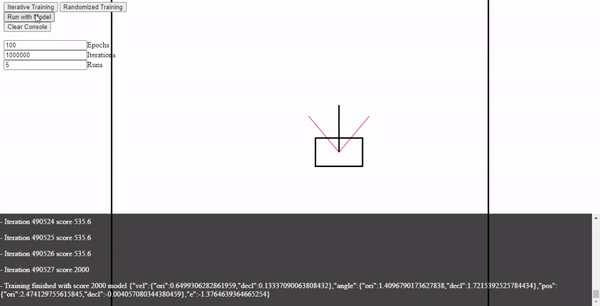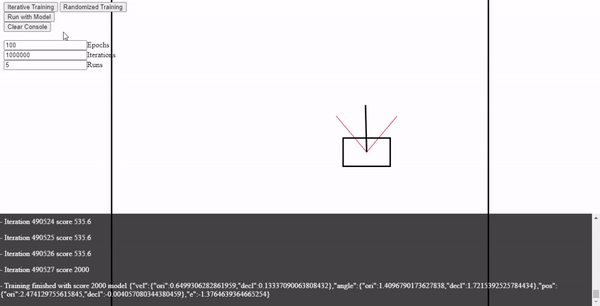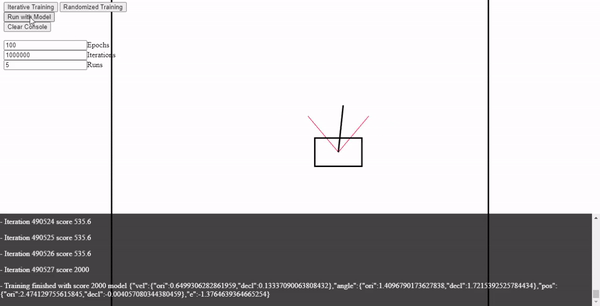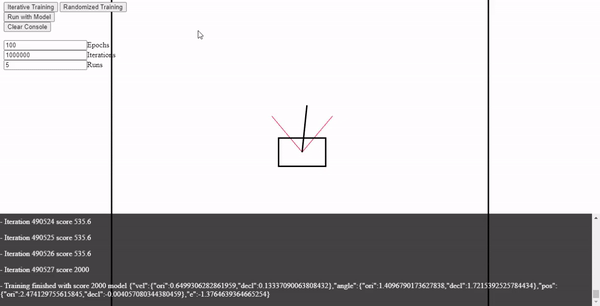
- A simple approach to train the model is simply to randomly test for values until a good set of parameters appears that yields a good score.
- As we can see for this case after 490K combinations we obtained one that yields perfect results!
- Took a while but means that simple linear model can handle the task.
- This training approach of course would not be usable for any real complex environment.
- To ensure convergence of the training process a iterative/genetic approach should be used.
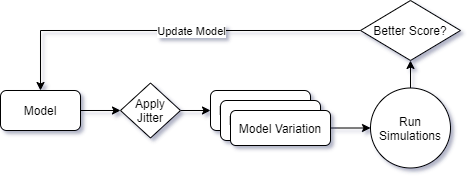
-
We start with a random base model, test variations of the model and select the one that improved results, repeat until we get good results.
-
With iterative training we can get near perfect results few epochs (~5 in average) wich is a lot faster than random testing.
-
During this process we should also look out for local maximum. This happens when we get stuck with values that cannot be improved further.
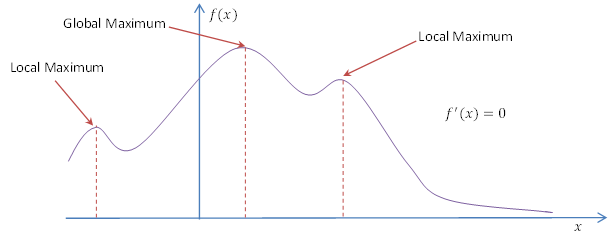
- Now that we got the basics right lets try and train the system using a more complex neural model with brain.js.
- Try the NN version here, you will need data for training that can be generated by playing the game manually or obtained from the git repo.
- Our inputs will be the same
position,velocityandangleand the outputs will berightandleft. - Contrary to the linear model where we test combinations of parameters to find the best configuration.
- For the neural-network we need to provide datasets of game variables and decisions for training.
- These datasets can be recorded from sessions from human players or even for example from the linear model.
[
{"input": [0.4562460470209,-0.0022812302351045,0.456246047020],
"output": [0.0,1.0]}, ...
]- After training a visualization of the network can be generated where we can observe the inputs their weights and the outputs produced.
- This project is distributed under MIT license and can be used for commercial applications.
- License is available on the Github page of the project.