-
Notifications
You must be signed in to change notification settings - Fork 68
New issue
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
improve the robust of balance region scheduler #85
Open
bufferflies
wants to merge
7
commits into
tikv:master
Choose a base branch
from
bufferflies:feature/robus
base: master
Could not load branches
Branch not found: {{ refName }}
Loading
Could not load tags
Nothing to show
Loading
Are you sure you want to change the base?
Some commits from the old base branch may be removed from the timeline,
and old review comments may become outdated.
Open
Changes from all commits
Commits
Show all changes
7 commits
Select commit
Hold shift + click to select a range
38b6fe4
improve the robust of scheduler
bufferflies e951aeb
format
bufferflies 6da63b8
format
bufferflies 509e480
gramma && rename title
bufferflies 7d1a4db
grama
bufferflies 47488d5
grama && rename file
bufferflies eef4f8c
Merge branch 'feature/robus' of github.com:bufferflies/rfcs into feat…
bufferflies File filter
Filter by extension
Conversations
Failed to load comments.
Loading
Jump to
Jump to file
Failed to load files.
Loading
Diff view
Diff view
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,63 @@ | ||
| # Improve the robust of balance scheduler | ||
|
|
||
| - RFC PR: [https://github.com/tikv/rfcs/pull/85](https://github.com/tikv/rfcs/pull/83) | ||
| - Tracking Issue: [https://github.com/tikv/pd/issues/](https://github.com/tikv/pd/issues/4428) | ||
|
|
||
| ## Summary | ||
|
|
||
| Make schedulers more robust for dynamic region size. | ||
|
|
||
| ## Motivation | ||
|
|
||
| We have observed many different situations when the region size is different. The major drawback comes from these aspects: | ||
|
|
||
| 1. Balance region scheduler picks source store in order of store's score, the lower store will be picked after the higher store has not met some filter or retry times exceed fixed value. If the count of placement rules or tikv is bigger, the lower store has less chance to balance like TiFlash. | ||
| 2. splitting rocksDB and sending them by region leader will occupy cpu and io resources. | ||
| 3. There are some factors that influence execution time of an operator such as region size, IO limit, cpu load. PD needs to be more flexible to manage operator's timeout threshold rather than not fixed value. | ||
| 4. PD should know some global config about TiKV like `region-max-size`, `region-report-interval`. This config should synchronize with PD. | ||
|
|
||
| ## Detailed design | ||
|
|
||
| ### Store pick strategy | ||
|
|
||
| It can arrange all the stores based on label, like TiKV and TiFlash and allow low score groups more chances to schedule. But the first score region should have the highest priority to be selected. | ||
|
|
||
| #### Consider Influence to leader | ||
|
|
||
| It will add a new store limit to decrease leader loads of every store. Picking region should check if the leader token is available. | ||
|
|
||
| ### Operator control | ||
|
|
||
| #### Store limit cost | ||
|
|
||
| Different size regions occupy tokens should be different. Maybe can use this formula: | ||
|
|
||
|  | ||
|
|
||
| Cost equals 200 if operator influence is 1MB or equals 600 if operator influence is 1GB. | ||
|
|
||
| #### Operator life cycle | ||
|
|
||
| The operator life cycle can be divided into some stages: create, executing(started), complete. PD will check operator stage by region heartbeat and cancel if one operator‘s running time exceeds the fixed value(10m). | ||
|
|
||
| It will be better if we can calculate every step expecting execute duration by major factor includes region size, IO limit and operator concurrency like this: | ||
|
|
||
| 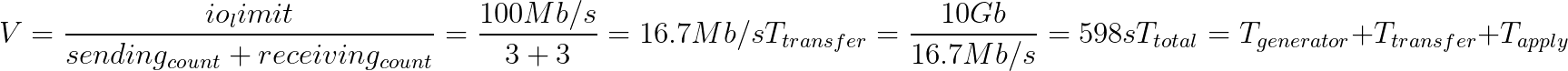 | ||
|
|
||
| The snapshot generator duration can be ignored because it doesn't need to scan. The applying snapshot duration will finish at minute level if it needs to load hot buckets. | ||
|
|
||
| ### Sync global config | ||
|
|
||
| There are some global config that all components need to synchronize like `region-max-size`, `io-limit`. Using ETCD api to implement global config may be a good idea like [this](<[https://github.com/pingcap/tidb/pull/31010/files](https://github.com/pingcap/tidb/pull/31010/files)>) | ||
|
|
||
| ## Drawbacks | ||
|
|
||
| ## Alternatives | ||
|
|
||
| Removing peer may not influence the cluster performance, it can be replaced by leader store limit. | ||
|
|
||
| Canceling operators can depend on TiKV not by PD, but TiKV should notify PD after canceling one operator. | ||
|
|
||
| ## Questions | ||
|
|
||
| ## Unresolved questions | ||
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Do you mean sync the config from TiKV to PD, or from PD to TiKV?