an in-memory immutable data manager
![]()


Vineyard (v6d) is an in-memory immutable data manager that provides out-of-the-box high-level abstraction and zero-copy in-memory sharing for distributed data in big data tasks, such as graph analytics (e.g., GraphScope), numerical computing (e.g., Mars), and machine learning.

Vineyard is a CNCF sandbox project and indeed made successful by its community.
- Overview
- Features of vineyard
- Getting started with vineyard
- Deploying on Kubernetes
- Frequently asked questions
- Getting involved in our community
- Third-party dependencies
Vineyard is designed to enable zero-copy data sharing between big data systems. Let's begin with a typical machine learning task of time series prediction with LSTM. We can see that the task is divided into steps of works:
- First, we read the data from the file system as a
pandas.DataFrame. - Then, we apply some preprocessing jobs, such as eliminating null values to the dataframe.
- After that, we define the model, and train the model on the processed dataframe in PyTorch.
- Finally, the performance of the model is evaluated.
On a single machine, although pandas and PyTorch are two different systems targeting different tasks, data can be shared between them efficiently with little extra-cost, with everything happening end-to-end in a single python script.
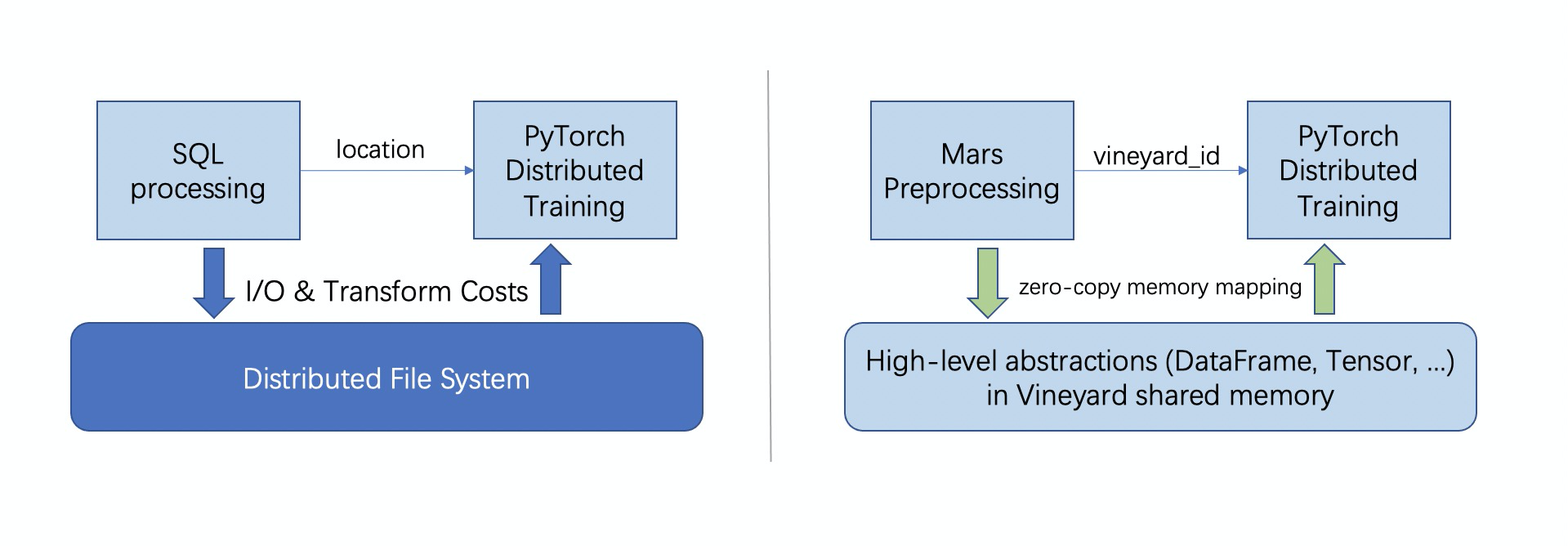
What if the input data is too big to be processed on a single machine?
As illustrated on the left side of the figure, a common practice is to store the data as tables on
a distributed file system (e.g., HDFS), and replace pandas with ETL processes using SQL over a
big data system such as Hive and Spark. To share the data with PyTorch, the intermediate results are
typically saved back as tables on HDFS. This can bring some headaches to developers.
- For the same task, users are forced to program for multiple systems (SQL & Python).
- Data could be polymorphic. Non-relational data, such as tensors, dataframes and graphs/networks (in GraphScope) are becoming increasingly prevalent. Tables and SQL may not be best way to store/exchange or process them. Having the data transformed from/to "tables" back and forth between different systems could be a huge overhead.
- Saving/loading the data to/from the external storage requires lots of memory-copies and IO costs.
Vineyard is designed to solve these issues by providing:
- In-memory distributed data sharing in a zero-copy fashion to avoid introducing extra I/O costs by exploiting a shared memory manager derived from plasma.
- Built-in out-of-the-box high-level abstraction to share the distributed data with complex structures (e.g., distributed graphs) with nearly zero extra development cost, while the transformation costs are eliminated.
As shown in the right side of the above figure, we illustrate how to integrate vineyard to solve the task in the big data context.
First, we use Mars (a tensor-based unified framework for large-scale data computation which scales Numpy, Pandas and Scikit-learn) to preprocess the raw data just like the single machine solution do, and save the preprocessed dataframe into vineyard.
| single | data_csv = pd.read_csv('./data.csv', usecols=[1]) |
| distributed | import mars.dataframe as md
dataset = md.read_csv('hdfs://server/data_full', usecols=[1])
# after preprocessing, save the dataset to vineyard
vineyard_distributed_tensor_id = dataset.to_vineyard() |
Then, we modify the training phase to get the preprocessed data from vineyard. Here vineyard makes the sharing of distributed data between Mars and PyTorch just like a local variable in the single machine solution.
| single | data_X, data_Y = create_dataset(dataset) |
| distributed | client = vineyard.connect(vineyard_ipc_socket)
dataset = client.get(vineyard_distributed_tensor_id).local_partition()
data_X, data_Y = create_dataset(dataset) |
Finally, we run the training phase distributedly across the cluster.
From the example, we see that with vineyard, the task in the big data context can be handled with only minor modifications to the single machine solution. Compare with the existing approaches, the I/O and transformation overheads are also eliminated.
Vineyard is an in-memory immutable data manager, sharing immutable data across different systems via shared memory without extra overheads. Vineyard eliminates the overhead of serialization/deserialization and IO during exchanging immutable data between systems.
Computation frameworks usually have their own data abstractions for high-level concepts, for example tensor could be torch.tensor, tf.Tensor, mxnet.ndarray etc., not to mention that every graph processing engine has its own graph structure representations.
The variety of data abstractions makes the sharing hard. Vineyard provides out-of-the-box high-level data abstractions over in-memory blobs, by describing objects using hierarchical metadatas. Various computation systems can utilize the built-in high level data abstractions to exchange data with other systems in computation pipeline in a concise manner.
A computation doesn't need to wait all precedent's result arrive before starting to work. Vineyard provides stream as a special kind of immutable data for such pipelining scenarios. The precedent job can write the immutable data chunk by chunk to vineyard, while maintaining the data structure semantic, and the successor job reads shared-memory chunks from vineyard's stream without extra copy cost, then triggers it's own work. The overlapping helps for reducing the overall processing time and memory consumption.
Many big data analytical tasks have lots of boilerplate routines for tasks that unrelated to the computation itself, e.g., various IO adaptors, data partition strategies and migration jobs. As the data structure abstraction usually differs between systems such routines cannot be easily reused.
Vineyard provides such common manipulate routines on immutable data as drivers. Besides sharing the high level data abstractions, vineyard extends the capability of data structures by drivers, enabling out-of-the-box reusable routines for the boilerplate part in computation jobs.
Vineyard is distributed as a python package and can be easily installed with pip:
pip3 install vineyardThe latest version of online documentation can be found at https://v6d.io.
If you want to build vineyard from source, please refer to Installation, and refer to Contributing for how to build and run unittests locally.
Once installed, you can start a vineyard instance with:
python3 -m vineyardFor more details about connecting to a locally deployed vineyard instance, please refer to Getting Started.
Vineyard helps share immutable data between different workloads, is a natural fit to cloud-native computing. Vineyard could provide efficient distributed data sharing in cloud-native environment by embracing cloud-native big data processing and Kubernetes helps vineyard leverage the scale-in/out and scheduling ability of Kubernetes.
In order to better manage all the components of the vineyard in the kubernetes cluster, we designed the vineyard operator, please check the Vineyard Operator for more information.
Vineyard shares many similarities with other opensource projects, but still differs a lot with them. We are frequently asked with the following questions about vineyard,
Q: Can clients look at the data while the stream is being filled?
One piece of data for multiple clients is one of the target scenarios as the data live in vineyard is immutable, and multiple clients can safely consume the same piece of data by memory sharing, without the extra cost and extra memory usage of copying data back and forth.
Q: How vineyard avoids serialization/deserialization between systems in different languages?
Vineyard provides higher-level data abstractions (e.g., ndarrays, dataframes) that could be shared in a natural way between different processes.
. . . . . .
For more detailed information, please refer to our FAQ page.
- Join in the CNCF Slack and navigate to the
#vineyardchannel for discussion. - Read contribution guide.
- Please report bugs by submitting a GitHub issue or ask me anything in Github discussion.
- Submit contributions using pull requests.
Thank you in advance for your contributions to vineyard!
We thank the following excellent open-source projects:
- apache-arrow, a cross-language development platform for in-memory analytics.
- boost-leaf, a C++ lightweight error augmentation framework.
- ctti, a C++ compile-time type information library.
- dlmalloc, Doug Lea's memory allocator.
- etcd-cpp-apiv3, a C++ API for etcd's v3 client API.
- flat_hash_map, an efficient hashmap implementation.
- wyhash, C++ wrapper around wyhash and wyrand.
- mimalloc, a general purpose allocator with excellent performance characteristics.
- nlohmann/json, a json library for modern c++.
- pybind11, a library for seamless operability between C++11 and Python.
- s3fs, a library provide a convenient Python filesystem interface for S3.
- tbb a C++ library for threading building blocks.
- skywalking-infra-e2e A generation End-to-End Testing framework.
- skywalking-swck A kubernetes operator for the Apache Skywalking.
Vineyard is distributed under Apache License 2.0. Please note that third-party libraries may not have the same license as vineyard.
