gyazoCrawler is a python scrip to index and download Gyazo screenshots. It worked even without 'ninja', it's fixed now:
Edit the main.py file variables with your cookies and files/folders. Run it with py2 and you will have 2 main options:
- Index database of gyazos - will fetch gyazo.com and create your database of links;
- Calculate the size and download the all the images from the DB - will calculate the size from the database file, and then ask if you want them to be downloaded, if so they will go on the specified folder. (note that the size value is calculated by the
"file_size"key, and some images may not have this)
I'm not affiliated with Gyazo in any way.
For the Gyazo team/company:
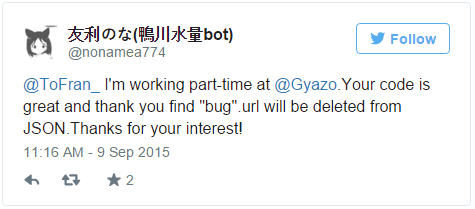
- I could not find anything that explicitly said, that this practice of recovering and downloading old gyazos was against your policy.
- I completely understand that you may not like this, if you want to stop it you should remove
"url","permalink_url"and"permalink_path"from the JSON response - If you wish the removal of this repo just tweet me @tofran_ and I’ll do it as soon as possible.
When you access your Gyazo folder (history, visits, etc.) multiple JSON files are retrieved to display the thumbnails and links. Each file is an array of the images properties, like this:
{
"image_id" : "4bc7e1d25f5cf1fd8d2dcc85f92f81e8",
"created_at" : "2015-07-12T17:49:58.719Z",
"file_size" : 10490,
"alias_id" : "_0ad075f720bb959097d7b27259dacb41",
"deletable" : true,
"editable" : true,
"drawable" : false,
"metadata" : {"title" : "","url" : "","app" : ""},
"desc" : null,
"has_mp4" : false,
"url" : "https://i.gyazo.com/4bc7e1d25f5cf1fd8d2dcc85f92f81e8.png",
"thumb_url" : "http://i.gyazo.com/thumb/200/_0ad075f720bb959097d7b27259dacb41.png",
"crop_thumb_url" : "http://i.gyazo.com/thumb/22_crop/_0ad075f720bb959097d7b27259dacb41.png",
"large_thumb_url" : "http://i.gyazo.com/thumb/360/_0ad075f720bb959097d7b27259dacb41.png",
"search_thumb_url" : "http://i.gyazo.com/thumb/100_crop/_0ad075f720bb959097d7b27259dacb41.png",
"cover_url" : "http://i.gyazo.com/cover/4bc7e1d25f5cf1fd8d2dcc85f92f81e8.png",
"permalink_url" : "http://gyazo.com/4bc7e1d25f5cf1fd8d2dcc85f92f81e8",
"permalink_path" : "/4bc7e1d25f5cf1fd8d2dcc85f92f81e8"
},when you don't have permission to access the image, the key "image_id" returns empty, but "url","permalink_url" and "permalink_path" still have their original value :/
- Requests - Python HTTP Requests for Humans
- From py: multiprocessing, Thread, Queue, urllib, json