Phi3 benchmarks #140
Phi3 benchmarks #140
Conversation
| @@ -228,7 +228,7 @@ void MkFinder::SelectHitIndices(const LayerOfHits &layer_of_hits, | |||
| } | |||
|
|
|||
| dphi = std::min(std::abs(dphi), L.max_dphi()); | |||
| dq = std::min(std::max(dq, L.min_dq()), L.max_dq()); | |||
| dq = clamp(dq, L.min_dq(), L.max_dq()); | |||
There was a problem hiding this comment.
The system standard C++ headers (which icc uses) don't have C++14 support, so we do this:
https://github.com/cerati/mictest/blob/ddcfafe88892c088cd8dcde8330270714abefd1f/Matrix.h#L51
to pick between using std::clamp; or a local implementation. If we installed devtoolset-4 or later and used the headers from that we could probably do std::clamp.
| maxvu=16 | ||
| exe="./mkFit/mkFit ${seeds} --input-file ${dir}/${subdir}/${file}" | ||
| declare -a nths=("1" "2" "4" "8" "16" "32" "48") | ||
| declare -a nths=("1" "2" "4" "8" "16" "32" "64") |
There was a problem hiding this comment.
do we want to add 48 here?
| declare -a nvus=("1" "2" "4" "8" "16") | ||
| declare -a nevs=("1" "2" "4" "8" "16" "32") | ||
| declare -a nevs=("1" "2" "4" "8" "16" "32" "64") |
There was a problem hiding this comment.
I guess this results in a single point plotted?
There was a problem hiding this comment.
It should, but:

I missed updating setupEvents...
| gSystem->SetMakeExe(o.Data()); | ||
| } | ||
| #include "PlotBenchmarks.hh" | ||
| #include "PlotBenchmarks.cpp" |
There was a problem hiding this comment.
I would still like to keep these compilable.
to do so, the modifications needed are:
#include "Common.hh+"
#include "PlotBenchmarks.cpp+"
and then add header guards in Common.hh
(and then the same for all the .C files)
| gSystem->SetMakeExe(o.Data()); | ||
| } | ||
| #include "PlotMEIFBenchmarks.hh" | ||
| #include "PlotMEIFBenchmarks.cpp" |
There was a problem hiding this comment.
same comment as makeBenchmarkPlots.C
| gSystem->SetMakeExe(o.Data()); | ||
| } | ||
| #include "PlotsFromDump.hh" | ||
| #include "PlotsFromDump.cpp" |
There was a problem hiding this comment.
same comment as makeBenchmarkPlots.C
| gSystem->SetMakeExe(o.Data()); | ||
| } | ||
| #include "StackValidation.hh" | ||
| #include "StackValidation.cpp" |
There was a problem hiding this comment.
same comment as makeBenchmarkPlots.C
| gSystem->SetMakeExe(o.Data()); | ||
| } | ||
| #include "PlotValidation.hh" | ||
| #include "PlotValidation.cpp" |
There was a problem hiding this comment.
same comment as makeBenchmarkPlots.C
| cd ${SNB_WORKDIR}/${SNB_TEMPDIR} | ||
| tar -zxvf ${repo} | ||
| rm ${repo} | ||
| '" |
There was a problem hiding this comment.
maybe pedantic, but should we add an "exit" here (and same with the tarAndSendToKNL.sh)?
|
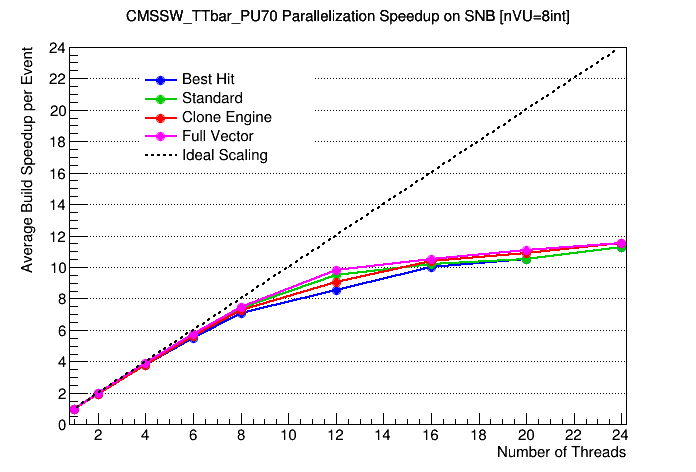
First off: thank you Dan for porting the validation to phi3! Working with ROOT6 is much nicer, and as you pointed out, removes a lot the hacks. Running the validation on phi3 should significantly speed things up (in addition the changes from my last PR). Also, now that phi3 is our "standard" platform, thank you for updating all the scripts as necessary. I like keeping SNB around for now since the scalability is easier to understand (and since the benchmarking is fairly quick). I have a number of comments that while don't have to be addressed in this PR, should be done in a follow-up PR (which I can volunteer to do):
|
|
I suspect that -xHost does not include -qopt-zmm-usage=high which has improved performance up to 2x with some of my simple test codes on Skylakes. It would be interesting to re-run the benchmarks with this option present to see if it makes any difference. I see it is present but commented out in the current Makefile.config. |
|
@srlantz qopt-zmm-usage high helps by ~10%, from
to
It does make the vector speedup look a lot more like KNL, which is good:
I'd have to check what it does on KNL before committing. |



|
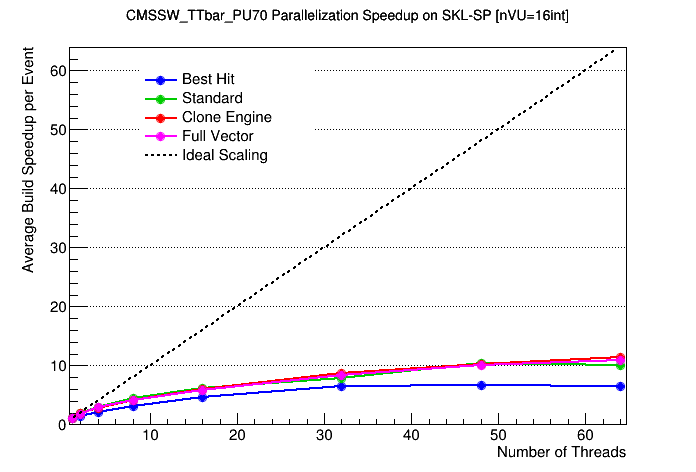
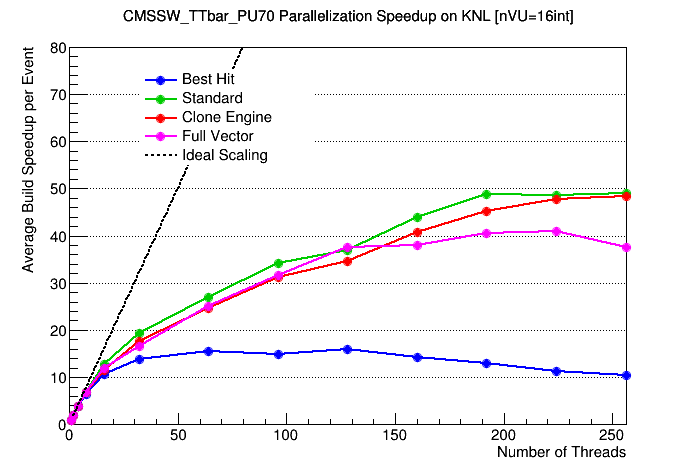
This is great! I am glad we solved the issue of the number of hits with VU=16 and improved the VU scaling for SKL.
Do you guys have a clue why the TH scaling is still far from what we see both with SNB and KNL?
https://www.classe.cornell.edu/~dsr/mic-track/PR140/Benchmarks/SKL-SP_CMSSW_TTbar_PU70_TH_speedup.png
https://www.classe.cornell.edu/~dsr/mic-track/PR140/Benchmarks/KNL_CMSSW_TTbar_PU70_TH_speedup.png
https://www.classe.cornell.edu/~dsr/mic-track/PR140/Benchmarks/SNB_CMSSW_TTbar_PU70_TH_speedup.png
Thanks.
…________________________________________
From: Dan Riley <notifications@github.com>
Sent: Wednesday, May 9, 2018 9:45:47 AM
To: cerati/mictest
Cc: Subscribed
Subject: Re: [cerati/mictest] Phi3 benchmarks (#140)
@srlantz<https://github.com/srlantz> qopt-zmm-usage high helps by ~10%, from
[image]<https://user-images.githubusercontent.com/1799196/39821171-a38a9930-5375-11e8-9194-3153f73d8987.png>
to
[skl-sp_cmssw_ttbar_pu70_th_time_logx]<https://user-images.githubusercontent.com/1799196/39821182-a6f9fe94-5375-11e8-8774-2e9d8d26078c.png>
It does make the vector speedup look a lot more like KNL, which is good:
[skl-sp_cmssw_ttbar_pu70_vu_speedup]<https://user-images.githubusercontent.com/1799196/39821211-bb87c35a-5375-11e8-86e5-f14b7d53c397.png>
I'd have to check what it does on KNL before committing.
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub<#140 (comment)>, or mute the thread<https://github.com/notifications/unsubscribe-auth/AEmGGrxTJ7Lc9vUymY6Ny8XbWlHciloAks5twwEbgaJpZM4T3kCE>.
|
{kind=link}
{kind=link}
{kind=link}
|
Perhaps turboboost and the downscaling of base frequency based on instruction set vs nTH @srlantz was discussing before? Most likely, we need to adjust the ideal scaling line or normalize each point we plot to the "expected" speedup based on the frequency downscaling. |
|
@dan131riley The -qopt-zmm-usage option is ignored on MIC architectures such as KNL. See the icc man page. This option is only relevant for non-MIC, AVX-512 chips, so actually it is ignored on all the current architecture specifications except COMMON-AVX512 and CORE-AVX512. Therefore, including it in the icc compile line for KNL should be a no-op. @kmcdermo Yes, it is possible that we are seeing the effects of dynamic frequency scaling on SKL-SP. I should put together a PR where I graft in John McCalpin's frequency-measuring routines so we can get a handle on how important that might be. If that is indeed what we're seeing, then the main effect would be to get unexpectedly GOOD performance for low thread counts due to Turbo Boost. This of course messes up the baseline for the traditional scaling plots. One way to mitigate against it would be to normalize each point by the average frequency for that run. (I don't recommend turning off frequency scaling for benchmarks. It takes sudo privileges, and it just slows everything down.) |
|
phi3 has the intel_powerclamp driver loaded, which I believe is responsible for the software side of frequency scaling. Using lnx4108 does not have the powerclamp driver, and /proc/cpuinfo and |
|
@dan131riley That would explain some of the other oddities I have witnessed on lnx4108, e.g., the /sys/devices/system/cpu/cpu*/cpufreq directories are entirely missing, and some of the microbenchmarks have given me results that appeared to be independent of core count. On phi3, I certainly do observe frequency scaling. On phi3, the file /sys/devices/system/cpu/cpu0/cpufreq/scaling_driver reports intel_pstate, not intel_powerclamp. Is that the same thing? Where are you looking to determine the driver name? We have complementary sudo rights: I have it on phi3, you have it on lnx4108. So on phi3, |
|
lnx4108 has both ACPI supported and power/performance control, but 'cpupower frequency-info' says 'no or unknown cpufreq driver is active on this CPU' and gives no clock info, phi3 says intel_pstate. Still figuring out what the different drivers do, intel_powerclamp comes from 'lsmod' |
|
It looks like lnx4108 (Cornell Ag) has clock management turned off in the BIOS, so there's no cpufreq driver loaded or possible. This explains my slides from last week, which showed that lnx4108 had approximately half the single-cpu performance as phi3 but scaled twice as well. lnx4108 shows the performance without clock management, while on phi3 the single-cpu performance is inflated by turbo-boost, which makes the scaling look a lot worse. |
This PR
Benchmarks and validation: https://www.classe.cornell.edu/~dsr/mic-track/PR140/