

Documentation is being maintained on the Wiki for this project. Visit Kubeturbo Wiki for the full documentation, examples and guides.
Kubeturbo leverages Turbonomic's patented analysis engine to provide observability WITH control across the entire stack in order to assure the performance of running micro-services on Kubernetes platforms, as well as driving efficiency of underlying infrastructure. You work hard. Let software make automated resources decisions so you can focus on on-boarding more performant applications.
Use cases and More:
- Full Stack Management
- Intelligent SLO Scaling
- Proactive Rescheduling
- What's New
- Supported Platforms
Starts with Full-Stack Visibility by leveraging 50+ existing Turbonomic controllers, from on-prem DataCenter to major public cloud providers. No more shadow IT
- From the Business Application all the way down to your physical Infrastructure
- Continuous Real-Time resource management across entire DataCenter
- Cost optimization for your public cloud deployment
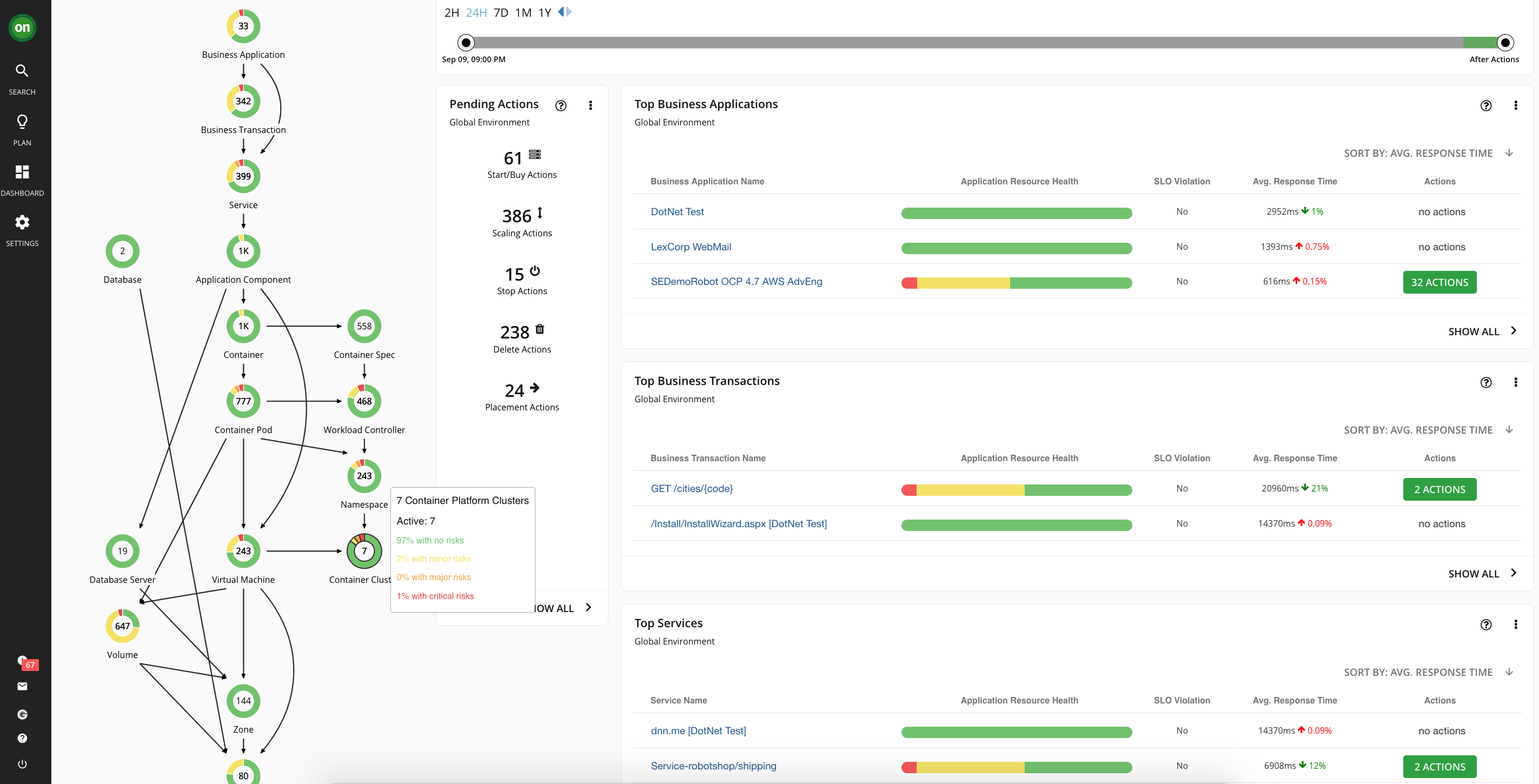
Manage the Trade-offs of Performance and Efficiency with Intelligent Vertical and Horizontal scaling that understands the entire IT stack
- Combining Turbonomic real-time performance monitoring and analysis engine, Turbonomic is able to provide right-sizing and scaling decisions for each service as well as the entire IT stack.
- Scale services based on SLO and simultaneously managed cluster resources to mitigate pending pods
- Right-sizing up your Pod limit to avoid OOM and address CPU Throttling
- Right-sizing down your Pod requested resource to avoid resource over-provisioning or overspending in public cloud deployment.
- Intelligently scale your nodes based on usage, requests, not just pod pending conditions
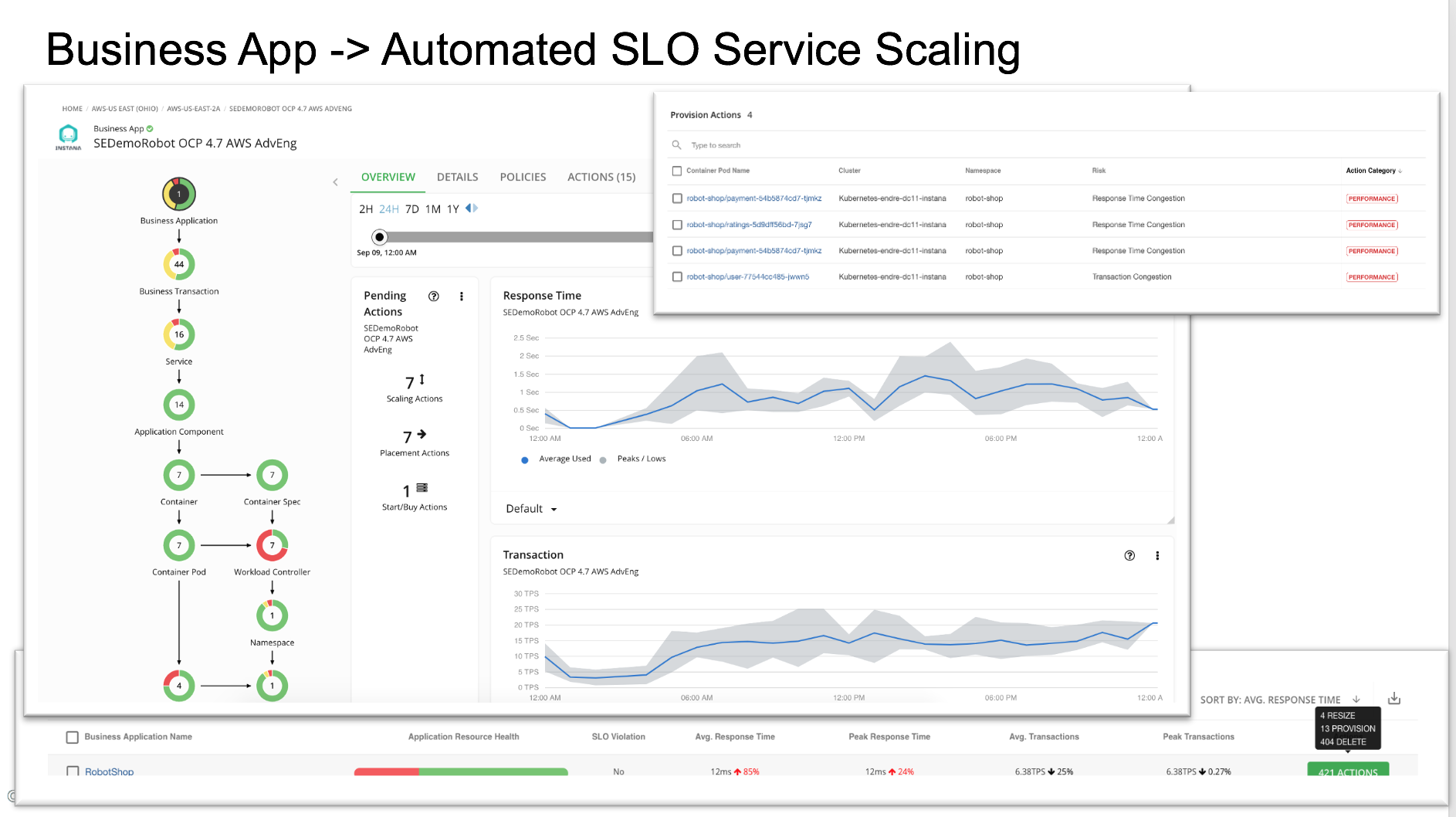
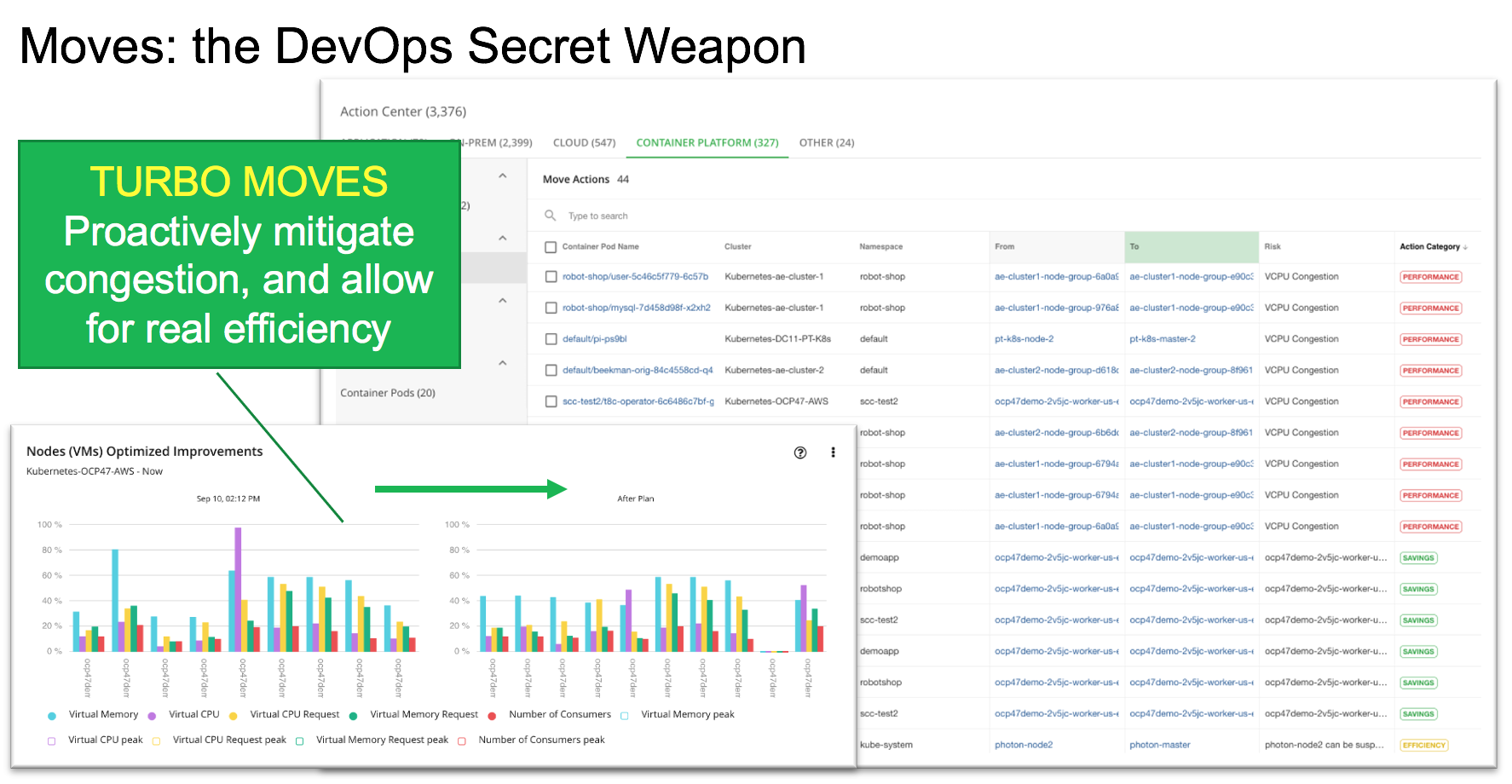
Intelligently, continuously redistribute workload under changing conditions by leveraging The Turbonomic analysis engine
- Consolidate Pods in real-time to increase node efficiency
- Reschedule Pod to prevent performance degradation due to resource congestion from the underlying node
- Redistribute Pods to leverage resources when new node capacity comes on line
- Reschedule Pods that peak together to different nodes, to avoid performance issues due to "noisy neighbors"
With the release of 8.3.1, we are pleased to announce
- CPU Throttling Turbonomic can now recommend increasing vCPU limit capacity to address slow response times associated with CPU throttling. As throttling drops and performance improves, it analyzes throttling data holistically to ensure that a subsequent action to decrease capacity will not result in throttling.
- Power10 Support KubeTurbo now supports Kubernetes clusters that run on Linux ppc64le (including Power10) architectures. Select the architecture you want from the public Docker Hub repo starting with KubeTurbo image 8.3.1, at turbonomic/kubeturbo:8.3.1. To deploy Kubeturbo via Operator, use the Operator image at turbonomic/kubeturbo-operator:8.3. Note that KubeTurbo deployed via the OpenShift Operator Hub currently only supports x86.
Any upstream compliant Kubernetes distribution, starting with v1.8+ to current GA
