网上有一些中文语料库,但是居然都不是自动更新的。
是可忍,孰不可忍。我想自动挖掘研究市场热点炒股票,没有新数据搞毛线。
于是,有了这个项目 : 《中文语料库-每日自动更新版》 。
核心思想,通过RSS订阅,存档内容。
然后通过GitHub Actions来实现每日运行,这样就实现了一个无服务器的自动更新语料库。
Github仓库有1GB容量的限制,但热度高的项目能申请更多存储空间。
为了避免空间不足导致语料库无法更新,请大家给语料仓库多多加星。
- 语料仓库 : github.com/txtcn/data
- 爬虫仓库 : github.com/txtcn/dump
为了节约空间,历史语料被打包发布到了 github release ,克隆语料仓库后,首先运行 ./init.sh 导入历史语料。
- 知乎每日精选 👉 语料库
- 知乎日报 👉 语料库
- 游研社 👉 语料库
- 虎嗅 👉 语料库
- 好奇心日报 👉 语料库
- 少数派 👉 语料库
- 小众软件 👉 语料库
- 超能网 👉 语料库
- 爱范儿 👉 语料库
- 极客公园 👉 语料库
- 理想生活实验室 👉 语料库
- 科学松鼠会 👉 语料库
- PanSci 泛科学 👉 语料库
- 人人都是产品经理 👉 语料库
- 优设网 – UISDC 👉 语料库
欢迎大家共享有价值的RSS源。如何添加新的RSS内容源呢?流程如下:
- 找到高质量全文输出的RSS
- 参考 rss/zhihu-daily.coffee、rss/williamlong.info.coffee、rss/solidot.org.coffee 创建一个文件
- 修改 dump/README.md,在上面添加新源的介绍。
- 提交代码合并请求
以下RSS有问题,暂不收录
- 36氪 会随机把少数字符替换为乱码
以 data/ruanyifeng.com 为例
- rss.yml 有
rss的元信息 - 以数字为名称的文件,这里是内容存档,文件名含义是
int(时间戳/86400)
- 第一行 : ➜标题
- 第二行 : 链接链接 时间(中间的分隔符是TAB)
- 之后的行 : 正文的HMTL (直到出现下一个➜)
示例如下 :
➜标题
链接 时间
正文
标题、内容中的 ➜ 都被替换为了 ➔ (这两个箭头不是同一个字符),TAB都被替换为了空格,所以解析的时候直接split即可。
文件名为日期 : 日期 = 取整(时间戳/86400)
文档中时间为 : 时间戳秒数减去当日零点的秒数
实际时间戳 = 文件名*86400 + 文档中第二行的时间
文本解析的代码可以参考这里
上面存档的正文是HTML,但往往搞挖掘需要的是纯文本。
语料仓库自带了纯文本抽取工具。
进入data 目录,首先用python3的pip运行(有些系统是pip3)
pip install -r requirements.txt
然后运行 ./extract.py 输出路径
运行后输出一堆类似 知乎日报.zd 的文件。
.zd文件是Zstandard压缩后的纯文本文件 ( 参见 Zstandard - Real-time data compression algorithm )
使用 zdcat 命令可以查看, 比如:
zdcat /share/txt/data/ifanr.com.zd
运行后可以看到正文,文档格式和上文一致(时间戳被还原为绝对时间)。
在程序中读取zd文件,可用如下方法。
import zd
with zd.open(
"/share/wiki/zhwiki-20200701-pages-articles.txt.zd"
) as f:
for i in f:
print(i)
zd的python依赖可以单独安装,如:pip install zd,zdcat会随着zd附带安装。
zd项目的源码见gitee.com/znlp/zd
ubuntu 用户也可以安装 zstd软件包,然后用 zstdcat 、unzstd 等命令。
1. 从维基百科抽取中文语料
2. 谷歌浏览器实用插件:六度空间 · 短链接
可以生成短链接(短网址)、二维码,一键复制标题和链接。
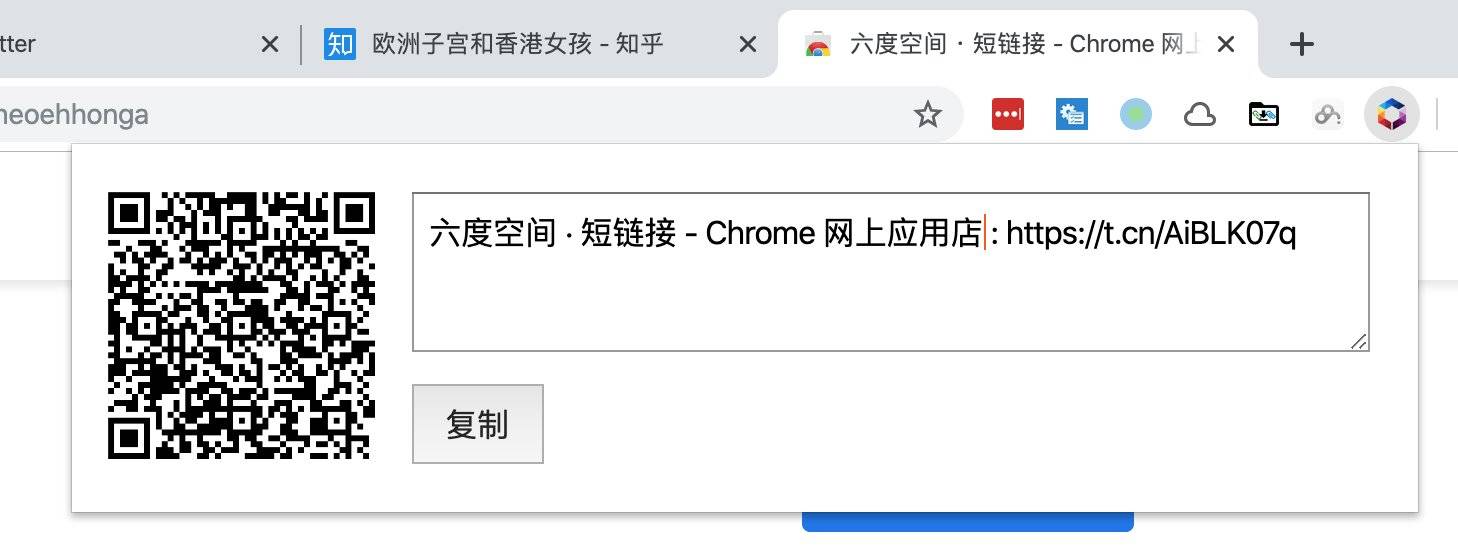
现有的chrome插件,没有一个能自动复制并带上标题的,所以自己写了一个,很实用,欢迎试用。
安装地址:Chrome 网上应用店
如果没法访问Chrome网上应用店,可以按照以下步骤安装。
点击这里下载源码 ,并解压
在Chrome浏览器中输入 chrome://extensions ,并开启开发者模式(点击右上角)
点击「加载已解压的扩展程序」选择刚刚解压的目录。
这是开源项目,欢迎参与改进。
张沈鹏,欢迎扫码关注我的微信公众号。
