- Design a Gorcery/Food Delvery Application
- Geo-Proxmity Search / Spatial Search
- Design a Flash Sale System
- Design a Search Engine
- Design a Parking Lot System
- Design a Rate Limiter
- Design a Vending Machine
- Design a Ride Share Applicaiton
- Design a Distributed Job Schedular
- Design a Payments System
- Design a Video Streaming Service
- Design a Typeahead Search
- Design a Chat Service
- How to Scan a Malware?
- Design a Voting System
- Design a Finate State Machine
- Design a Elevator
- Design a TinyURL Service
- Design a LRU Cache & LFU Cache
Design Concepts
- Identity sub-system components that make up a solution - functional modules, services, APIs, ...
- Identify Data Structures & Algorithms
- Identify Design Methdolgoies & Tradeoffs - Pub/Sub, Microservices, Read-Write Heavy, DDD, SOLID Princples, CAP Therom, ...
- 4 + 1 views - Functional Architecture, Layered Technical Architecture, Deployment Architecture, Security Architecture, ...
- Make technology choices - Polyglot Databases, Frameworks, Libraries, ...
What happens when you type amazon com or www google com in the browser?
System design approaches for apps such as DoorDash, Dunzo, Zomato, Swiggy, Blinkit and more ...
- DoorDash System Design
- Architecture and Design Principles for Online Food Delivery System
- Yelp System Design
- Vehicle Routing Problem - Google OR Tools & Vehicle Routing Problem - OptaPlanner
Geospatial Data
Geospatial data records geographical location. Usually 4 geometry are used to store geographic data,
- Point: A single position on earth
- Line: A set of points that connect
- Polygon: A set of points representing a boundary of the specific area
- Multi-Polygon: A collection of polygons that share the same properties
Spatial Partitioning + Indexing
Indexing geospatial data is trickier since it has 2 dimensions: x and y. It requires a different indexing methodology.
Geo Spatial indices are a family of algorithms that arrange geometric data for efficient search to answer roximity queries such as,
- Find 1000 closest gas stations to this point?
- How many users are nearby?
Geohash is a geospatial indexing algorithm that encodes any geo location to a text by splitting the world into an equal-sized unit called cell(or grid) where each has a specific hash assigned to it.
- It converts geographic information into an alphanumeric hash.
- A geohash is used to identify a rectangular area around a fixed point.
- The length of the hash determines the precision of the area identified.
- This allows you to use a hierarchical search where the length of the geohash corresponds to the size of a search area.
- It provides a way to shard a large data set into buckets based on a zoomed-in level. Entities in the same bucket are in close proximity.
Finding neighbours
As each character encodes additional precision, shared prefixes denote geographic proximity.
A quadtree is a tree data structure in which each node has zero or four children. It recursively divides a flat 2-D space into four quadrants.
A space-filling curve is a line that is bent around in a predetermined fashion until it fills a 2-dimensional plane. This is a way to convert a given 2-D space into a 1-D continuous line which allows simple and efficient geospatial queries, enabling you to assign 1d numbers to objects. This consequently converts the proximity 2d search problem into the simple 1d search.
Once objects are sorted into this ordering, any one-dimensional data structure can be used, such as binary search trees, B-trees and Hash Tables.
Google S2 curve is based on Hilbert curve, a continuous fractal space-filling curve. S2 uses the Hilbert Curve to enumerate the cells, this means that cell values close in value are also spatially close to each other.
Best usage of Google S2, https://gis.stackexchange.com/questions/236508/understanding-the-s2-library-geometry-on-the-sphere-cells-and-hilbert-curve-f
Uber H3 is a geospatial indexing system using a hexagonal grid that can be (approximately) subdivided into finer and finer hexagonal grids, combining the benefits of a hexagonal grid with S2’s hierarchical subdivisions.
- Uber H3 enables users to partition the globe into hexagons for more accurate analysis.
- H3 exposes functions that permit moving between resolutions in the H3 grid system. The functions produce parent (coarser) or children (finer) cells. You can determine surronding H3 cells and find nearby objects by key, which would be the encoded H3 cell string of the location at a given resolution.
Data stores
- Elastic Search: supports multiple geo query capabilities and has a Geo Point field type. geo_distance query for example finds documents with geopoints within the specified distance of a central point.
- MongoDB: allows you to store geospatial data as GeoJSON points and supports geospatial query operations.
- PostgreSQL + PostGIS: PostGIS is a spatial database extender for the PostgreSQL database. PostGIS adds support for geo-location allowing geospatial SQL-based queries.
References
- Geo Spatial Notes
- Typeahead + Proximity Search at Nextdoor
- Find Restaurants with Geospatial Queries - MongoDB
- Geo-Proximity Search — 5 Approaches
- Handle write heavy traffic & high concurrency
- Avoid overselling inventory
- Multiple requests from same user (different browser sessions)### Data Structures & Algorithms
| Article / Blog | Notes | |
|---|---|---|
| ⭐⭐ | Flash Sale | |
| ⭐ | Flash Sale | |
| ⭐ | Flash Sale Engineering |
- very low-latency and high-throughput
- Replacing all your queues with the magic ring buffer.
LMAX Disruptor:
- https://code.google.com/archive/p/disruptor/wikis/BlogsAndArticles.wiki
- https://lmax-exchange.github.io/disruptor/
Matching Engine:
| Article / Blog | Notes | |
|---|---|---|
| ⭐ | Design a Search Engine |
| Article / Blog | Notes | |
|---|---|---|
| ⭐⭐⭐ | Design a Parking Lot System |
| Article / Blog | Notes | |
|---|---|---|
| ⭐ | Rate limiter | |
| ⭐⭐ | Introduction to rate limiting with Redis [Part 2] | |
| ⭐⭐ | Figma - An alternative approach to rate limiting | |
| ⭐ | Kong - How to Design a Scalable Rate Limiting Algorithm |
- Quadtrees are a data structure that encode a two-dimensional space into adaptable cells. quadtrees are a tree structure where every non-leaf node has exactly four children. In the context of location, these nodes represent the four quadrants: NW, NE, SW, and SE.
- Google S2 library (which uses a quadtree data structure). This library divides the map data into tiny cells (for example 2km) and gives the unique ID to each cell. Suppose you want to figure out all the cabs available within a 2km radius of a city. Using the S2 libraries you can draw a circle of 2km radius and it will filter out all the cells with IDs lies in that particular circle. This way you can easily match the rider to the driver and you can easily find out the number of cab available in a particular region.
- Uber's H3 algorithm partitions the Earth’s surface into a network of hexagons. You can select the amount of detail each hexagon contains by choosing among the available sixteen levels. You can think of these as “zoom” levels on a map. Each hexagon is unique and is identifiable through a unique sixty-four-bit identifier, an ideal key for a database table, or an in-memory dictionary. These identifiers are consistent across “zoom” levels, so you can mix and match them as you please.
The QuadKeys in leaf nodes has reference to SortedSet in Redis, where drivers information is stored by priority (rating, distance?)
Driver Location Hash Table - Stores DriveID in the hash table along with driver’s current and previous location. Distribute DriverLocation HT on multiple servers based on the DriverID. This will help with scalability, performance, and fault tolerance. We will refer to the this information as the Driver Location servers.
- Server will also notify the respective QuadTree server to refresh the driver’s location.
- Once server receives an update on a driver’s location, it will broadcast that information to relevant customers.
Update data structures to reflect active drivers’ reported locations every three seconds. To update a driver to a new location, we must find the right grid based on the driver’s previous location. If the new position doesn’t belong to the current grid, we remove the driver from the current grid and reinsert them to the right grid. If the new grid reaches a maximum limit, we have to repartition it. We need a quick mechanism to propagate the current location of nearby drivers to customers in the area. Our system needs to notify both the driver and customer on the car’s location throughout the ride’s duration.
When a customer opens the Uber app, they’ll query the server to find nearby drivers. On the server side, we subscribe the customer to all updates from nearby drivers. Each update in a driver’s location in DriverLocation HT will be broadcast to all subscribed customers. This ensures that each driver’s current location is displayed.
Customers will send their current location so that the server can find nearby drivers from our QuadTree.
We’ve assumed one million active customers and 500 thousand active drivers per day. Let’s assume that five customers subscribe to one driver. We’ll store this information in a hash table for quick updates.
How to schedule millions of jobs?
- On single computer, Sorted Set + HashMap + Multiprocessing Queues
- Must be disttibued for scaling, ...
| Article / Blog | Notes | |
|---|---|---|
| ⭐ | System Design — Distributed Job Scheduler | |
| ⭐ | A design for large-scale job schedulers |
-
Relaibility with high throughput
-
Payment processing should be idempotent and crash-tolerant
-
Resiliencey when service crash
-
Charged once and exactly once.
-
ront-end service accepts a user’s payment request. The first order of business is to set up a record in a database
-
front-end service also puts a message on the payment queue
-
Centralized Orchestrator like Netflix Conducutor.
| Article / Blog | Notes | |
|---|---|---|
| ⭐ | Design payments system like Google Pay or PayTM | |
| ⭐ | System design practice: designing a payment system |
| Article / Blog | Notes | |
|---|---|---|
| ⭐ | Design a video streaming service |
| Article / Blog | Notes | |
|---|---|---|
| ⭐ | Design a Chat Service - Whatsapp Architecture |
| Article / Blog | Notes | |
|---|---|---|
| ⭐ | Design a service to scan photos/videos for any malware? |
| Article / Blog | Notes | |
|---|---|---|
| ⭐ | Design a voting system |
| Article / Blog | Notes | |
|---|---|---|
| ⭐ | Elevator System Design |
For given URL, generate a 6 or 7 character short unique key.
- Use MD5 hash algorithm, produces 128-bit hash value. After base64 encoding results a string having more than 21 characters. Choosing first or last 6 characters cause duplicate keys.
-
Step 1: Generate random six-letter strings beforehand and stores them in a database.
Unique Key Generation - leverage Twitter Snowflake to generate the roughly-sorted 64 bit ids in an uncoordinated manner through compostion of timestamp + worker number + sequence number.
- Sequence numbers are per-thread
- Worker numbers are chosen at startup via zookeeper (though that’s overridable via a config file).
Source: Twitter Snowflake
-
Step 2: Concurrency: As soon as a key is used, it should be marked in the database to ensure that it is not used again.
-
Step 3: Use two tables to store keys: one for keys that are not used yet, and one for all the used keys.
-
Step 4: Keep some keys in memory to quickly provide them whenever a server needs them.
-
Step 5: Loads some keys in memory, it can move them to the used keys table. This ensures each server gets unique keys.
Twitter is read-heavy
Publishing is the step where the feed data is pushed according to each specific user. This can be a quite heavy operation, as a user may have millions of friends or followers. To deal with this, we have three different approaches:
When a user creates a tweet, and a follower reloads their newsfeed, the feed is created and stored in memory.
In this model, once a user creates a tweet, it is "pushed" to all the follower's feeds immediately. This prevents the system from having to go through a user's entire followers list to check for updates.
Hybrid model allows only users with a lesser number of followers to use the push model and for users with a higher number of followers celebrities, the pull model will be used.
- Fanout approach for writes
- Do a lot of processing when tweets arrive to figure out where tweets should go. This makes read time access fast and easy. Don’t do any computation on reads.
https://systemdesigntutorial.com/design-twitter/
Partitioning of relational data, usually refers to decomposing your tables either row-wise (horizontally) or column-wise (vertically).
- Vertical partitioning: means some columns are moved to new tables. Each table contains the same number of rows but fewer columns.
- Horizontal partitioning (often called sharding): Divides a table into multiple smaller tables. Each table is a separate data store, and it contains the same number of columns, but fewer rows.
Two attributes of an effective shard key are,
-
high cardinality
-
and well-distributed frequency.
-
Cardinality describes number of possible values of the shard key. For example, if the database designer chooses a yes/no data field as a shard key, the number of shards is restricted to two.
-
Frequency refers to the distribution of the data along the possible values. It is the probability of storing specific information in a particular shard. For example, a database designer chooses age as a shard key for a fitness website. Most of the records might go into nodes for subscribers aged 30–45 and result in database hotspots.
Cassandra is often used for time series data, and hotspotting can be a real issue. Breaking incoming data into buckets by year:month:day:hour, using four columns to route to a partition can decrease hotspots.
The routing algorithm decides which partition (shard) stores the data,
-
Range Based Partitioning: This algorithm uses ordered columns, such as integers, longs, timestamps, to separate the rows. For example, the diagram below uses the User ID column for range partition: User IDs 1 and 2 are in shard 1, User IDs 3 and 4 are in shard 2.
-
Hash-based sharding: This algorithm applies a hash function to one column or several columns to decide which row goes to which table. For example, the diagram below uses User ID mod 2 as a hash function. User IDs 1 and 3 are in shard 1, User IDs 2 and 4 are in shard 2.
-
Geo-Hashing converts geographic information into an alphanumeric hash
- The length of the hash determines the precision of the area identified. This allows you to use a hierarchical search where the length of the geohash corresponds to the size of a search area.
- Efficient Proximity queries such as “How far is the nearest business?” or “How many users are nearby?”
Difference between Clustered and Non-clustered Index
- A cluster index is a type of index that sorts the data rows in the table on their key values, whereas the Non-clustered index stores the data at one location and indices at another location.
- Clustered index stores data pages in the leaf nodes of the index, while the Non-clustered index method never stores data pages in the leaf nodes of the index.
- The cluster index doesn’t require additional disk space, whereas the Non-clustered index requires additional disk space.
- Cluster index offers faster data access, on the other hand, the Non-clustered index is slower.
Difference between Clustered and Non-clustered Index
LRU Cache
LRU cache implemented using a combination of the DoublyLinkedList and the HashMap as shown below:
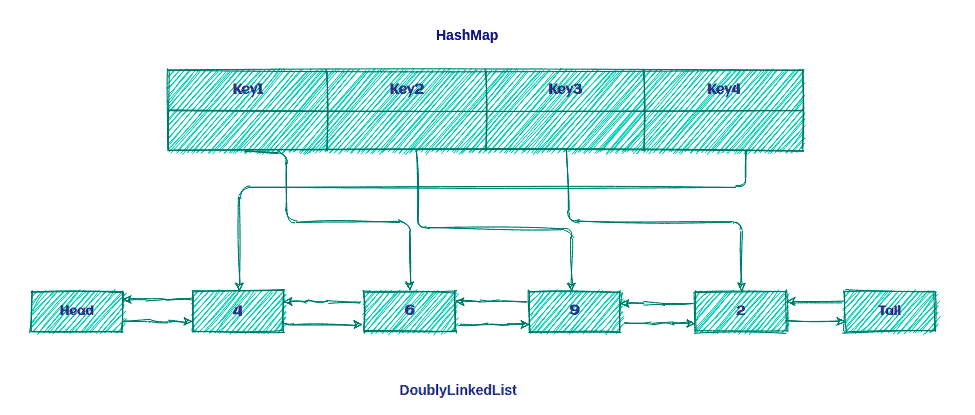
LFU Cache
A dtributed hash table (a large hash tables across multipe servers) is subject to rehashing problems.
Rehashing Problem: Keys need to be redistributed when a server crashes or new server added. This is true for any distribution scheme, including simple modulo distribution scheme hashes modulo N. Most keys will need to be moved to a different server. So, even if a single server is removed or added, all keys will likely need to be rehashed into a different server.
Consistent Hashing is a distribution scheme that does not depend directly on the number of servers, so that, when adding or removing servers, the number of keys that need to be relocated is minimized.
Consistent hashing is a distributed systems technique that operates by assigning the data objects and nodes a position on a virtual ring structure (hash ring). Consistent hashing minimizes the number of keys to be remapped when the total number of nodes changes.
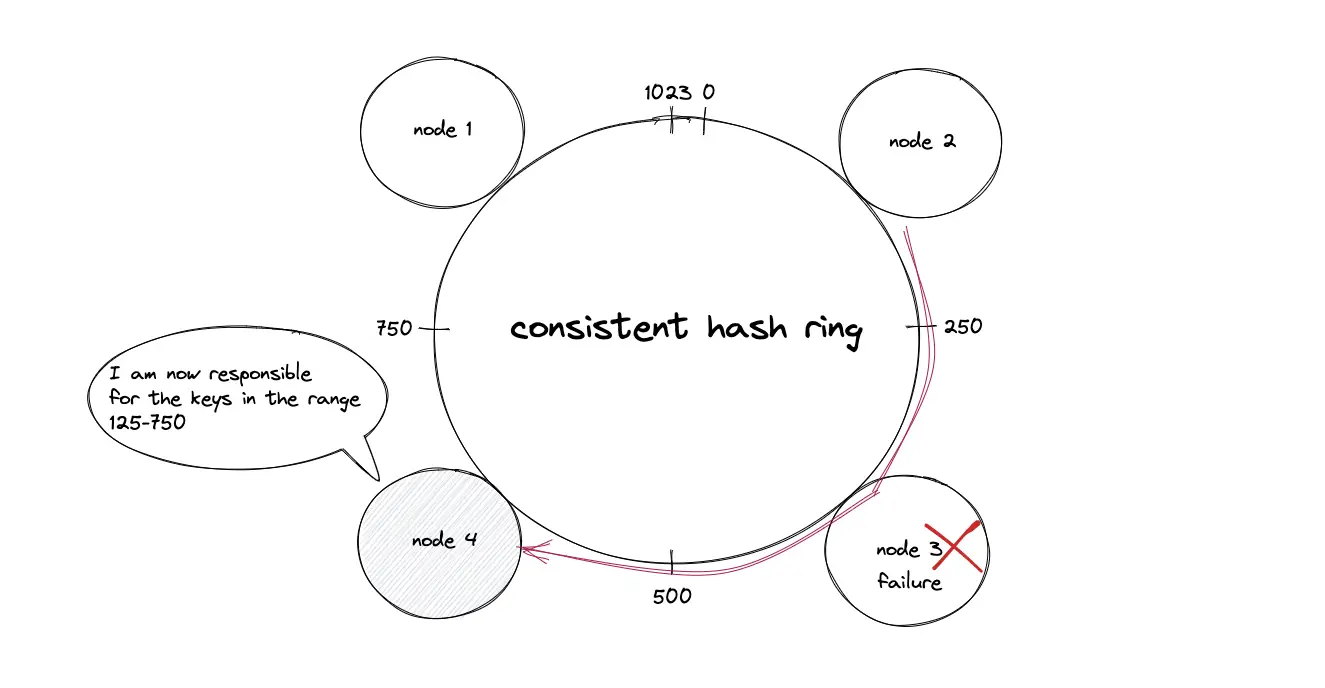
The failure (crash) of a node results in the movement of data objects from the failed node to the immediate neighboring node in the clockwise direction. The remaining nodes on the hash ring are unaffected