- pdfkit is a python library that can be used to generate PDF documents from HTML content easily and with automated flow control such as pagination and keeping text together. It uses wkhtmltopdf as a backend and can be used with Flask or Django to convert HTML to PDF in web applications.
-
Download library pdfkit:
$ pip install pdfkit (or pip3 for python3) -
Install wkhtmltopdf:
-
Debian/Ubuntu:
$ sudo apt-get install wkhtmltopdf -
For Windows:
(a) Download link: wkhtmltopdf
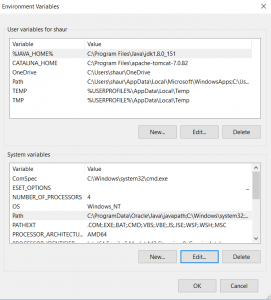
(b)Set: PATH variable set binary folder in Environment variables.
-
Warning! Version in debian/ubuntu repos have reduced functionality (because it compiled without the wkhtmltopdf QT patches), such as adding outlines, headers, footers, TOC etc. To use this options you should install static binary from wkhtmltopdf site.
- Windows and other options: check wkhtmltopdf homepage for binary installers
(i) if you have html file already saved on your system:
import pdfkit
pdfkit.from_file('test.html', 'out.pdf')
(ii) if you have any website URl; which needs to be converted:
import pdfkit
pdfkit.from_url('http://google.com', 'out.pdf')
(iii) if you have series of string in the codes; which needs to be shown in the form of PDF:
import pdfkit
pdfkit.from_string('Hello!', 'out.pdf')
Configuration
Each API call takes an optional configuration parameter. This should be an instance of pdfkit.configuration() API call. It takes the configuration options as initial parameters. The available options are:
-
wkhtmltopdf- the location of thewkhtmltopdfbinary. By defaultpdfkitwill attempt to locate this usingwhich(on UNIX type systems) orwhere(on Windows). -
meta_tag_prefix- the prefix forpdfkitspecific meta tags - by default this ispdfkit-
Example - for when wkhtmltopdf is on $PATH:
path_to_wkhtmltopdf = r"C:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe"
config = pdfkit.configuration(wkhtmltopdf=path_to_wkhtmltopdf)
pdfkit.from_file(html_string, output_file, configuration=config)

Example - for when wkhtmltopdf is not on $PATH:

Also you can use configuration() call to check if wkhtmltopdf is present in $PATH:
try:
config = pdfkit.configuration()
pdfkit.from_string(html_string, output_file)
except OSError:
# not present in PATH
API data segregation typically involves extracting relevant information from an API response and organizing it into a format that can be easily used and displayed by an application. This may involve filtering, sorting, or manipulating the data in some way.Once the data has been segregated, it can be sent to HTML using variety of techniques


The html on django templates

Matplotlib pie charts are used to display data in a circular graph, where the size of each slice represents the proportion of the whole. They are commonly used to visualize categorical data and the relative sizes of different categories. Examples of use cases include market share of different products, distribution of budget among different departments, or the breakdown of survey responses by answer choice.
We have five sections and each section have some scores, based on these scores we will draw a pie chart using matplotlib
-
Connectedness
-
Substance
-
Nutrition
-
Recovery
-
Movement


We will see the information on pdf for the sameple data:
-
Profile Information
-
Lifestyle scoring
-
Vitals and Anthropometrics
-
Immunization
-
Appointments
from API's response we can save an create a PDF file. Here is the sample response pdf file created with pdf-generator-python
 |
 |
Common errors:
IOError: 'No wkhtmltopdf executable found':
Make sure that you have wkhtmltopdf in your $PATH or set via custom configuration (see preceding section). where wkhtmltopdf in Windows or which wkhtmltopdf on Linux should return actual path to binary.
IOError: 'Command Failed'
This error means that PDFKit was unable to process an input. You can try to directly run a command from error message and see what error caused failure (on some wkhtmltopdf versions this can be cause by segmentation faults)
API Endpoint for to convert the HTML into PDF files and Storing those files into S3bucket and MongoDB database .
Pre-requisities: s3 bucket, IAM credentials & mongodb
make ensure you are inside the project / cloned repository
- pip install -r .requirements.txt
- python manage.py makemigrations.py
- python manage.py migrate
- python manage.py runserver
After successfully running the local host
go to http://127.0.0.1:8000/pdf/gen/ this url.
upload your HTML file and then you got response be like this:
{"url":<s3bucket url>}
