[css-text] shaping breaks and typographic characters #699
Comments
|
Hi Richard, Let me know if this seems acceptable or if there are specific changes to the spec you think are necessary. |
|
I assume you mean
This doesn't really help for my use case. Suppose you want to colour the diacritic red in "é". Afaict, there is no guarrantee i'd be able to do it given the non-committal text in the spec, and therefore the use case produces non-interoperable results across browsers (as you say in the second sentence). I see that as a significant problem, because for educational texts you often want to do that kind of thing (not just for accents, but for parts of all kinds of elements of a grapheme cluster in other scripts). I'd rather see text that says that UAs should seek to maintain the positioning of the glyphs involved in a typographic unit, regardless of where the element boundaries are. |
There is not guarantee you can do that, since a font might decide to produce that shape using one glyph instead of two. |
|
Then it would presumably be obvious straight away that it wasn't working, and i could use a different font. Whereas with the current approach it might look fine in my normal browser, but not as intended in anyone else's, which is why i think is a case for standardisation. |
Unless you are using a webfont, the same variety happens across browsers and OSes. I'm afraid which shape in the font is used also varies across the browsers. HarfBuzz for example prefers NFC forms: harfbuzz/harfbuzz#653 |
Indeed it does, but content authors would be indeed be well advised to use a webfont if they are doing this kind of thing, anyway. |
|
I have to agree with @behdad here. If you want to style a combining mark differently than its base character, you’re going to have a bad time because of Unicode normalization, the |
|
It should be possible, I think, to use CGJ to prevent normalization. This works in Firefox; the first mark is not colored because of the normalization, but the second is colored, and both are correctly positioned, but in Chrome though the mark is always colored, its position is off: <html>
<body>
<p style="font-size: 100pt">
w<span style="color: red">̀</span>
w<span style="color: red">͏̀</span>
</p>
</body>
</html>
|


|
@drott Do you know if layoutNG plans to address this? |
For ligatures and certain compounds i understand that this can become difficult, but i don't want to close out the possibility of allowing mark highlighting where it can be useful. Sure, there are things that are more difficult, and my assumption is that content authors are not likely to try mark colouring in those situations. But highlighting signs as shown here for devanagari is not an extraordinary ask, and should continue to be feasible, given an appropriate font:
Basically, i want to avoid throwing out the baby with the bath water. |


This is already fixed in LayoutNG, though mark is in black in both cases. |
I think this is because Chrome uses the default HarfBuzz cluster level, which merges combining marks with the cluster of their base glyphs. Firefox uses cluster level 1 specifically for that (https://bugzilla.mozilla.org/show_bug.cgi?id=729993). |
|
@khaledhosny thank you for the info, I'll look into it. |
|
BTW, the right one is slightly shifted: I think I tend to agree with @behdad and @litherum here. @r12a's concern is understandable, and agree all impls should try to support it, but unsure if this can really be standardized given many variables and dependency to the used fonts. |
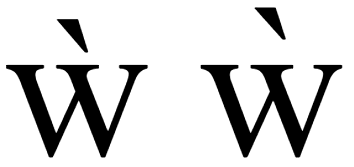
|
Edge: |
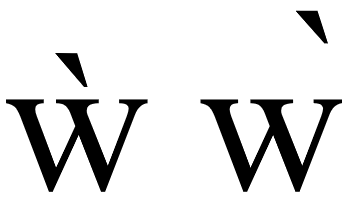
|
I think Arabic or Devanagari are better example here since no Unicode composition should be involved and the positioning should be the same with or without colors (browser bug notwithstanding). |
|
Yes, it looks like Edge is positioning the diacritic incorrectly here. It's a tough problem, it's difficult to decide if a format change allows or prevents composing across glyph boundaries. Color-only changes could work, but it seems like one more additional check that has to be done accross every inline boundary. We are not opposed to fixing this issue though, let's keep investigating what it would take to fix in our respective engines. |
I agree, but that implies that this is not an item to standardize, because if we standardize, authors would expect it to work without knowing what Unicode composition is. I think that is the point @behdad and @litherum pointed out. Still happy to keep discussing requirements, and I think all impls try to improve where technically possible is a good thing. I filed Blink tracking bug at crbug.com/905603. A question remains. If it's not reliable, what authors can do. I think one option is to always use web font as suggested before. The other is to use graphics instead, such as SVG, though it may not be possible depends on use cases. When I discussed similar requirements for East Asian in EPUB, mostly in educational (ex1 ex2), it was so impossible that it was easy to conclude this must be a graphics. Arabic or Devanagari are probably possible given the current font implementations, so they could have a choice. |
…ile maintaining that this may not always be possible. #699
@fantasai until we find a way forward from where we currently are, i think that it's helpful, thanks. As @FremyCompany mentioned above, i suspect that this is probably only an issue for colour (although fixing things for colour would be quite useful).
On the other hand, there are SE Asian scripts, such as Tai Tham and Javanese, that tend to begin new words inside a stack. If you wanted to apply an underline to a particular word in that case (and maybe they don't use underlining, for this reason?) you might want to underline the stack containing the beginning of the word while actually only putting the span around the word itself.(?) But there are a lot of unknowns there wrt typographic requirements. Anyway, fwiw, i wrote an interactive, exploratory test page at Since Chrome & Safari currently separate characters with an element boundary between them, and Edge's behaviour is a little obscure, Firefox is perhaps the most interesting browser to try this in. I provided some sample text, but you can type in whatever you want. (The samples are quickly thrown together combinations that are common in various scripts.) Some observations include:
|
|
OK, closing out the issue then. |
|
Hold on, I didn't say i was satisfied. I did say that this is probably only related to colour, and i did say that the text you added is useful in the interim. I'd still like to be able to do some sub-grapheme-cluster highlighting of characters, if possible, in a way that works across browsers. (And I agree that the content author would need to use and serve a particular font to get reliable results.) I'm not super-confident that we'll find a way to make it happen, but it didn't seem to me that the discussion had quite run aground as yet, and the interactive test was designed to help clarify thoughts around it. If you're trying to get rid of this issue so that you can publish css-text, it may be appropriate to defer this to level 4, but i prefer not to close until i've been convinced that this is really never going to be achievable, since it would be a really useful feature. |
|
The current spec text says it should work if the implementation can manage to pull it off, as you requested. It is not technically possible in many cases such as if the font maps a single glyph to the grapheme cluster, therefore we can't require it. I don't see that there's anything more that the CSS spec can say on this matter. |
|
@r12a: I'd be hesitant to say that Tai Tham joins words within a stack - the joins are either like English contractions as in "So've I" or combinations of alliterating words which arguably form a single lexeme. There's the interesting case of Sanskrit, and to a lesser extent Pali, where words begin within an indecomposable Unicode character, never mind stack. However, note the similar behaviour with quadrates in Egyptian hieroglyphics, which tend not to respect word boundaries. When a word is to be emphasised by a cartouche, the quadrate structure suddenly respects the word boundaries so that the quadrate and cartouche boundaries do not conflict. Historically, the Devanagari half-forms are weird. Historically, the 'invisible' virama belongs rather with the following character, as with the Tibetan subscript consonants, and is manifest in the scripts for which virama+consonant has an alternative form, generally with a distinct usage pattern, which is encoded as an indivisible subscript consonant. When C1 half-forms are not used, I do not believe the formal grapheme cluster boundary corresponds to anything in the Unicode-unaware user's mind. |
|
Fwiw, here's a font development group which produces Unicode-based educational fonts in Khmer, but is resorting to remapping the Khmer characters onto the Latin area so that it can colour sub-grapheme level components :( https://github.com/OpenInstituteCambodia/open-khmer-school#highlight-non-unicode
I was referred to this by someone else who had also been thinking along these lines.... |
|
Another method is to use features to select colour glyphs, e.g. a feature to colour preposed vowels red, a feature to colour them green, and yet another a feature to colour postposed vowels red. This is supported by several browsers. |
|
Just to be clear, i see the solution using the Latin area as a Very Bad Idea. @Richard57 what type of features? How does one select them? |
|
The features would be bespoke OpenType font-specific features, such as cv01 or ss01. As with the example, one needs a special font. For example, I use the style definition It so happens that feature ss02 uses the privileges of Latin to convert and shape an ASCII hack to a complex script totally unsupported by IE 11 (last time I looked), but that is irrelevant to the issue of colouring text. I don't need to select any features when I use Da Lekh Si with a competent-enough renderer and the default language suffices. |
|
@r12a We're waiting on your confirmation to be able to close this issue. Can you please confirm that this is now ok, or if it is not, say what you wish to see changed? In your comment #699 (comment), you say you'd like to be able to do sub-grapheme cluster styling. As @fantasai pointed out, the spec text leaves that possibility open (and encourages it), but falls short of requiring it because as far as we can tell in the general case it is not possible. Fonts can map a group of code points to a single glyph, and there's nothing that can be done in that case to style part of the glyph. Moreover, css is largely independent of the font technology used, so this is not a good spec to assume that certain things can be done just because they are possible in open type. I don't disagree that the various things you wish to achieve are desirable, but if we want to elevate the requirement to a MUST, we're going to need to:
This seems like it would be a significant expansion of scope for css-text Level 3 to cope with this, and we're trying to wrap it up, so I'd rather keep the spec as it is for now (i.e. allowing and recommending but not requiring the behavior you want), and leaving it up to future levels / modules to define the details so that this becomes interoperable in the cases where it is possible to do so. |
|
Ok. Thanks for the helpful discussion. |
|
I just wanted to point out that Word has this feature, under Settings > Advanced > Show document content, so it's not entirely unreasonable request:
(works on combining diacritics only)
Maybe there could be a css property for diacritics color? |


{kind=link}
{kind=link}
|
Fwiw, the i18n WG has closed its tracker for this issue. Thank you. |
|
However, the Word behaviour seems to hint at a problem. Is it canonically normalising the text before applying colour, or does it just give you a hint of what's in the backing store? It may actually be useful to tell the typist how much backspace will delete. At least on the version of Word I'm using, it takes two backspaces to delete i-with-acute if it's two characters, and one backspace if it's one character. I sometimes want to replace diacritics even in the Latin script. |
8.3. Shaping Across Element Boundaries
https://drafts.csswg.org/css-text/#boundary-shaping
i'm not clear how typographic units are relevant here – in fact, i think it may be incorrect to invoke them. Apart from the fact that what constitutes a typographic unit is particularly vague here, i think that actually we just want to say "for any box whose boundary separates two characters", where character refers to Unicode code points. For example, these rules should presumably apply to diacritics (it is a common use case to want to colour diacritics or accents differently from a base character), or a part of a grapheme cluster.
(See the tests at https://www.w3.org/International/tests/repo/results/css-text-shaping.en.html#diacritics for examples that actually show browsers applying the same behaviour to diacritics as to normal letters.)
The text was updated successfully, but these errors were encountered: