A collection of examples using Apache Flink™'s new python API. To set up your local environment with the latest Flink build, see the guide:
- HERE.
The examples here use the v0.10.0 python API, and are meant to serve as demonstrations of simple use cases. Currently the python API supports a portion of the DataSet API, which has a similar functionality to Spark, from the user's perspective.
To run the examples, I've included a runner script at the top level with methods for each example, simply add in the path to your pyflink script and you should be good to go (as long as you have a flink cluster running locally).
The currently included examples are:
A listing of the examples and their resultant flink plans are included here.
An extremely simple analysis program uses a source from a simple string, counts the occurrences of each word and outputs to a file on disk (using the overwrite functionality).

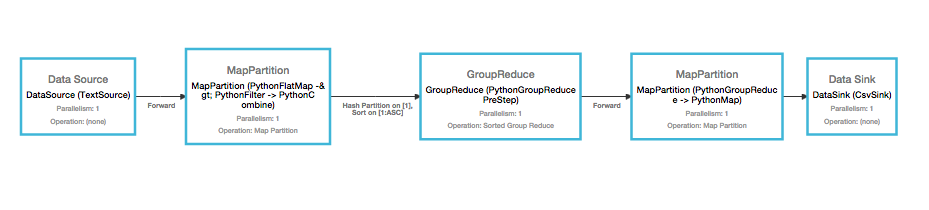
A very similar example to word count, but includes a filter step to only include hashtags, and different source/sinks. The input data in this case is read off of disk, and the output is written as a csv. The file is generated dynamically at run time, so you can play with different volumes of tweets to get an idea of Flink's scalability and performance.
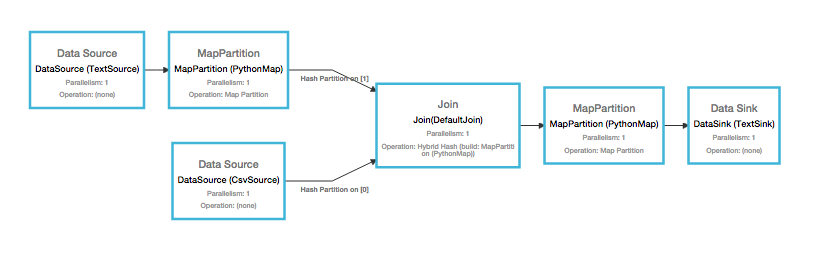
In this example, we have row-wise json in one file, with an attribute field that refers to a csv dimension table with colors. So we load both datasets in, convert the json data into a ordered and typed tuple, and join then two together to get a nice dataset of cars and their colors.
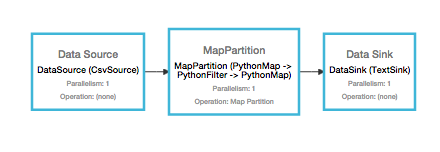
Takes in a csv with two columns and finds the mean of each column, using a custom reducer function. Afterwards, it formats a string nicely with the output and dumps that onto disk.

Creates a Mandelbrot set from a set of candidates. Inspired by this post
A quick listing of high level features, and the examples that include them
- trending hashtags
- data enrichment
- data enrichment
- mean values
- mandelbrot
- word count
- word count
- data enrichment
- mean values
- mandelbrot
- trending hashtags
- word count
- trending hashtags
- data enrichment
- mean values
- mandelbrot
- word count
- trending hashtags
- trending hashtags
- mandelbrot
- mean values
- word count
- trending hashtags
- data enrichment
As we go through the process of making these examples in an extremely young library, we run across quirks, that we will mention here, and if appropriate report as bugs (we will take these down once they are fixed if they are bugs).
There is a tendency to want to write code without hard-coded paths. So we may include the path to the output file in the word count example as:
import os
output_path = os.path.dirname(os.path.abspath(__file__)) + os.sep + 'output_file.txt'
But this doesn't seem to work, because some part of how pyflink is executing the python code moves it, so the abspath term evaluates to some temp directory.
Apache®, Apache Flink™, Flink™, and the Apache feather logo are trademarks of The Apache Software Foundation.