在实现文字过滤的算法中,DFA是唯一比较好的实现算法。
DFA 全称为:Deterministic Finite Automaton,即确定有穷自动机。其特征为:有一个有限状态集合和一些从一个状态通向另一个状态的边,每条边上标记有一个符号,其中一个状态是初态,某些状态是终态。但不同于不确定的有限自动机,DFA 中不会有从同一状态出发的两条边标志有相同的符号。
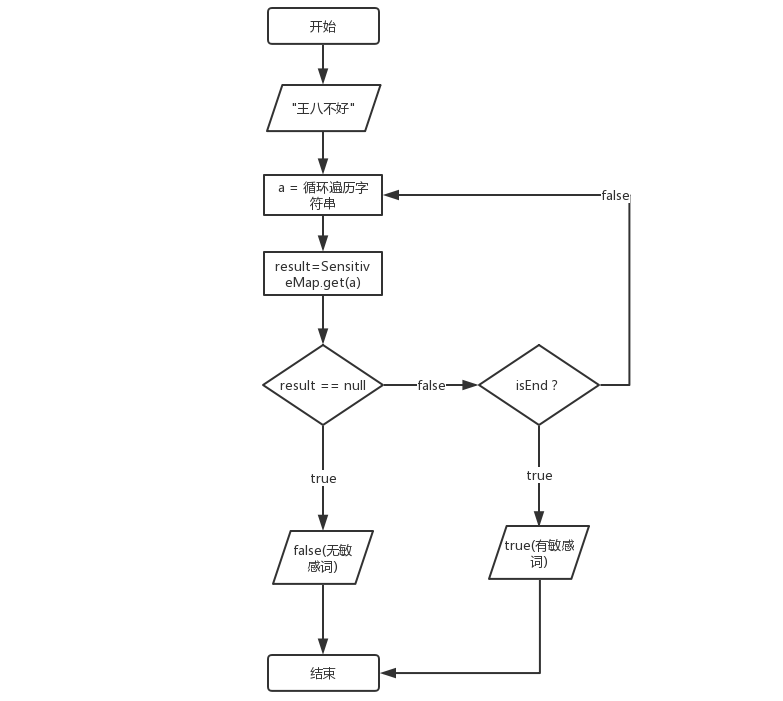
- 敏感词库构造 以王八蛋和王八羔子两个敏感词来进行描述,首先构建敏感词库,该词库名称为SensitiveMap,这两个词的二叉树构造为:

用 hash 表构造为:
{
"王":{
"isEnd":"0",
"八":{
"羔":{
"子":{
"isEnd":"1"
},
"isEnd":"0"
},
"isEnd":"0",
"蛋":{
"isEnd":"1"
}
}
}
}- 敏感词过滤 以上面例子构造出来的 SensitiveMap 为敏感词库进行示意,假设这里输入的关键字为:王八不好,流程图如下:
对于“王*八&&蛋”这样的词,中间填充了无意义的字符来混淆,在我们做敏感词搜索时,同样应该做一个无意义词的过滤,当循环到这类无意义的字符时进行跳过,避免干扰。