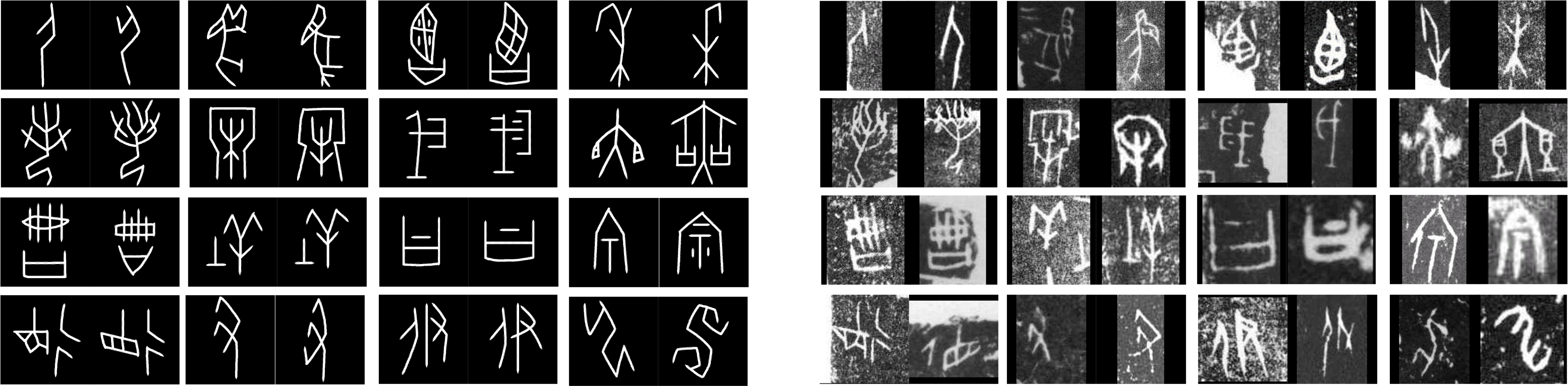
Oracle bone script is the earliest-known Chinese writing system of the Shang dynasty and is precious to archeology and philology. However, real-world scanned oracle data are rare and few experts are available for annotation which make the automatic recognition of scanned oracle characters become a challenging task. Therefore, we aim to explore unsupervised domain adaptation to transfer knowledge from handprinted oracle data, which are easy to acquire, to scanned domain. A publicly available oracle character database Oracle-241 is presented, and a structure-texture separation network (STSN) is proposed.
Oracle-241 is a large oracle character dataset for transferring recognition knowledge from handprinted characters to scanned data. It contains 78,565 handprinted and scanned characters of 241 categories. To be able to objectively measure the performance, the database has been split into training set and test set:
| Subsets | Train | Train | Test | Test |
|---|---|---|---|---|
| #Classes | #Images | #Classes | #Images | |
| handprint | 241 | 10,861 | 241 | 3,730 |
| scan | 241 | 50,168 | 241 | 13,806 |
This database is publicly available. It is free for professors and researcher scientists affiliated to a University.
Send an e-mail to Mei Wang (wangmei1@bnu.edu.cn) before downloading the database. You will need a password to access the files of this database. Your Email MUST be set from a valid University account and MUST include the following text:
Subject: Application to download the Oracle-241 Database
Name: <your first and last name>
Affiliation: <University where you work>
Department: <your department>
Position: <your job title>
Email: <must be the email at the above mentioned institution>Software environment:
- Ubuntu 16.04 x64
- Python 3.8.8
- PyTorch 1.5.0+cu101
How to train it?
Once Oracle-241 is prepared, you need to put it in the file data, then you are ready to go by running:
ResNet18:
python train_base.py --gpu 0 --transfer 0DANN:
python train_base.py --gpu 0 --transfer 1 --method DANNCDAN:
python train_base.py --gpu 0 --transfer 1STSN:
python STSN.py --gpu 0 --gen_img_dir generate_img/STSN --num_steps 250000 --batch_size 16@article {wang2022oracle,
author={Wang, Mei and Deng, Weihong and Liu, Cheng-Lin},
journal={IEEE Transactions on Image Processing},
title={Unsupervised Structure-Texture Separation Network for Oracle Character Recognition},
year={2022},
volume={31},
number={},
pages={3137-3150},
doi={10.1109/TIP.2022.3165989}
}