xe-crawler 是遵循声明式、可监测理念的分布式爬虫,其计划提供 Node.js、Go、Python 多种实现,能够对于静态 Web 页面、动态 Web 页面、关系型数据库、操作系统等异构多源数据进行抓取。xe-crawler 希望让使用者专注于领域逻辑而不用考虑调度、监控等问题,并且稍加改造就能用于系统监控、ETL 数据迁移等领域。更多的 xe-crawler 设计思想、设计规范参考爬虫实战 https://url.wx-coder.cn/3gyS2。
-
cendertron 提供了基于 Node.js 的 Puppetter 独立爬虫包装,内置了动作模拟、URL 去重、界面表单与请求提取等特性。
-
基于 Node.js 的声明式可监控爬虫网络初探:本文是最早的设计思想与用例概述,其中使用的部分用例已经废弃,可以阅读了解下笔者的原始设计思想。
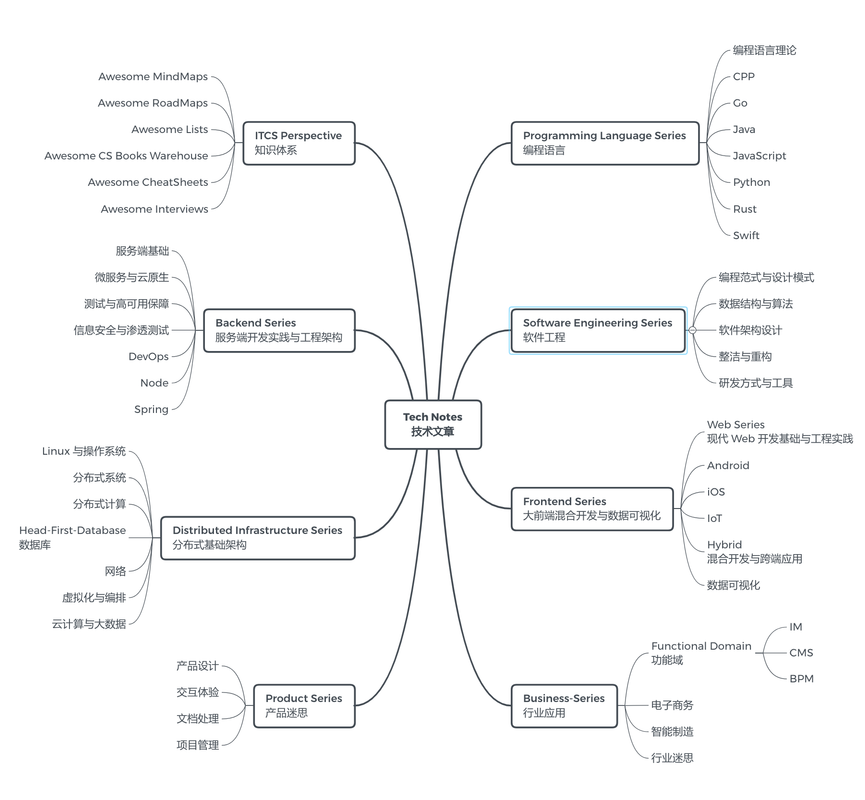
您可以通过以下导航来在 Gitbook 中阅读笔者的系列文章,涵盖了技术资料归纳、编程语言与理论、Web 与大前端、服务端开发与基础架构、云计算与大数据、数据科学与人工智能、产品设计等多个领域:
-
知识体系:《Awesome Lists》、《Awesome CheatSheets》、《Awesome Interviews》、《Awesome RoadMaps》、《Awesome MindMaps》、《Awesome-CS-Books-Warehouse》
-
编程语言:《编程语言理论》、《Java 实战》、《JavaScript 实战》、《Go 实战》、《Python 实战》、《Rust 实战》
-
Web 与大前端:《现代 Web 开发基础与工程实践》、《数据可视化》、《iOS》、《Android》、《混合开发与跨端应用》
-
服务端开发实践与工程架构:《服务端基础》、《微服务与云原生》、《测试与高可用保障》、《DevOps》、《Node》、《Spring》、《信息安全与渗透测试》
-
分布式基础架构:《分布式系统》、《分布式计算》、《数据库》、《网络》、《虚拟化与编排》、《云计算与大数据》、《Linux 与操作系统》
-
数据科学,人工智能与深度学习:《数理统计》、《数据分析》、《机器学习》、《深度学习》、《自然语言处理》、《工具与工程化》、《行业应用》
此外,前往 xCompass 交互式地检索、查找需要的文章/链接/书籍/课程;或者在在 MATRIX 文章与代码索引矩阵中查看文章与项目源代码等更详细的目录导航信息。最后,你也可以关注微信公众号:『某熊的技术之路』以获取最新资讯。
- annie: A fast, simple and clean video downloader
-
2015-go_spider #Project#: An awesome Go concurrent Crawler(spider) framework. The crawler is flexible and modular. It can be expanded to an Individualized crawler easily or you can use the default crawl components only.
-
2018-Muffet #Project#: Muffet is a website link checker which scrapes and inspects all pages in a website recursively.
-
2018-ferret #Project#: ferret is a web scraping system aiming to simplify data extraction from the web for such things like UI testing, machine learning and analytics.
-
2019-TopList #Project#: 今日热榜,一个获取各大热门网站热门头条的聚合网站,使用Go语言编写,多协程异步快速抓取信息