基于词频密度过滤、利用百度、谷歌、搜搜、360搜索4个引擎为种子来源的多线程爬虫,结果存入mysql。用到了jsoup和webclient。
最近比较贪玩儿,冒着笔试可能挂的危险又把这个东东更新了下,现在它可以作为人肉某人的工具了,你可以试试拿这东东搜下你的网名或者你做过的没啥名气的项目,反正我试了,比如我做的一些垃圾东东真能爬出来
- 更新****
2014年3月27日20:30:32
1.新增了搜索语句功能,可以像使用肚熊啊、谷歌啊那样用各种限制 比如

就相当于在所有搜索引擎里输入 site:…… 语法进行搜索,根据上面输入的关键词进行评分。当然,不输入搜索语句,则用关键词在搜索引擎中搜索。
2.可以自己附加种子链接,如果你觉得这四个引擎不咋靠谱的话……
3.增加了一些HTTP头信息,但是如果爬的流量太多,人家非说你是爬虫,非让你输入验证码,那我也没辙了
4.可以多层的爬(适合人肉非常难找的资源) ,如果是很常见的资源建议不要开这个功能。
代码需要重构一下,冗余的东东有些多,不够精简
- 原理****
1. 过滤算法
过滤关联度不大的网址,避免爬虫盲目搜索。目前只用到词频密度对网址和域名进行打分,在任务堆积较多(超过总队列长度90%)时,过滤掉相对评价分数小的网址。打算下一步得到关键词在全文的分布向量,用熵权系数法来比较各个关键词的分布情况,进一步优化过滤算法。原理和把纸撕成碎片然后对边缘进行拼合求关联度一样,关键词分布就像纸片的边缘,可以当做特征向量来求两两之间的商权系数,判断各关键词之间存在什么关系。(不过目前用词频密度过滤结果还算不错,大家可以试试看)
2. 整体结构
分为引擎搜索线程、爬虫线程和垃圾回收线程、数据库模块和任务队列4部分。这里自己画了个大致的结构图,如下:
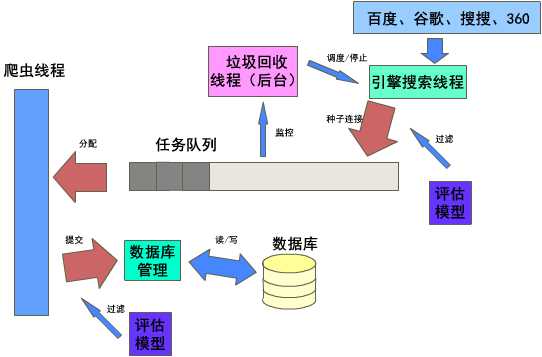
引擎搜索线程采用单例模式,可以利用上述4中搜索引擎输入关键字得到结果,并将结果以一种特殊的数据结构放入任务队列中。引擎搜索线程用于获得爬虫种子,它受垃圾回收线程的控制。在队列任务不多的情况下利用site:host语句在各个引擎中搜索模型中host评分最高的网址,获得关联度更强的种子供爬虫使用。
爬虫线程的数量是可修改的(下一步打算结合内存和算法让其数量动态变化)。它们不断向任务队列里申请任务,得到分配后爬取网页,调用过滤算法,将有价值的结果放入队列并调用数据库模块写入数据库。
垃圾回收线程是后台线程,单例模式,时刻监控任务队列的情况,并在任务较多时清理垃圾,任务较少时启动引擎搜索线程获得更多爬虫种子。平时则关闭引擎搜索线程。
数据库模块采用单例模式,我没有用ThreadLocal(因为我的小电脑顶多运行8只爬虫,读写操作没那么频繁)。用同步块来执行读写操作。接受引擎搜索线程和爬虫线程的读写请求。它以host作为分类准则,对连接进行分类处理。不同的host存入不同的表内。
任务队列其实不是队列,它是对TreeSet的改造,还是采用单例模式╮(╯▽╰)╭,存放特殊数据结构的任务,供爬虫们使用。同时它也负责爬虫请求的任务分配。
3. 执行过程
1)调用引擎搜索线程run方法(注意不是start启动)初始化,从4个引擎上得到一定数量的种子
2)分别启动垃圾回收线程和所有爬虫线程,后续线程控制完全归垃圾回收线程控制。当然可以通过暂停按钮让所有线程阻塞。
- 使用方法
启动mysql,输入create database mspider;
启动 com.td1madao.gui.MyFrame 即可启动GUI程序,也可以用 com.td1madao.gui.NoGui命令行启动
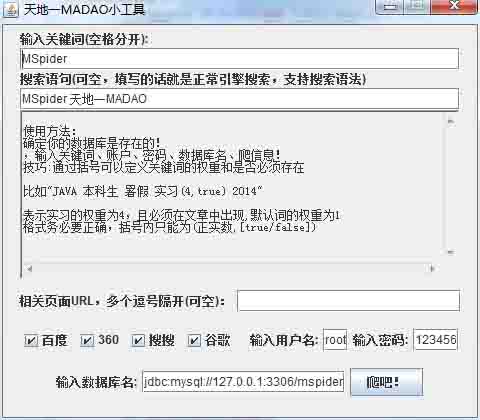
gui效果如图
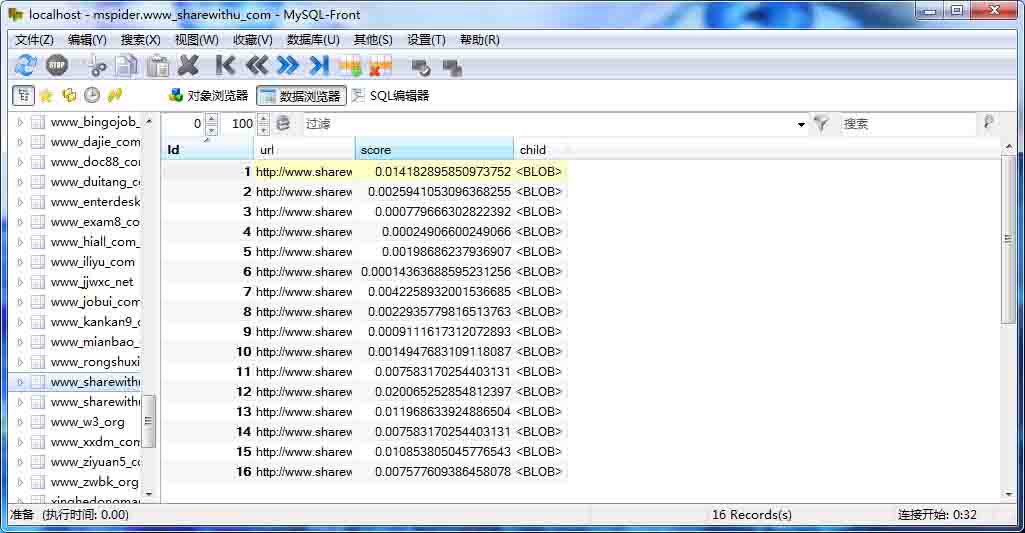
在数据库里的效果如图(这里用MYSQL FRONT显示)
如果觉得功能不够,可以在com.td1madao.global.GlobalVar下修改默认配置,配置里提供了host黑名单、线程数量、算法等级、请求次数、任务队列长度等等,因为我不是很会做GUI,所以就没有在图形界面里实现这些功能。
- 使用技巧
如果想加入一些限制,可以采用如下语法
关键词(权重,是否必须存在)
权重是一个正实数,默认为1,表示这个关键词的重要程度
是否必须存在是一个布尔值,只能为true或false,表示这个关键词是否必须有,如果选true,不含这个关键词的连接会被过滤掉
比如:
JAVA 本科生 暑假 实习(4,true) 2014
那么实习这个词必须出现,且其词频密度权重为其他关键词的4倍(默认为1)。这样优先得到与实习关联强的连接
如果用括号限制,两个值必须都写,不能只写一个,关键词和括号之间不能存在空格!
[将要实现的功能] 如果有时间,打算增加同义词功能,比如:
奇虎/360/安全卫士(1,true) JAVA 后台
这样可以把 奇虎、360、安全卫士多个词当做同义词进行算法分析,搜索时类似搜索引擎的'OR'语法,但在算法实现上有点困难,有时间我会补充上。因为涉及到编译原理词法分析和语法分析的知识,稍微有点难做。
这只大爬虫的完全是出自个人的兴趣,程序结构、模型设计,算法设计和代码实现均个人完成,有的地方代码还不是很规范,很多设计模式也没有灵活运用上,希望大家不要笑话我o(╯□╰)o